 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید
در سازمانهای مدرن، حجم دادههای متنی بهشدت افزایش یافته: مکاتبات، پیامهای داخلی، مستندات فنی، فایلهای Word، گزارشها، Wiki، لاگهای حادثه امنیتی و حتی کدهای نرمافزار.
مشکل اینجاست که جستجوی سنتی مبتنی بر کلمه (Keyword Search) در چنین محیطی دیگر پاسخگو نیست. کاربر بهدنبال «معنا»ست، نه صرفاً کلمات.
اگر کاربری جستجو کند:
“راهکار کاهش تاخیر عملکرد Query”
اما در دیتابیس متنی عبارت:
“SQL Server performance tuning”
ثبت شده باشد، جستوجوی معمول آن را پیدا نمیکند. اینجا Semantic Search وارد میشود.
Semantic Search چیست؟
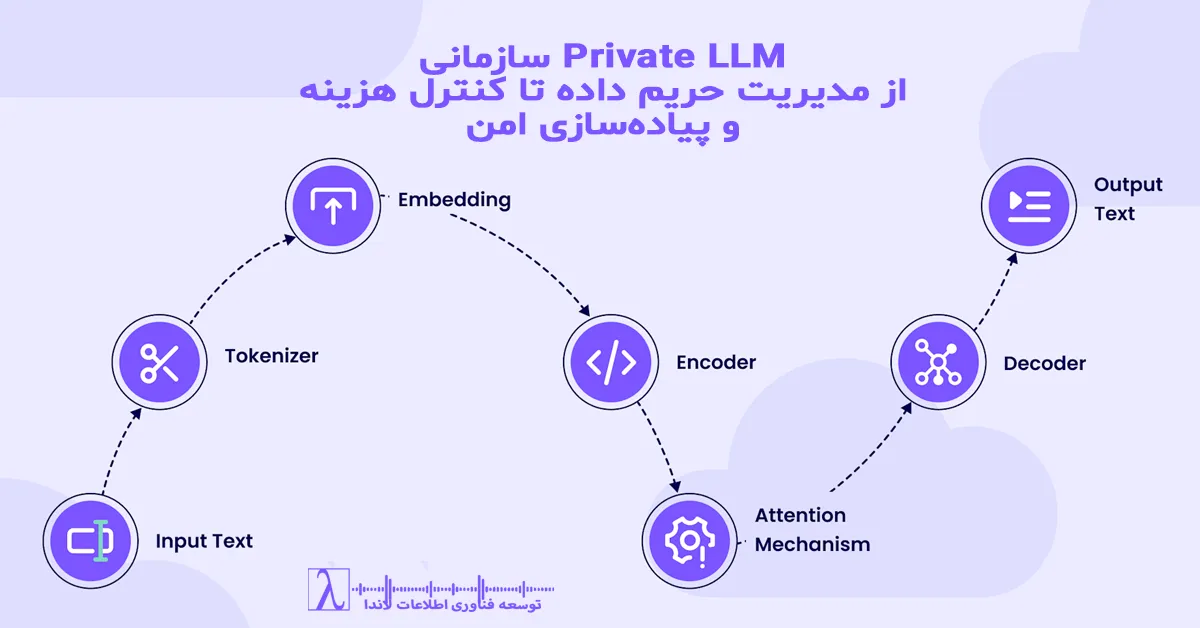
Semantic Search یعنی جستجوی مفهومی. سیستم متن را میفهمد، نه اینکه فقط تطبیق لغت انجام دهد. در Semantic Search، هر متن تبدیل به یک بردار عددی میشود که به آن Embedding میگوییم.
- متون هممعنا → بردارهای نزدیک
- متون نامرتبط → بردارهای دور
"SQL Index Tuning" → [۰.۴۴, ۰.۹۱, -۰.۰۲, ...]
"Improve Query Speed" → [۰.۴۵, ۰.۸۹, -۰.۰۱, ...]
این شباهت برداری همان کلید طلایی است.
Embeddings چگونه ساخته میشوند؟
اینجا نقش مدلهای زبانی (LLM) مطرح میشود.
یکی از بهترین گزینههای حال حاضر: Gemma.
چرا Gemma؟
- سبک و قابل استقرار درون سازمانی (On-Premise)
- بدون نیاز به GPU برای اجرای inference
- مناسب برای دادههای حساس (بانکها، بیمهها، مالی)
- قابل Fine-Tuning روی دامنههای تخصصی
(مثلاً SQL Server، شبکه، ISO 27001، مالی، پزشکی و …)
یعنی میتوانید «زبان داخلی سازمان» را به مدل یاد بدهید.
Vector Database؛ پایگاه داده مخصوص فهم
دیتابیسهای معمولی مثل SQL Server یا PostgreSQL برای جستوجوی برداری طراحی نشدهاند. در Semantic Search به دیتابیسی نیاز داریم که بتواند:
- بردارها را ذخیره کند.
- فاصله معنایی را بسیار سریع محاسبه کند.
- جستجوی برداری با Annoy / HNSW / IVF انجام دهد.
به این دیتابیسها میگوییم: Vector Database
گزینههای پیشنهادی
| نام | مدل استقرار | مزایا | مناسب برای |
|---|---|---|---|
| Qdrant | Self-Hosted / Kubernetes | سریع و پایدار | بانکها و مراکز داده داخلی |
| Weaviate | Self-Hosted + Cloud | قابلیت Schema Graph | سازمانهای BI محور |
| Pinecone | Cloud | کمترین نگهداری | SaaS و شرکتهای مقیاسپذیر |
| ChromaDB | Embedded / Local | سبک و ساده | MVP و PoC ها |
برای سازمانهای ایرانی → Qdrant بهترین انتخاب است.
معماری پیشنهادی برای سازمان
کاربر
│
جستوجوی متنی
│
تبدیل Query به Embedding
│
جستوجوی برداری در Vector DB
│
بازیابی نزدیکترین اسناد معنایی
│
رتبهبندی + پاسخ
پیادهسازی قدمبهقدم
۱) ساخت Embedding با Gemma
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("gtr-t5-large") # نسخه نزدیک به رفتار Gemma
embedding = model.encode("SQL Server performance tuning")
۲) ذخیره در Qdrant
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
qdrant = QdrantClient(":memory:")
qdrant.recreate_collection(
"docs",
vectors_config=VectorParams(size=768, distance=Distance.COSINE)
)
۳) جستجوی معنایی
query = model.encode("Improve slow SQL queries").tolist()
result = qdrant.search("docs", query_vector=query, limit=5)
Use Case واقعی که ارزش تولید میکند.
۱) تیمهای پشتیبانی IT / NOC / SOC
جستجوی معنایی در:
- Incident ها
- KB ها
- Change Logs
- Ticketing System
کاهش زمان Mean Time To Resolve (MTTR) تا ۴۵٪
۲) تیمهای توسعه و DevOps
جستوجوی معنایی در:
- Git Logs
- مستندات API
- Issue Tracker
کاهش دوبارهکاری و تکرار خطاها
۳) بانکها و شرکتهای مالی
بدون خروج داده به سرویس خارجی:
- سرچ هوشمند مشتری
- تحلیل ریسک تراکنشها
- کشف تقلب معنایی
مزایا و معایب
| مزیت | توضیح |
|---|---|
| فهم مفهومی اطلاعات | بهترین بازیابی دانش سازمانی |
| کاهش زمان پاسخدهی | پشتیبانی و تحلیل سریعتر |
| قابل استقرار داخلی | بدون نقض محرمانگی دادهها |
| چالش | راهحل |
|---|---|
| نیاز به استخراج مداوم Embeddings | ساخت Data Pipeline |
| نیاز به Fine-Tuning برای دامنه تخصصی | آموزش روی مستندات داخلی |
| هزینه ساخت Vector Index در مقیاس بالا | استفاده از HNSW |
نتیجهگیری
Semantic Search فقط یک قابلیت نیست؛
یک مزیت رقابتی سازمانی است.
ترکیب:
- Embeddings
- Gemma
- Vector Database
یک سیستم «دانش سازمانی پویا» ایجاد میکند که:
- میفهمد.
- یاد میگیرد.
- و پاسخ میدهد.
این پایه نسل بعدی سیستمهای BI ،ITSM و AI داخلی است.
تماس و مشاوره با لاندا



نظری داده نشده