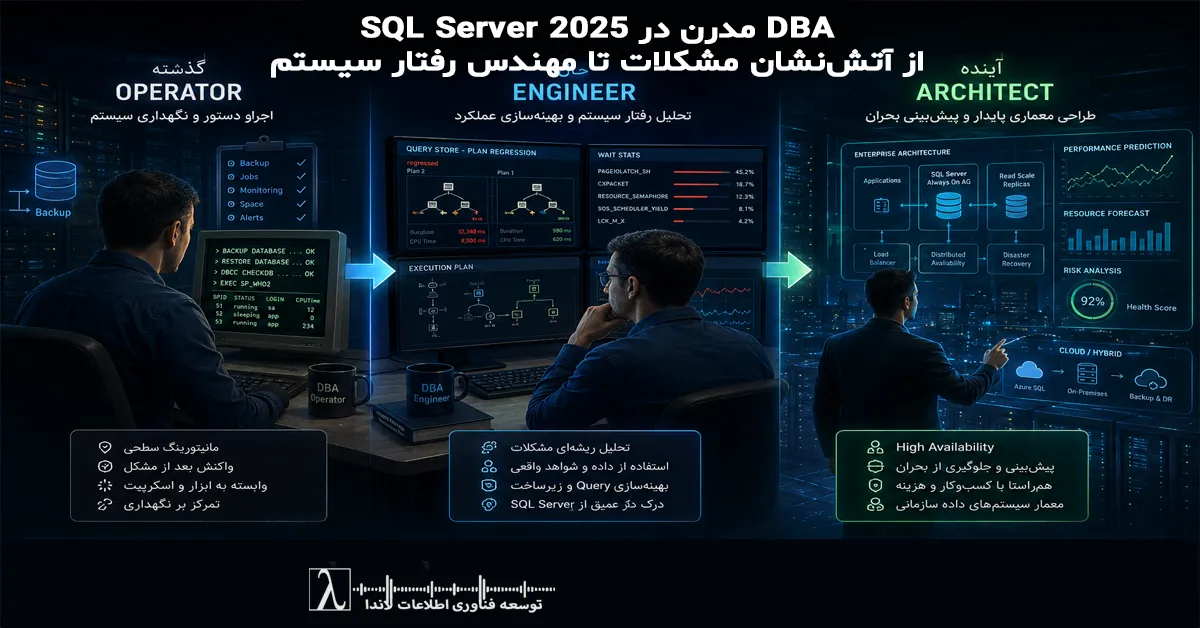
تصور کنید یک صبح معمولی در اتاق فرمان دیتاسنتر، ناگهان تلفن پشتیبانی به شدت زنگ میخورد. مدیر سیستم با صدای نگران و کمی عصبی میگوید: «همون کوئری گزارشگیری که همیشه زیر ۲۰۰ میلیثانیه اجرا میشد، الان ۱۲ ثانیه طول میکشه و کاربران دارن شدید اعتراض میکنن!»
بدون هیچ Deployment جدید، بدون تغییر در کد Application، بدون اضافه شدن حتی یک ایندکس تازه و بدون هیچ آپدیت نرمافزاری. این سناریو دیگر یک اتفاق نادر و استثنایی نیست، بلکه به یکی از چالشهای روزمره و تکرارشونده DBA مدرن در محیطهای Enterprise بزرگ تبدیل شده است.
در این مقاله جامع و عمیق، بر اساس تجربههای عملی و سناریوهای رایج در محیطهای Enterprise، به بررسی دقیق دلایل فنی این رفتار غیرمنتظره SQL Server 2025 میپردازیم. همچنین نشان میدهیم که DBAهای مدرن چگونه باید از حالت سنتی «آتشنشان مشکلات» به «مهندس رفتار سیستم» ارتقا پیدا کنند تا بتوانند با این دنیای جدید کنار بیایند.
تحول عمیق SQL Server از ۲۰۱۶ تا ۲۰۲۵
در نسخههای قدیمیتر مانند SQL Server ۲۰۱۲ و ۲۰۱۶، Query Optimizer نسبتاً ثابت و قابل پیشبینی عمل میکرد. اگر Execution Plan مناسبی برای یک کوئری ساخته میشد، معمولاً ماهها یا حتی سالها بدون تغییر باقی میماند. اما از SQL Server ۲۰۱۷ و بهخصوص از نسخه ۲۰۱۹ به بعد، مایکروسافت با معرفی مجموعه ویژگیهای Intelligent Query Processing (IQP) تحولی اساسی ایجاد کرد.
ویژگیهای مهمی مانند Adaptive Join، Memory Grant Feedback، Batch Mode on Rowstore، Degree of Parallelism Feedback، Parameter Sensitive Plan Optimization (PSPO)، Cardinality Estimation improvements و Automatic Tuning باعث شدند Optimizer بسیار هوشمندتر و تطبیقیتر شود.
در نسخههای جدید SQL Server و بهویژه از SQL Server 2019 به بعد، این قابلیتها بهتدریج تکامل یافتهاند و رفتار Query Optimizer را نسبت به گذشته بسیار پویاتر کردهاند.
نتیجه این تحول بزرگ این است که مفهوم «کوئری ثابت با عملکرد ثابت» تقریباً از بین رفته و آنچه امروز با آن مواجه هستیم، «رفتار متغیر، پویا و تطبیقی سیستم» است.
معماری تصمیمگیری Optimizer در SQL Server 2025
اجرای هر کوئری در SQL Server از چهار فاز اصلی عبور میکند:
- Parse Phase: بررسی ساختار و سینتکس کوئری
- Binding Phase: اتصال اشیاء به Schema واقعی
- Optimization Phase: مهمترین و پیچیدهترین بخش — ساخت Execution Plan بر اساس Cost Model
- Execution Phase: اجرای واقعی پلن انتخاب شده
فاز Optimization بر پایه سه ستون اصلی استوار است: Statistics، Cardinality Estimation Engine و مجموعهای از Heuristic Rules. Optimizer هرگز تمام دادهها را به صورت کامل و Real-Time نمیبیند؛ بلکه بر اساس تخمینهای آماری و نمونهبرداری تصمیمگیری میکند. همین مکانیسم «حدسزنی هوشمند» باعث میشود کوچکترین تغییر در توزیع دادهها (Data Skew)، وضعیت Memory Pressure یا Concurrency منجر به Plan Regression شود.
کیس استادی واقعی: بحران ۱۲ برابری عملکرد در محیط Production
در یکی از پروژههای Enterprise با حجم بالای تراکنش و بیش از هزار کاربر همزمان، تیم ما با سناریویی مواجه شد که افت ناگهانی Performance بدون هیچ تغییر ظاهری در زیرساخت رخ داده بود. یک Stored Procedure حیاتی که تا روز قبل در کمتر از ۲۰۰ میلیثانیه اجرا میشد، ناگهان به بیش از ۱۲ ثانیه زمان اجرا نیاز پیدا کرد.
تیم DevOps و DBA داخلی کاملاً شوکه شدند چون هیچ تغییری در Application، کد، Schema، ایندکس یا زیرساخت اعمال نشده بود.
مرحله اول: واکنشهای اولیه و اشتباهات رایج تیمها
تیم عملیاتی طبق روال همیشگی اقدامات زیر را انجام داد:
- بررسی کامل CPU، Memory Usage و Disk I/O
- ریاستارت Instance SQL Server
- اضافه کردن چندین ایندکس جدید روی ستونهای پراستفاده
- Clear کردن Procedure Cache و Plan Cache
- حتی بررسی و افزایش منابع مجازی سرور
متأسفانه هیچکدام از این اقدامات مشکل را حل نکرد و عملکرد همچنان در سطح بسیار پایینی باقی ماند.
مرحله دوم: تحلیل حرفهای و عمیق توسط DBA
با ورود تیم Senior DBA، تمرکز به سمت ابزارهای پیشرفته و دقیق رفت:
- تحلیل Wait Statistics با استفاده از DMVهای قدرتمند
- مقایسه دقیق Execution Planها در Query Store
- بررسی سلامت و سن Statistics
- شناسایی Cardinality Estimation Errors
- تحلیل Memory Grant و Spill به TempDB
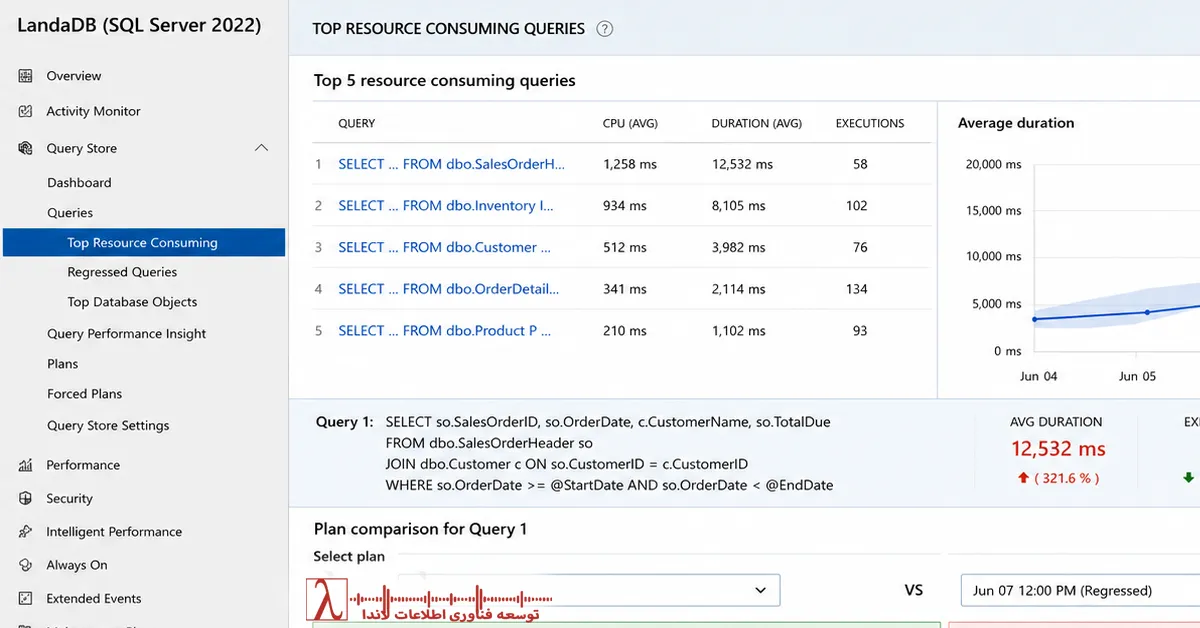
نتایج اولیه بسیار روشن بود:
- PAGEIOLATCH_SH به شدت افزایش یافته بود.
- RESOURCE_SEMAPHORE نشاندهنده کمبود جدی Memory Grant بود.
- CXPACKET Waits به دلیل Parallelism ناکارآمد و نامتعادل مشاهده میشد.
ریشه اصلی مشکل (Root Cause Analysis)
پس از چندین ساعت تحلیل دقیق و مقایسهای، دلایل اصلی شناسایی شدند:
- Batch Job شبانه بیش از ۲.۳ میلیون رکورد جدید با توزیع داده کاملاً متفاوت به جدول اصلی اضافه کرده بود (Data Skew شدید).
- Statistics جدول از ۹ روز قبل آپدیت نشده بود.
- Cardinality Estimator به شدت اشتباه کرده بود: فقط حدود ۴۸۰۰ ردیف تخمین زده بود، در حالی که واقعیت بیش از ۲.۴ میلیون ردیف بود.
این خطای تخمین باعث شد Optimizer به جای Index Seek بهینه، از Index Scan کامل استفاده کند، سپس Hash Join و Sort عملیات سنگین انجام دهد و در نهایت حجم زیادی از داده به TempDB Spill شود.
Parameter Sniffing دشمن پنهان Performance در SQL Server
Parameter Sniffing یکی از رایجترین و آزاردهندهترین چالشها در SQL Server برای یک DBA مدرن است. Stored Procedure بر اساس اولین ورودی اجرا شده، Execution Plan را Cache میکند و برای تمام فراخوانیهای بعدی از همان پلن استفاده مینماید.
در این پروژه، وقتی پروسیجر با ورودی کوچک اجرا شد، پلن بهینه برای داده کم ساخته شد. اما وقتی با حجم داده بزرگ فراخوانی گردید، همان پلن ناکارآمد باعث افت شدید عملکرد شد.
راهحلهای عملی و واقعی که در محیط Production جواب دادهاند:
- استفاده هوشمند و محدود از OPTION (RECOMPILE)
- فعالسازی Parameter Sensitive Plan Optimization (PSPO) در نسخه ۲۰۲۲ به بعد
- Query Rewrite با تکنیکهای پیشرفته
- استفاده از OPTIMIZE FOR UNKNOWN در موارد خاص
- ایجاد چندین نسخه از Stored Procedure برای حجمهای متفاوت داده
TempDB قاتل خاموش Performance در محیطهای Enterprise
بسیاری از مواقع همه معیارهای مانیتورینگ نرمال به نظر میرسند (CPU زیر ۴۰٪، Disk Idle)، اما کوئریها بسیار کند اجرا میشوند. دلیل اصلی اغلب Memory Spill به TempDB و Contention شدید در این دیتابیس است.
بهترین شیوههای عملی مدیریت TempDB در سال ۲۰۲۵:
- استفاده از حداقل ۸ تا ۱۶ فایل TempDB با اندازه یکسان
- قرار دادن TempDB روی Storage بسیار سریع (NVMe یا Azure Premium SSD)
- فعال کردن Instant File Initialization
- مانیتورینگ مداوم با DMVهای sys.dm_db_file_space_usage و sys.dm_os_waiting_tasks
تأثیر زنجیرهای بر Always On Availability Groups
Plan Regression و افزایش IO نه تنها کوئریها را کند میکند، بلکه بر لایه High Availability نیز تأثیر مستقیم میگذارد. افزایش Log Generation باعث بالا رفتن Log Send Queue، Lag در Secondary Replica و تأخیر در Failover میشود.
مدل بلوغ DBA در SQL Server 2025
نقش DBA مدرن امروز بسیار فراتر از کارهای روتین رفته است:
سطح ۱: Reactive DBA
آتشنشان: حل مشکل بعد از وقوع با روشهای سنتی مثل اضافه کردن ایندکس و ریاستارت.
سطح ۲: Diagnostic DBA
کارآگاه: پیدا کردن ریشه واقعی با Wait Stats، Query Store و Execution Plan Analysis.
سطح ۳: Predictive DBA
پیشبینیکننده: شناسایی Regressionها قبل از تأثیر جدی با Alerts هوشمند.
سطح ۴: Engineering DBA
مهندس: طراحی معماری، پیادهسازی استراتژیهای خودکار و ایجاد پایداری بلندمدت.
ابزارها و تکنیکهای ضروری DBA مدرن در سال ۲۰۲۵
تسلط کامل بر Query Store، Automatic Tuning، Intelligent Query Processing، Extended Events، Live Query Statistics و استراتژی پیشرفته نگهداری Statistics از الزامات امروز است.
بهترین practices عملی که میتوانید همین امروز پیادهسازی کنید
۱. بازنگری کامل استراتژی Statistics Maintenance با ترکیب FULLSCAN برای جداول بحرانی و Sampling هوشمند برای جداول بزرگ.
۲. فعالسازی Query Store با تنظیمات بهینه و ایجاد داشبوردهای گزارشگیری.
۳. پیادهسازی Alertهای هوشمند برای تشخیص Plan Regression.
۴. بهینهسازی کامل TempDB و IO Subsystem.
۵. استفاده گسترده از Database Scoped Configuration.
چند اسکریپت کاربردی برای تحلیل Performance
۱) اسکریپت DMV واقعی برای تشخیص Waitها:
-- Top Wait Statistics
SELECT TOP (15)
wait_type,
waiting_tasks_count,
wait_time_ms / 1000.0 AS wait_time_sec,
signal_wait_time_ms / 1000.0 AS signal_wait_sec,
100.0 * wait_time_ms /
SUM(wait_time_ms) OVER() AS wait_percentage
FROM sys.dm_os_wait_stats
WHERE wait_type NOT IN (
'CLR_SEMAPHORE','LAZYWRITER_SLEEP',
'RESOURCE_QUEUE','SLEEP_TASK',
'SLEEP_SYSTEMTASK','SQLTRACE_BUFFER_FLUSH',
'WAITFOR','LOGMGR_QUEUE',
'CHECKPOINT_QUEUE','REQUEST_FOR_DEADLOCK_SEARCH',
'XE_TIMER_EVENT','BROKER_TO_FLUSH',
'BROKER_TASK_STOP','CLR_AUTO_EVENT',
'CLR_MANUAL_EVENT'
)
ORDER BY wait_time_ms DESC;
این اسکریپت به DBA کمک میکند تشخیص دهد آیا افت عملکرد ناشی از I/O، کمبود حافظه، Parallelism یا سایر گلوگاههای سیستم است.
۲) اسکریپت Query Store برای پیدا کردن Plan Regression
SELECT TOP (10)
q.query_id,
qt.query_sql_text,
rs.avg_duration / 1000.0 AS avg_duration_ms,
rs.count_executions,
p.plan_id
FROM sys.query_store_query q
JOIN sys.query_store_query_text qt
ON q.query_text_id = qt.query_text_id
JOIN sys.query_store_plan p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats rs
ON p.plan_id = rs.plan_id
ORDER BY rs.avg_duration DESC;
Query Store یکی از مهمترین ابزارهای DBA مدرن برای مقایسه پلنهای قدیمی و جدید و شناسایی Plan Regression محسوب میشود. از SQL Server 2022 به بعد نیز بهصورت پیشفرض برای دیتابیسهای جدید فعال است.
۳) اسکریپت بررسی Memory Grant و Spill
SELECT
mg.session_id,
mg.requested_memory_kb,
mg.granted_memory_kb,
mg.used_memory_kb,
mg.max_used_memory_kb,
er.status,
er.command
FROM sys.dm_exec_query_memory_grants mg
JOIN sys.dm_exec_requests er
ON mg.session_id = er.session_id
ORDER BY mg.requested_memory_kb DESC;
این DMV به DBA نشان میدهد کدام کوئریها حافظه زیادی درخواست کردهاند و آیا کمبود Memory Grant میتواند عامل Spill شدن دادهها به TempDB باشد.
نتیجهگیری
در بسیاری از سناریوهای واقعی SQL Server، افت Performance نتیجه تعامل پیچیده میان Statistics، Cardinality Estimation و انتخاب Execution Plan است؛ نه صرفاً کمبود منابع سختافزاری. درک این موضوع و تغییر رویکرد از DBA سنتی به Engineering DBA، یکی از مهمترین عوامل موفقیت در مدیریت محیطهای مدرن محسوب میشود.
تیم DBA شما در حال حاضر در کدام سطح فعالیت میکند؟
- Reactive
- Diagnostic
- Predictive
- Engineering
اگر سیستم SQL Server شما هم گاهی غیرقابل پیشبینی شده و عملکردش افت کرده، تنها نیستید.
تیم ما با سالها تجربه در حل دقیق همین چالشها، آماده است تا با یک Audit Performance رایگان، ریشه مشکلات را پیدا کند و راهحلهای عملی و پایدار به شما ارائه دهد.
برای شروع، همین حالا با کارشناسان لاندا تماس ✆ بگیرید و مشاوره اولیه را رایگان دریافت کنید.


No comment