هر شب فرآیند حذف دادههای قدیمی ساعتها طول میکشد، عملیات نگهداری ایندکسها به پنجره زمانی Maintenance نمیرسد و اجرای برخی گزارشها نسبت به گذشته بهطور محسوسی کندتر شده است. در جلسه بررسی Performance، یکی از اعضای تیم پیشنهاد میدهد:
«بیایید از SQL Server Partitioning استفاده کنیم؛ این کار همه مشکلات را حل میکند.»
این پیشنهاد در نگاه اول منطقی به نظر میرسد، زیرا SQL Server Partitioning یکی از شناختهشدهترین قابلیتهای SQL Server برای مدیریت جداول بزرگ است. اما آیا واقعاً با فعال کردن Partitioning، عملکرد پایگاه داده بهصورت خودکار بهبود پیدا میکند؟
پاسخ کوتاه این است: همیشه خیر.
یکی از رایجترین اشتباهات در میان مدیران پایگاه داده و حتی برخی توسعهدهندگان این است که Partitioning را معادل افزایش Performance میدانند. در حالی که اگر این قابلیت بدون شناخت صحیح از نحوه عملکرد Query Optimizer، الگوی دسترسی به دادهها و ساختار ایندکسها پیادهسازی شود، نهتنها سودی نخواهد داشت، بلکه میتواند پیچیدگی مدیریت پایگاه داده را نیز افزایش دهد.
واقعیت این است که SQL Server Partitioning برای حل یک مسئله مشخص طراحی شده است؛ مدیریت کارآمد جداول بسیار بزرگ (Very Large Tables یا VLDB)، سادهسازی عملیات نگهداری و بهینهسازی برخی سناریوهای پردازش داده. بنابراین، موفقیت آن بیش از هر چیز به شناخت صحیح مسئله و طراحی اصولی وابسته است.
SQL Server Partitioning چیست؟
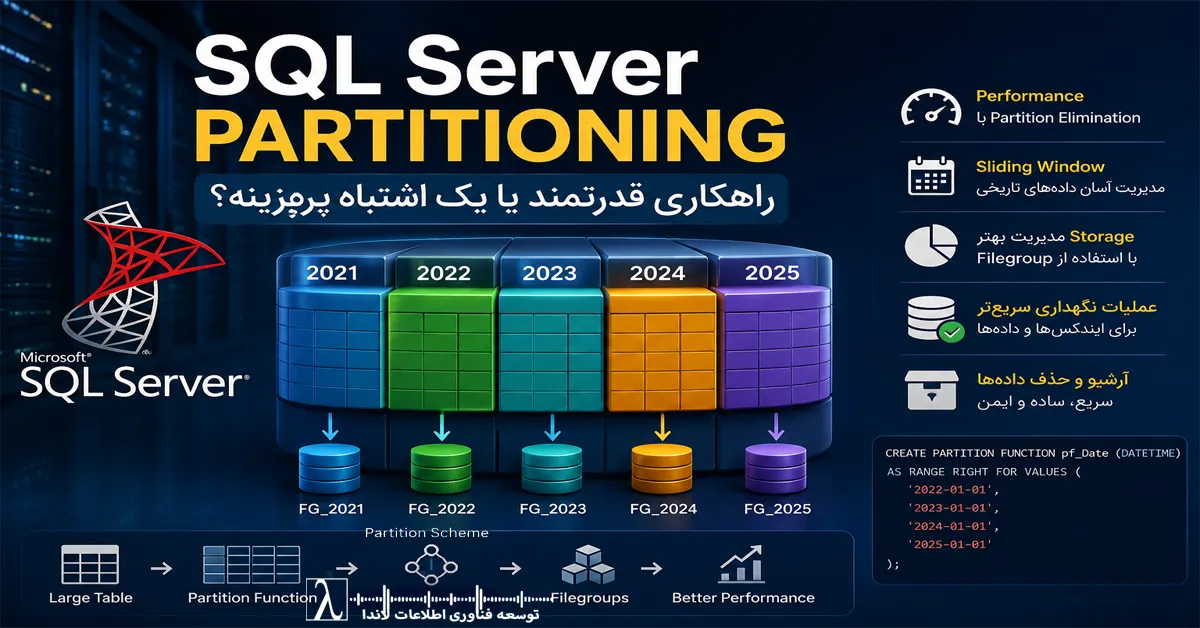
Partitioning قابلیتی در SQL Server است که یک جدول یا ایندکس بسیار بزرگ را به چند بخش منطقی (Partition) تقسیم میکند، بدون آنکه از دید برنامه یا کاربران، جدول به چند جدول مستقل تبدیل شود.
به بیان سادهتر، دادهها همچنان در قالب یک جدول واحد قابل مشاهده هستند، اما SQL Server آنها را براساس یک قانون مشخص در چند پارتیشن مجزا ذخیره و مدیریت میکند.
برای مثال، فرض کنید جدول فروش یک سازمان شامل اطلاعات ده سال گذشته باشد. بهجای ذخیره تمام رکوردها در یک فضای واحد، میتوان دادهها را براساس سال یا ماه در پارتیشنهای جداگانه قرار داد.
نمونهای از این تقسیمبندی میتواند به شکل زیر باشد:
- پارتیشن اول: اطلاعات سال ۲۰۲۲
- پارتیشن دوم: اطلاعات سال ۲۰۲۳
- پارتیشن سوم: اطلاعات سال ۲۰۲۴
- پارتیشن چهارم: اطلاعات سال ۲۰۲۵
- پارتیشن پنجم: اطلاعات سال ۲۰۲۶
در این حالت، برنامه همچنان با یک جدول کار میکند، اما SQL Server مدیریت دادهها را در سطح پارتیشن انجام میدهد.
چرا Partitioning به SQL Server اضافه شد؟
در پایگاههای داده کوچک، نگهداری اطلاعات معمولاً چالش بزرگی ایجاد نمیکند. اما زمانی که حجم دادهها به صدها میلیون یا میلیاردها رکورد میرسد، عملیات سادهای مانند حذف دادههای قدیمی، بازسازی ایندکسها یا تهیه نسخه پشتیبان میتواند به فرآیندی زمانبر و پرهزینه تبدیل شود.
Partitioning برای پاسخ به همین چالشها توسعه یافته است.
این قابلیت به مدیران پایگاه داده کمک میکند:
- مدیریت جداول بسیار بزرگ را سادهتر کنند.
- عملیات نگهداری را روی بخشی از دادهها انجام دهند.
- آرشیو اطلاعات قدیمی را با سرعت بیشتری انجام دهند.
- زمان توقف عملیات نگهداری را کاهش دهند.
- برخی Queryها را با استفاده از Partition Elimination بهینهتر اجرا کنند.
نکته مهم این است که هدف اصلی Partitioning، مدیریت داده است و نه صرفاً افزایش سرعت اجرای Queryها.
Partition چگونه کار میکند؟
هر پارتیشن مجموعهای از رکوردها را براساس مقدار یک ستون مشخص نگهداری میکند. این ستون معمولاً Partition Key نامیده میشود.
انتخاب Partition Key یکی از مهمترین تصمیمات در طراحی این معماری است، زیرا تمام فرآیند تقسیم دادهها بر اساس آن انجام میشود.
رایجترین ستونهایی که بهعنوان Partition Key انتخاب میشوند عبارتاند از:
- تاریخ ثبت اطلاعات
- تاریخ تراکنش
- شناسه زمانی
- سال مالی
- شناسه منطقه جغرافیایی
اگر این ستون بهدرستی انتخاب نشود، بسیاری از مزایای Partitioning از بین خواهد رفت.
Partition Function چیست؟
اولین جزء اصلی Partitioning تابع Partition Function است.
Partition Function مشخص میکند هر بازه از دادهها در کدام پارتیشن قرار بگیرد.
بهعنوان مثال، اگر تصمیم بگیرید دادهها براساس سال ذخیره شوند، Partition Function مرز میان سالهای مختلف را تعریف میکند.
در واقع، این بخش مانند یک نقشه عمل میکند که مشخص میسازد هر رکورد به کدام پارتیشن تعلق دارد.
تفاوت RANGE LEFT و RANGE RIGHT در SQL Server Partitioning
هنگام ایجاد Partition Function در SQL Server، تنها تعیین مقادیر مرزی (Boundary Values) کافی نیست؛ بلکه باید مشخص کنید این مقادیر مرزی به کدام پارتیشن تعلق داشته باشند. این رفتار با استفاده از دو گزینه RANGE LEFT و RANGE RIGHT تعیین میشود.
اگرچه تفاوت این دو گزینه در نگاه اول بسیار جزئی به نظر میرسد، اما انتخاب نادرست آنها میتواند باعث قرار گرفتن دادهها در پارتیشنهای غیرمنتظره شود و مدیریت اطلاعات را در آینده پیچیدهتر کند.
RANGE LEFT چگونه عمل میکند؟
در حالت RANGE LEFT، مقدار مرزی جزئی از پارتیشن سمت چپ محسوب میشود.
برای مثال، اگر Partition Function بهصورت زیر تعریف شده باشد:
CREATE PARTITION FUNCTION pf_OrderDate (DATE)
AS RANGE LEFT
FOR VALUES ('2025-01-01');در این حالت:
- تمام تاریخهای کوچکتر یا مساوی
2025-01-01در پارتیشن اول قرار میگیرند. - تاریخهای بزرگتر از این مقدار وارد پارتیشن بعدی میشوند.
به بیان ساده:
| تاریخ | پارتیشن |
|---|---|
| 2024-12-31 | اول |
| 2025-01-01 | اول ✅ |
| 2025-01-02 | دوم |
RANGE RIGHT چگونه عمل میکند؟
در مقابل، در حالت RANGE RIGHT، مقدار مرزی متعلق به پارتیشن سمت راست است.
اگر همان Partition Function به شکل زیر تعریف شود:
CREATE PARTITION FUNCTION pf_OrderDate (DATE)
AS RANGE RIGHT
FOR VALUES ('2025-01-01');نتیجه متفاوت خواهد بود:
- تاریخهای کوچکتر از
2025-01-01در پارتیشن اول قرار میگیرند. - مقدار
2025-01-01و تمام مقادیر بزرگتر در پارتیشن دوم ذخیره میشوند.
برای مثال:
| تاریخ | پارتیشن |
|---|---|
| 2024-12-31 | اول |
| 2025-01-01 | دوم ✅ |
| 2025-01-02 | دوم |

در پروژههای واقعی کدام گزینه بهتر است؟
هیچکدام ذاتاً بر دیگری برتری ندارند و انتخاب آنها به منطق کسبوکار و نحوه تقسیمبندی دادهها بستگی دارد.
با این حال، در بسیاری از سیستمهای سازمانی که دادهها بر اساس تاریخ پارتیشنبندی میشوند، RANGE RIGHT انتخاب رایجتری است. در این حالت، اولین روز هر ماه یا سال مستقیماً در پارتیشن همان بازه زمانی قرار میگیرد و پیادهسازی سناریوهایی مانند Sliding Window نیز سادهتر خواهد بود.
نکته مهم:
پیش از ایجاد Partition Function، همیشه نحوه قرارگیری مقادیر مرزی را روی یک محیط آزمایشی بررسی کنید. بسیاری از مشکلاتی که DBAها در پیادهسازی SQL Server Partitioning با آن مواجه میشوند، نه به دلیل خود Partitioning، بلکه به علت انتخاب نادرست میان RANGE LEFT و RANGE RIGHT است.
Partition Scheme چیست؟
پس از تعریف Partition Function، باید مشخص شود هر پارتیشن در کدام Filegroup ذخیره شود.
این وظیفه بر عهده Partition Scheme است.
Partition Scheme میان Partition Function و Filegroupهای SQL Server ارتباط برقرار میکند و تعیین میکند هر بخش از دادهها در چه محل فیزیکی ذخیره شود.
به همین دلیل، این دو مفهوم همیشه در کنار یکدیگر مورد استفاده قرار میگیرند.
تفاوت Partitioning و Sharding
یکی از اشتباهات رایج، یکسان دانستن Partitioning و Sharding است.
در حالی که این دو مفهوم اهداف متفاوتی دارند.
در Partitioning، تمام دادهها همچنان در یک پایگاه داده و یک جدول منطقی قرار دارند و SQL Server مدیریت داخلی پارتیشنها را انجام میدهد.
اما در Sharding، دادهها میان چند پایگاه داده یا حتی چند سرور مختلف توزیع میشوند و مسئولیت مدیریت این توزیع معمولاً بر عهده معماری نرمافزار یا لایه میانی است.
به همین دلیل، Partitioning بیشتر راهکاری برای مدیریت داده درون یک پایگاه داده محسوب میشود، در حالی که Sharding برای مقیاسپذیری توزیعشده در ابعاد بسیار بزرگ طراحی شده است.
آیا هر جدولی باید Partition شود؟
پاسخ کاملاً منفی است.
این یکی از بزرگترین سوءبرداشتها در دنیای SQL Server است.
بسیاری از جداول حتی با وجود چند میلیون رکورد نیز هیچ نیازی به Partitioning ندارند و استفاده از آن تنها پیچیدگی طراحی و نگهداری را افزایش میدهد.
پیش از تصمیمگیری باید به سؤالاتی مانند موارد زیر پاسخ دهید:
- آیا حجم جدول واقعاً بسیار زیاد است؟
- آیا دادهها بر اساس زمان رشد میکنند؟
- آیا حذف یا آرشیو دورهای دادهها انجام میشود؟
- آیا عملیات نگهداری ایندکسها زمانبر شده است؟
- آیا Queryها میتوانند از Partition Elimination بهره ببرند؟
اگر پاسخ این پرسشها منفی باشد، احتمالاً راهکارهای دیگری مانند طراحی صحیح ایندکسها، بازنویسی Queryها یا بهینهسازی Execution Plan تأثیر بیشتری نسبت به Partitioning خواهند داشت.
آیا SQL Server Partitioning واقعاً Performance را افزایش میدهد؟
این احتمالاً مهمترین سؤالی است که قبل از پیادهسازی Partitioning باید از خود بپرسید.
بسیاری از مدیران پایگاه داده تصور میکنند بهمحض Partition کردن یک جدول، تمام Queryها سریعتر اجرا خواهند شد. اما واقعیت این است که SQL Server Partitioning بهتنهایی تضمینی برای افزایش Performance نیست.
در بسیاری از پروژهها، پس از صرف زمان و هزینه برای پیادهسازی Partitioning، سرعت اجرای Queryها تقریباً بدون تغییر باقی میماند.
چرا که Partitioning برای مدیریت بهتر دادههای حجیم طراحی شده است و تنها در شرایط خاص میتواند باعث بهبود عملکرد Queryها شود.
اگر Queryها نتوانند از قابلیت Partition Elimination استفاده کنند، SQL Server ممکن است همچنان تمام پارتیشنها را بررسی کند و در چنین شرایطی، مزیت قابل توجهی از نظر Performance ایجاد نخواهد شد.
به همین دلیل، موفقیت Partitioning بیش از هر چیز به نحوه طراحی Queryها، انتخاب Partition Key و ساختار ایندکسها بستگی دارد.
Partition Elimination؛ مهمترین مزیت عملکردی Partitioning
یکی از مهمترین قابلیتهای SQL Server Partitioning، Partition Elimination است.
در این حالت، Query Optimizer تشخیص میدهد که برای پاسخ به یک Query، نیازی به بررسی تمام پارتیشنها نیست و تنها پارتیشنهای مرتبط را اسکن میکند.
فرض کنید اطلاعات فروش پنج سال گذشته در پنج پارتیشن مجزا ذخیره شدهاند.
اگر Query فقط دادههای سال ۲۰۲۶ را درخواست کند و شرط جستجو روی همان ستون Partition Key اعمال شده باشد، SQL Server مستقیماً به پارتیشن مربوط به سال ۲۰۲۶ مراجعه خواهد کرد و سایر پارتیشنها را نادیده میگیرد.
این موضوع میتواند باعث کاهش قابل توجه حجم I/O و زمان اجرای Query شود.
اما اگر Query بهگونهای نوشته شود که Query Optimizer نتواند Partition Elimination را انجام دهد، تقریباً تمام مزیت عملکردی Partitioning از بین خواهد رفت.
انتخاب Partition Key؛ مهمترین تصمیم طراحی
بسیاری از مشکلات مربوط به Partitioning از انتخاب نادرست Partition Key آغاز میشوند.
Partition Key باید ویژگیهای زیر را داشته باشد:
- در اکثر Queryها استفاده شود.
- توزیع مناسبی میان دادهها ایجاد کند.
- با الگوی رشد اطلاعات سازگار باشد.
- در عملیات آرشیو و حذف داده نقش داشته باشد.
در اغلب سیستمهای سازمانی، ستونهای زمانی بهترین گزینه هستند.
برای مثال:
- OrderDate
- TransactionDate
- CreatedDate
- InvoiceDate
زیرا اغلب عملیات نگهداری نیز براساس زمان انجام میشوند.
در مقابل، انتخاب ستونهایی که توزیع نامتعادل دارند یا بهندرت در Queryها استفاده میشوند، معمولاً نتیجه مطلوبی ایجاد نمیکند.
Sliding Window، روشی هوشمند برای مدیریت دادههای تاریخی
یکی از مهمترین دلایل استفاده از SQL Server Partitioning، پیادهسازی Sliding Window است.
فرض کنید سیاست نگهداری دادههای سازمان به این صورت باشد:
- نگهداری اطلاعات سه سال اخیر
- انتقال اطلاعات قدیمی به آرشیو
- حذف خودکار دادههای بسیار قدیمی
اگر جدول Partition نشده باشد، حذف میلیونها رکورد ممکن است ساعتها زمان ببرد، حجم زیادی Transaction Log تولید کند و باعث قفل شدن جدول شود.
اما در معماری Partitioning، میتوان کل یک پارتیشن را تنها با چند عملیات مدیریتی از جدول اصلی جدا و به محیط آرشیو منتقل کرد.
این فرآیند نسبت به حذف رکوردها بهصورت سطری، بسیار سریعتر و کمهزینهتر است.
به همین دلیل، Sliding Window یکی از مهمترین کاربردهای Partitioning در سیستمهای Enterprise محسوب میشود.
نقش Filegroupها در Partitioning
یکی دیگر از مزایای مهم SQL Server Partitioning، امکان استفاده از Filegroupهای مختلف است.
در این معماری، هر پارتیشن میتواند روی Filegroup جداگانهای قرار گیرد.
این موضوع مزایای متعددی ایجاد میکند:
- مدیریت سادهتر Storage
- امکان تهیه Backup از Filegroupهای خاص
- بازیابی سریعتر دادهها
- انتقال آسان دادههای آرشیوی
- مدیریت بهتر فضای ذخیرهسازی
البته این قابلیت زمانی ارزشمند خواهد بود که طراحی Filegroupها نیز بهصورت اصولی انجام شده باشد.
Aligned Index؛ موضوعی که نباید نادیده گرفته شود
Partition کردن جدول بهتنهایی کافی نیست.
اگر ایندکسها با ساختار Partition هماهنگ نباشند، بسیاری از مزایای این معماری از بین خواهد رفت.
به همین دلیل، مفهومی به نام Aligned Index مطرح میشود.
در این حالت، ایندکس نیز براساس همان Partition Scheme ایجاد میشود.
مزایای این کار عبارتاند از:
- بازسازی ایندکس هر پارتیشن بهصورت مستقل
- کاهش زمان Maintenance
- کاهش Lockها
- افزایش انعطاف در عملیات نگهداری
در مقابل، استفاده از Non-Aligned Index در بسیاری از سناریوها میتواند پیچیدگی مدیریت را افزایش دهد.
آیا Maintenance نیز سریعتر میشود؟
در بسیاری از سیستمهای بزرگ، پاسخ مثبت است.
یکی از مهمترین مزایای Partitioning این است که بسیاری از عملیات نگهداری دیگر روی کل جدول انجام نمیشوند.
برای مثال:
- Rebuild Index
- Reorganize Index
- Update Statistics
- Backup
- Archive
میتوانند تنها روی پارتیشنهای موردنیاز اجرا شوند.
در نتیجه:
- زمان Maintenance کاهش پیدا میکند.
- مصرف منابع کمتر میشود.
- پنجره نگهداری کوتاهتر خواهد بود.
- تأثیر عملیات روی کاربران نهایی کاهش مییابد.
چه نوع سیستمهایی بیشترین بهره را از Partitioning میبرند؟
اگرچه SQL Server Partitioning برای همه پایگاههای داده مناسب نیست، اما در برخی سناریوها میتواند ارزش بسیار بالایی ایجاد کند.
از جمله:
- سیستمهای ERP بزرگ
- سامانههای مالی با دادههای چندساله
- Data Warehouse
- سیستمهای BI
- سامانههای ثبت لاگ
- سیستمهای مانیتورینگ
- پلتفرمهای IoT
- سامانههای مخابراتی
- سیستمهای بیمه
- مراکز داده با حجم عظیم تراکنش
وجه مشترک تمام این سیستمها، رشد مداوم دادهها و نیاز به مدیریت اطلاعات تاریخی است.
بزرگترین سوءبرداشت درباره SQL Server Partitioning
اگر بخواهیم تنها یک نکته از این مقاله را به خاطر بسپاریم، آن نکته این است:
Partitioning ابزار افزایش خودکار Performance نیست، بلکه ابزاری برای مدیریت هوشمند دادههای حجیم است.
هرگاه طراحی Queryها، انتخاب Partition Key، ساختار ایندکسها و الگوی دسترسی به دادهها با یکدیگر هماهنگ باشند، SQL Server Partitioning میتواند هم عملیات نگهداری را سادهتر کند و هم در برخی سناریوها باعث بهبود قابل توجه Performance شود.
چه زمانی نباید از SQL Server Partitioning استفاده کنیم؟
اگرچه SQL Server Partitioning یکی از قدرتمندترین قابلیتهای SQL Server برای مدیریت دادههای حجیم است، اما استفاده از آن همیشه تصمیم درستی نیست.
در واقع، یکی از اشتباهات رایج این است که سازمانها تنها به دلیل بزرگ شدن یک جدول، به سراغ Partitioning میروند؛ در حالی که مشکل اصلی ممکن است کاملاً جای دیگری باشد.
در بسیاری از پروژههای بهینهسازی Performance، مشاهده میشود که با اصلاح ایندکسها، بازنویسی Queryها یا بهروزرسانی آمارها (Statistics)، نتیجهای بسیار بهتر از پیادهسازی Partitioning به دست میآید.
به همین دلیل، پیش از طراحی Partitioning باید مطمئن شوید که واقعاً با مسئلهای روبهرو هستید که این قابلیت برای حل آن طراحی شده است.
چه زمانی Partitioning انتخاب مناسبی نیست؟
در شرایط زیر، معمولاً استفاده از Partitioning توصیه نمیشود:
حجم جدول هنوز بزرگ نیست
اگر جدول تنها چند میلیون رکورد دارد و عملیات نگهداری بهراحتی انجام میشود، اضافه کردن Partitioning تنها پیچیدگی سیستم را افزایش میدهد.
Queryها بر اساس Partition Key فیلتر نمیشوند
اگر اکثر Queryها از ستونی غیر از Partition Key استفاده کنند، قابلیت Partition Elimination عملاً بیاثر خواهد شد.
در چنین شرایطی SQL Server همچنان بخش بزرگی از جدول را اسکن میکند.
مشکل اصلی، طراحی نامناسب ایندکسهاست
بارها دیده شده است که دلیل کندی سیستم، نبود ایندکس مناسب یا طراحی ضعیف Clustered Index بوده است.
در این حالت، Partitioning مشکل را حل نخواهد کرد.
مشکل از Queryهاست
گاهی Queryها شامل موارد زیر هستند:
- Predicateهای غیرقابل SARG
- استفاده بیش از حد از Functionها
- Joinهای غیرضروری
- Cursorها
- طراحی ضعیف Execution Plan
تا زمانی که این مشکلات برطرف نشوند، انتظار افزایش Performance با Partitioning منطقی نیست.
اشتباهات رایج در پیادهسازی SQL Server Partitioning
حتی زمانی که تصمیم به استفاده از Partitioning صحیح باشد، اجرای نادرست آن میتواند مزایای این معماری را از بین ببرد.
رایجترین اشتباهات عبارتاند از:
- انتخاب نادرست Partition Key
- ایجاد تعداد بسیار زیاد Partition
- استفاده از Partition برای جداول کوچک
- ناهماهنگی ایندکسها با Partition Scheme
- نادیده گرفتن Partition Elimination
- طراحی نامناسب Filegroupها
- نداشتن استراتژی Sliding Window
- بیتوجهی به بهروزرسانی Statistics
در بسیاری از موارد، همین اشتباهات باعث میشوند سازمانها تصور کنند Partitioning هیچ تأثیری بر Performance ندارد.
نکات قابل توجه
اگر قصد پیادهسازی Partitioning در یک محیط Enterprise را دارید، رعایت چند اصل میتواند تفاوت قابل توجهی ایجاد کند.
Partition Key را بر اساس الگوی Queryها انتخاب کنید
همیشه ستونی را انتخاب کنید که بیشترین نقش را در فیلتر کردن دادهها دارد.
در اغلب سیستمهای عملیاتی، ستونهای زمانی بهترین گزینه هستند.
تعداد Partitionها را منطقی نگه دارید
ایجاد صدها یا هزاران Partition معمولاً مزیت خاصی ایجاد نمیکند و حتی میتواند سربار مدیریتی را افزایش دهد.
از Sliding Window استفاده کنید
اگر دادههای قدیمی بهصورت دورهای حذف یا آرشیو میشوند، طراحی معماری بر اساس Sliding Window یکی از بهترین انتخابها خواهد بود.
ایندکسها را همسو با Partition طراحی کنید
Aligned Indexها معمولاً مدیریت سادهتر و عملیات نگهداری کارآمدتری فراهم میکنند.
قبل و بعد از پیادهسازی Benchmark بگیرید
هیچ تصمیمی نباید بر اساس حدس گرفته شود.
شاخصهایی مانند:
- مدت اجرای Queryها
- میزان Logical Read
- مصرف CPU
- زمان Maintenance
- مدت Backup و Restore
باید قبل و بعد از پیادهسازی مقایسه شوند.
مثال
فرض کنید یک سامانه مانیتورینگ روزانه بیش از ۵۰ میلیون رکورد جدید ثبت میکند.
در پایان هر ماه نیز دادههای قدیمی باید به آرشیو منتقل شوند.
در معماری سنتی، حذف این اطلاعات ممکن است:
- چندین ساعت طول بکشد.
- Transaction Log بسیار بزرگی ایجاد کند.
- باعث Lock شدن جدول شود.
- روی کاربران نهایی تأثیر بگذارد.
اما در معماری مبتنی بر SQL Server Partitioning، دادههای هر ماه در یک پارتیشن مجزا نگهداری میشوند و فرآیند آرشیو تنها با جابهجایی یا حذف همان پارتیشن انجام میشود؛ عملیاتی که در مقایسه با حذف میلیونها رکورد، بسیار سریعتر و کمهزینهتر است.
این دقیقاً همان سناریویی است که SQL Server Partitioning برای آن طراحی شده است.
نتیجهگیری
SQL Server Partitioning یکی از ارزشمندترین قابلیتهای SQL Server برای مدیریت جداول بسیار بزرگ است، اما نباید آن را راهکاری جادویی برای افزایش Performance دانست.
اگر حجم دادهها، الگوی Queryها، ساختار ایندکسها و فرآیندهای نگهداری با اصول Partitioning همسو باشند، این قابلیت میتواند زمان Maintenance را کاهش دهد، عملیات آرشیو را سادهتر کند و در برخی سناریوها از طریق Partition Elimination عملکرد Queryها را نیز بهبود ببخشد.
در مقابل، استفاده از Partitioning بدون تحلیل دقیق نیازهای سیستم، تنها پیچیدگی معماری را افزایش خواهد داد و ممکن است هیچ مزیت محسوسی ایجاد نکند.
معماری موفق زمانی شکل میگیرد که هر قابلیت SQL Server دقیقاً برای مسئلهای استفاده شود که برای حل آن طراحی شده است.
سوالات متداول (FAQ)
1. SQL Server Partitioning چیست؟
SQL Server Partitioning قابلیتی است که جدول یا ایندکسهای بسیار بزرگ را به چند بخش منطقی تقسیم میکند تا مدیریت داده، عملیات نگهداری و برخی سناریوهای پردازشی سادهتر شوند.
2. آیا Partitioning همیشه باعث افزایش Performance میشود؟
خیر، افزایش Performance تنها زمانی رخ میدهد که Queryها بتوانند از Partition Elimination استفاده کنند و طراحی Partition Key و ایندکسها نیز بهدرستی انجام شده باشد.
3. بهترین Partition Key چیست؟
در بسیاری از سیستمهای سازمانی، ستونهای زمانی مانند OrderDate، TransactionDate یا CreatedDate بهترین انتخاب هستند، زیرا هم با الگوی رشد داده سازگارند و هم در عملیات آرشیو و نگهداری کاربرد دارند.
4. تفاوت Partitioning و Sharding چیست؟
Partitioning دادهها را در یک پایگاه داده و یک جدول منطقی مدیریت میکند، در حالی که Sharding دادهها را میان چند پایگاه داده یا چند سرور توزیع میکند.
5. چه زمانی نباید از SQL Server Partitioning استفاده کنیم؟
اگر جدول حجم کمی دارد، Queryها از Partition Key استفاده نمیکنند یا مشکل اصلی به طراحی ایندکسها و Queryها مربوط است، معمولاً Partitioning انتخاب مناسبی نخواهد بود.
آیا ساختار جداول SQL Server شما برای رشد آینده آماده است؟
اگر پایگاه داده سازمان شما با جداول حجیم، زمان طولانی عملیات نگهداری، آرشیو دادههای تاریخی یا افت عملکرد Queryها مواجه است، بررسی معماری Partitioning میتواند بخشی از راهحل باشد. متخصصان توسعه فناوری اطلاعات لاندا با تحلیل ساختار داده، الگوی بار کاری و طراحی معماری SQL Server، به شما کمک میکنند تا مشخص شود آیا Partitioning بهترین انتخاب برای محیط شماست یا راهکارهای بهینهتری وجود دارد.
همین امروز با کارشناسان لاندا تماس ✆ بگیرید، تیم لاندا میتواند از مرحله طراحی تا اجرا در کنار شما باشد.



No comment