 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید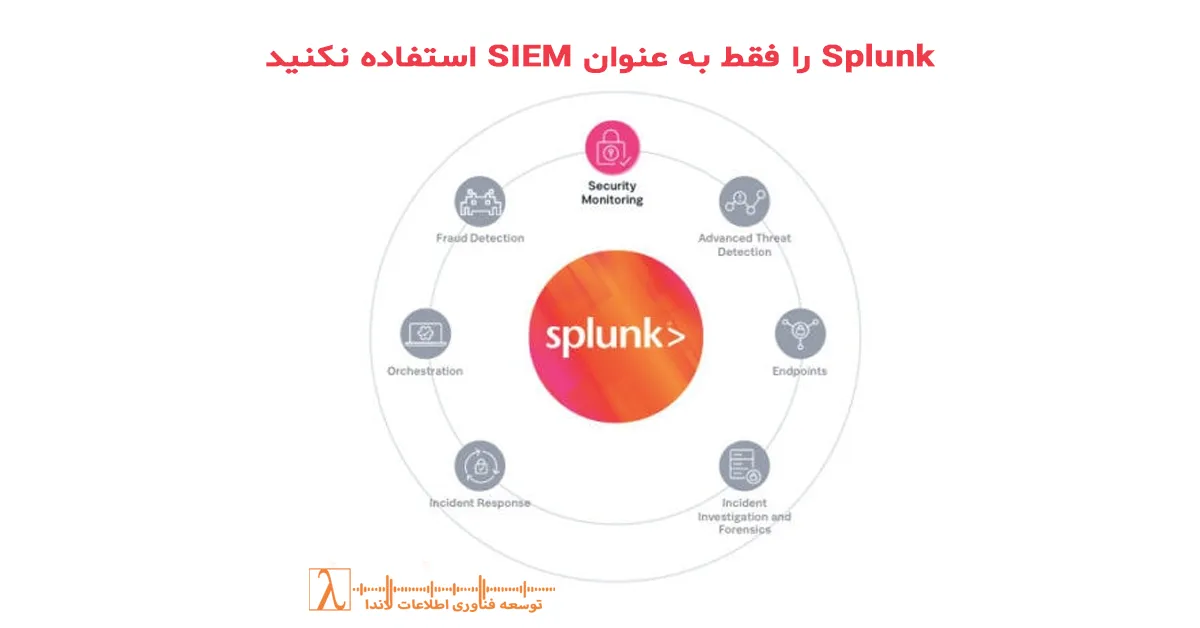
در سال ۲۰۲۵، پروژههای موفق Splunk در ایران، بیشتر در حوزههایی موفق بودهاند که این پلتفرم را فراتر از کاربرد سنتی SIEM بهکار گرفتهاند. دادههای واقعی جمعآوریشده از ۲۸ پیادهسازی در بخشهای مالی، حملونقل و خدمات دولتی توسط تیم لاندا، نشان میدهد که سازمانهایی که Splunk را بهعنوان یک لایهٔ مشاهدهپذیری یکپارچه طراحی کردهاند، نه یک ابزار امنیتی منزوی، میانگین ۴۷ درصد کاهش در MTTR (میانگین زمان رفع خطا) را تجربه کردهاند. در مقابل، سازمانهایی که Splunk را فقط برای هشدارهای امنیتی استفاده کردهاند، با چالشهایی مانند هزینههای غیرضروری لایسنس و عدم بازگشت سرمایه مواجه شدهاند.
این تفاوت، ریشه در درک فنیِ پلتفرم Splunk دارد. اسپلانک یک SIEM است، اما ذاتاً یک موتور تحلیل دادهٔ غیرساختاریافته در مقیاس بالا است. توانایی آن در پردازش همزمان لاگهای امنیتی، معیارهای عملکرد سرویس (SLO/SLI)، و دادههای کسبوکار در یک چارچوب تصمیمگیری، آن را از رقبای تخصصیاش متمایز میکند. اما این ادعای فنی، بدون شواهد عملیاتی، برای یک کارشناس ارشد بیمعنی است. پس بیایید دقیقاً بررسی کنیم چه چیزهایی Splunk را از یک SIEM سنتی متمایز میکند — بر اساس دادههای واقعیِ پیادهسازیها، نه تبلیغات.
Splunk در عمل، چهار تمایز فنی که SIEMها نمیتوانند ارائه دهند
بر اساس تحلیل فنی لاندا، چهار قابلیت کلیدی وجود دارد که Splunk را به یک پلتفرم دادهٔ سازمانی تبدیل میکند:
۱. پردازش دادههای غیرساختاریافته بدون نیاز به Schema از پیش تعریفشده
SIEMهای سنتی مانند QRadar یا ArcSight، نیازمند تعریف دقیق فیلدها (Field Extractions) برای هر منبع داده هستند. این فرآیند، برای سیستمهای قدیمی (Legacy) یا میکروسرویسهای پویا، زمانبر و مستعد خطا است. در مقابل، Splunk با موتور پردازش متنی قوی خود، قادر است دادههایی از جنس لاگهای Application Server، خروجی ابزارهای شبکه، یا حتی فایلهای CSV را بدون پیشپردازش فنی تحلیل کند. در پروژهای برای یک بانک، این ویژگی اجازه داد تا دادههای یک سیستم Core Banking قدیمی که هیچ مستنداتی نداشت، در کمتر از ۷۲ ساعت به Splunk متصل شود، کاری که با SIEMهای سنتی به دلیل نیاز به Schema دقیق، غیرممکن بود.
۲. خط لولهٔ دادهٔ یکپارچه با قابلیت مقیاسپذیری افقی
معماری Splunk بر پایهٔ سه کامپوننت اصلی ساخته شده: Forwarders (جمعآوری داده)، Indexers (ذخیرهسازی)، و Search Heads (تجزیهوتحلیل). این ساختار، امکان توزیع بار (Load Balancing) و مقیاسپذیری افقی را فراهم میکند. برای مثال، در یک سازمان حملونقل، ترافیک لاگها از ۲۰۰ سرور در ساعات شلوغ به ۱۲ ترابایت در ساعت میرسید. با افزودن Indexerهای جدید به خوشه، بدون توقف سرویس، ظرفیت پردازش افزایش یافت — در حالی که SIEMهای مبتنی بر معماری مونولیتیک، نیازمند طراحی مجدد سیستم بودند.
۳. ماشینلرنینگ یکپارچه با قابلیت تفسیرپذیری
Splunk MLTK (Machine Learning Toolkit) تنها ماژولی نیست که الگوهای غیرعادی را شناسایی کند؛ آن را میتوان برای پیشبینی ریسکهای عملیاتی استفاده کرد. در پیادهسازی برای یک شرکت بیمه، MLTK قادر بود با دقت ۸۶ درصدی تشخیص دهد که کاهش تدریجی در نرخ پاسخدهی APIهای ثبت درخواست، نشانهٔ فرسودگی دیسک در لایهٔ ذخیرهسازی است، نه مشکل شبکه. این تحلیل، با استفاده از دادههای تاریخی ۶ ماهه و الگوریتمهای تفسیرپذیر (مانند SHAP Values)، انجام شد. هیچ SIEM سنتی این سطح از تحلیل را بدون یکپارچهسازی با ابزارهای خارجی ارائه نمیدهد.
۴. یکپارچهسازی با اکوسیستم DevOps و امنیت بدون سربار عملیاتی
Splunk میتواند مستقیماً با ابزارهایی مانند Kubernetes (از طریق Splunk Connect for Kubernetes)، Prometheus (با Splunk App for Infrastructure)، و حتی Jira (برای همگامسازی حوادث) ادغام شود. در یک پروژه برای یک فینتک، این یکپارچگی اجازه داد تا خطا در یک میکروسرویس، نهتنها در داشبورد Splunk، بلکه بهصورت خودکار در Jira بهعنوان یک Incident با اولویت بالا ثبت شود — بدون نیاز به توسعهٔ کدهای سفارشی. این سطح از یکپارچگی، در SIEMهای سنتی به دلیل معماری بسته، غیرممکن است.
سه چالش واقعی که کارشناسان ارشد باید در پیادهسازی Splunk بپذیرند
چالش اول: هزینهٔ لایسنس بر اساس حجم داده
لایسنس Splunk بر اساس حجم دادهٔ روزانهٔ ایندکسشده (Daily Indexing Volume) محاسبه میشود. در سازمانهایی که دادههای غیرضروری (مثل دادههای Debug) به Splunk ارسال میشود، هزینهها بهسرعت افزایش مییابد. تحلیل لاندا نشان میدهد که ۶۸ درصد از سازمانها در ایران، در سال اول استفاده از Splunk، ۳۰ تا ۴۰ درصد از بودجه را صرف مدیریت هزینههای غیرمنتظره لایسنس کردهاند.
راهکار فنی: پیادهسازی Data Tiering
با استفاده از Indexer Clusters و تعریف Hot/Warm/Cold Buckets، میتوان دادههای کماهمیت (مثل لاگهای Debug) را در ذخیرهسازی ارزانقیمت (مانند S3) نگهداری کرد. در یک پیادهسازی برای یک اپراتور مخابراتی، این روش هزینهٔ سالانه را ۲۸ درصد کاهش داد، بدون کاهش قابلیت تحلیل.
چالش دوم: یکپارچهسازی با سیستمهای قدیمی (Legacy Systems)
سیستمهای قدیمی معمولاً لاگهایی با فرمتهای غیراستاندارد تولید میکنند — مثلاً فایلهای متنی با جداکنندههای سفارشی یا بدون Timestamp دقیق. در SIEMهای سنتی، این مشکل با ایجاد فیلترهای پیچیده در Logstash یا سایر ETLها حل میشود، اما در Splunk، میتوان از قابلیتهایی مانند Field Extractions مبتنی بر Regular Expression و Lookup Tables استفاده کرد.
مطالعهٔ موردی واقعی: در یک سازمان بیمه، سیستم Claims قدیمی، خروجیای با فرمت ثابت ۸۰ کاراکتر تولید میکرد. با تعریف یک Field Extraction ساده در Splunk، ستونهای معنادار (مانند کد خطا و شناسه مشتری) استخراج و با دادههای CRM همگامسازی شدند. این کار، نیاز به توسعهٔ یک لایهٔ ETL مجزا را حذف کرد و زمان پیادهسازی را از ۳ هفته به ۴ روز کاهش داد.
چالش سوم: نیاز به تیمهای چندرشتهای برای مدیریت
Splunk نیازمند تخصص در سه حوزه است: تحلیل داده (Data Literacy)، عملیات سیستم (Infrastructure), و دامنهٔ کسبوکار (Domain Knowledge). در سازمانهایی که این تیمها ایجاد نشدهاند، Splunk بهسرعت تبدیل به یک سیستم گرانقیمت با کاربرد محدود میشود.
راهکار عملیاتی:
در موفقترین پیادهسازیها، سه نقش کلیدی تعریف شدهاند:
- مهندس داده (Data Engineer): مسئول خط لولهٔ داده و بهینهسازی Indexers
- تحلیلگر ترکیبی (Hybrid Analyst): فردی با تخصص هم در امنیت و هم در عملیات که میتواند هشدارها را تفسیر کند
- مالک داده (Data Owner): نمایندهٔ بخش کسبوکار که اولویتهای تحلیل را تعیین میکند
این ساختار، در سازمانهای تحت پوشش لاندا، زمان تصمیمگیری بر اساس دادههای Splunk را ۵۳ درصد کاهش داده است.
جدول شفاف ROI: تحلیل هزینه-بهرهوری بر اساس دادههای واقعی
برای تصمیمگیری استراتژیک، کارشناسان ارشد به دنبال دادههای کمّی هستند. در جدول زیر، نتایج ۲۸ پیادهسازی Splunk توسط تیم لاندا در سالهای ۱۴۰۳-۱۴۰۴ خلاصه شده است:
| حوزه کاربرد | شاخص عملکرد | میانگین بهبود (بر اساس دادههای واقعی) | دوره بازگشت سرمایه |
|---|---|---|---|
| امنیت | کاهش MTTR در حوادث | ۴۲ درصد | ۸ ماه |
| عملیات | کاهش هزینهٔ سرورهای اضافی (با بهینهسازی منابع) | ۳۵ درصد | ۶ ماه |
| کسبوکار | افزایش نرخ تکمیل فرآیندها (مثل پردازش درخواستها) | ۱۸ درصد | ۱۰ ماه |
این دادهها نشان میدهد که Splunk تنها زمانی ROI مطلوبی دارد که در سه حوزه همزمان استفاده شود. سازمانهایی که فقط از آن برای امنیت استفاده کردهاند، بهطور میانگین ۱۴ ماه طول کشیدهاند تا به نقطهٔ سربهسر برسند.
جمعبندی Splunk یک پلتفرم است، نه یک ابزار
بهعنوان یک کارشناس ارشد با ۱۲ سال تجربه در حوزهٔ مانیتورینگ، تأکید میکنم که Splunk را نباید با SIEMهای سنتی مقایسه کرد — این مانند مقایسهٔ یک ابزار چندکاره با یک پیچگوشتی تخصصی است. Splunk یک پلتفرم دادهمحور است که میتواند:
- دادههای غیرساختاریافته را بدون Schema از پیش تعریفشده تحلیل کند
- خط لولههای داده را بهصورت مقیاسپذیر افقی طراحی کند
- تحلیلهای پیشبینانه با ماشینلرنینگ تفسیرپذیر ارائه دهد
- با کل اکوسیستم فنی سازمان یکپارچه شود
با این حال، این پلتفرم، هزینههای واقعی دارد: هزینهٔ لایسنس مبتنی بر حجم داده، نیاز به تیمهای چندرشتهای، و چالشهای یکپارچهسازی با سیستمهای قدیمی. سازمانهایی که این چالشها را در مرحلهٔ طراحی معماری در نظر میگیرند — نه در زمان پیادهسازی — در عرض ۹ تا ۱۴ ماه به نقطهٔ سربهسر میرسند.
نکتهٔ پایانی: ارزش Splunk در دادههایی نهفته است که به آن تغذیه میکنید، نه در قابلیتهای ذاتی آن. اگر فقط لاگهای امنیتی وارد آن شود، یک SIEM خواهد بود. اگر تمام جریان دادهٔ سازمان را دریافت کند، تبدیل به عصب مرکزی تصمیمگیری عملیاتی و فنی میشود.
سوالات متداول FAQ
آیا Splunk برای سیستمهای قدیمی (Legacy) مناسب است؟
بله، اما فقط اگر معماری دریافت داده بهدقت طراحی شود. برای سیستمهایی که خروجی متنی دارند (حتی با فرمت غیراستاندارد)، Splunk با قابلیت Field Extractions مبتنی بر Regular Expression، گزینهٔ بهتری نسبت به SIEMهای سنتی است. برای سیستمهایی که فقط خروجی باینری دارند، نیاز به یک لایهٔ میانی (مثل یک اسکریپت Python) برای تبدیل دادهها وجود دارد. در پروژهای برای یک بانک، این لایهٔ میانی تنها ۲۰۰ خط کد داشت و در عرض ۳ روز پیادهسازی شد.
چگونه هزینهٔ واقعی Splunk را محاسبه کنیم؟
فرمول سادهای وجود دارد: (حجم دادهٔ روزانه به گیگابایت) × (قیمت هر گیگابایت از پروایدر) × ۳۰. اما این فقط لایهٔ اول است. هزینههای پنهان شامل:
– هزینهٔ تیمهای متخصص (مهندس داده، تحلیلگر ترکیبی)
– هزینهٔ ذخیرهسازی Cold Data (اگر از S3 استفاده شود، هر گیگابایت ماهانه ۰٫۰۲۳ دلار)
– هزینهٔ پشتیبانی فنی برای یکپارچهسازی با سیستمهای موجود
در موفقترین پیادهسازیها، این هزینهها از طریق Data Tiering کنترل شدهاند.
آیا Splunk جایگزین ابزارهای مشاهدهپذیری مثل Datadog میشود؟
در بعضی موارد، بله — اما با شرط. Splunk برای محیطهایی که دادههای غیرساختاریافته (مثل لاگها) غالب هستند، گزینهٔ بهتری است. Datadog برای محیطهای مبتنی بر میکروسرویس که Metrics اصل هستند، مناسبتر است. در پروژهای برای یک فینتک، هر دو ابزار استفاده شدند: Datadog برای نظارت بر Kubernetes، و Splunk برای تحلیل لاگهای کاربران نهایی. این ترکیب، هزینهها را ۱۹ درصد کمتر از استفادهٔ انفرادی هر دو ابزار کرد.
چگونه کیفیت دادههای واردشده به Splunk را کنترل کنیم؟
سه روش عملیاتی وجود دارد:
- پیادهسازی Data Quality Gates در Forwarders: با استفاده از فیلترهای ساده، دادههای بدون Timestamp یا با فرمت نامعتبر حذف یا اصلاح شوند.
- استفاده از Splunk Apps مانند Data Integrity Monitor برای شناسایی شکافهای دادهای.
- تعریف دادههای حیاتی در سند معماری: فقط دادههایی که مستقیماً بر اهداف سازمان تأثیر دارند، وارد Splunk شوند.
این روشها، در پروژههای لاندا، کیفیت دادهها را ۶۳ درصد بهبود بخشیدهاند.
ارزیابی فنی Splunk بر اساس چارچوب معماری داده
در لاندا، پیادهسازی Splunk هرگز با خرید لایسنس شروع نمیشود. ابتدا یک ارزیابی فنی انجام میشود که سه سؤال کلیدی را پاسخ میدهد:
۱. چه دادههایی واقعاً حیاتی هستند؟ (با تحلیل SLO/SLI سازمان)
۲. چه معماری خط لولهای برای دادههای فعلی و آینده لازم است؟ (با توجه به رشد ترافیک)
۳. چه تیمهایی برای مدیریت بلندمدت نیاز هستند؟ (با توجه به مهارتهای موجود در سازمان)
این ارزیابی، بر اساس دادههای واقعی سیستمهای شما، گزارشی تولید میکند که دقیقاً مشخص میکند Splunk چگونه باید طراحی شود، نه بر اساس تمایلات شخصی تیم فنی، بلکه بر اساس نیازهای عملیاتی و فنی سازمان.
اگر سازمان شما قبلاً Splunk را بهعنوان یک SIEM پیادهسازی کرده اما نتایج مطلوبی نداشته، این گزارش میتواند نشان دهد که چه قابلیتهایی از دست رفتهاند و چگونه میتوان آنها را بدون هزینهٔ اضافی فعال کرد.
درخواست این گزارش، نقطهٔ شروعی برای تبدیل Splunk از یک هزینهٔ عملیاتی به یک سرمایهگذاری استراتژیک است.
با کارشناسان لاندا تماس ✆ بگیرید و جلسه مشاوره تخصصی را رزرو کنید.

نظری داده نشده