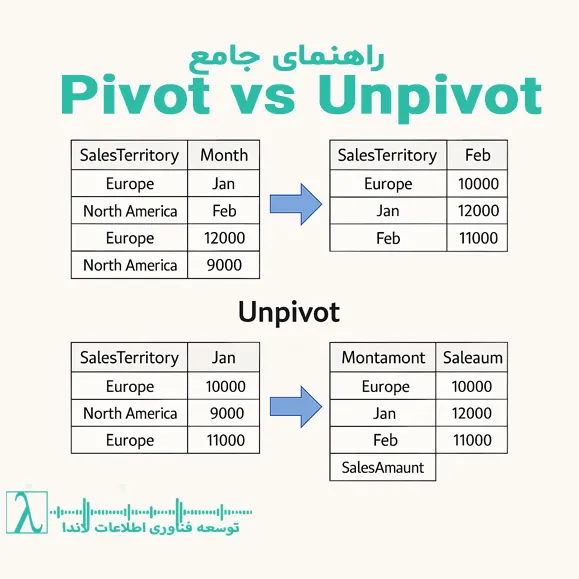
در دنیای تحلیل داده و هوش تجاری، یکی از بزرگترین چالشهای مهندسان داده، تبدیل دادههای عملیاتی به فرمتهای تحلیلپذیر است. سیستمهای تراکنشی معمولاً دادهها را در قالب جداول عریض (Wide Format) ذخیره میکنند تا فرآیند ثبت سریعتر انجام شود، اما موتورهای تحلیلی و مدلهای ستونی برای پردازش بهینه، به دادههای طویل (Long Format) نیاز دارند. این شکاف ساختاری، گلوگاهی جدی در مسیر آمادهسازی دادهها ایجاد میکند. ابزار Power Query با ارائه عملیاتهای Pivot و Unpivot، این شکاف را پر میکند و به مهندسان اجازه میدهد تا بدون نوشتن کدهای پیچیده، ساختار دادهها را بازآرایی کنند. در این مقاله تخصصی، ما از سطح مقدماتی فراتر میرویم و به کالبدشکافی فنی این توابع، بررسی تأثیر آنها بر Query Folding، مدیریت حافظه در موتور M، و پیادهسازی سناریوهای پیچیده با دیتابیس AdventureWorksDW میپردازیم. هدف ما درک عمیق معماری داده و حل مسئله ناهمخوانی ساختارهاست.
اهمیت استراتژیک Pivot و Unpivot در معماری داده
بسیاری از کاربران تصور میکنند که Pivot و Unpivot صرفاً ابزارهایی بصری برای تغییر ظاهر جداول هستند، اما از دیدگاه معماری داده، این عملیاتها ستون فقرات نرمالسازی و آمادهسازی مدلهای ستارهای (Star Schema) تشکیل میدهند. وقتی شما با دادههای واقعی روبرو میشوید، متوجه میشوید که ساختار ذخیرهسازی دادهها همیشه با نیازهای بصریسازی همسویی ندارد و این ناهمخوانی، هزینههای سنگینی را به زیرساخت تحمیل میکند.
- الزامات موتور VertiPaq: موتور فشردهسازی Power BI بر اساس الگوریتمهای ستونی کار میکند. اگر دادهها در قالب عرضی باشند، موتور باید برای هر ستون جدید یک دیکشنری مجزا بسازد که این امر باعث افزایش شدید مصرف حافظه و کاهش ضریب فشردهسازی میشود. Unpivot با تبدیل دادهها به فرمت طولی، تکرار مقادیر را در یک ستون متمرکز کرده و ضریب فشردهسازی را به شکل چشمگیری افزایش میدهد.
- انعطافپذیری در گزارشهای مقایسهای: زمانی که مدیران نیاز به تحلیل روندها در طول زمان دارند، ساختار عرضی (Pivoted) خوانایی بصری بهتری ارائه میدهد. اما برای فیلتر کردن، اسلایسر گذاشتن و محاسبات DAX پویا، ساختار طولی (Unpivoted) الزام دارد. بنابراین، مهندس داده باید بداند در کدام لایه از ETL باید از کدام عملیات استفاده کند تا هم نیاز کسبوکار برطرف شود و هم عملکرد مدل حفظ گردد.
- کاهش پیچیدگی روابط (Relationships): در مدلسازی ابعاد، گاهی اوقات دادههای عریض باعث ایجاد روابط چندبهچند یا نیاز به جداول پل (Bridge Tables) میشوند. با استفاده از Unpivot، میتوانیم ابعاد را به درستی تفکیک کرده و یک مدل تمیز، بهینه و قابل نگهداری بسازیم.
پیشنهاد مطالعه: آموزش Pivot و Unpivot در SQL Server با مثال Northwind راهنمای کامل، کاربردی و قابلاستفاده
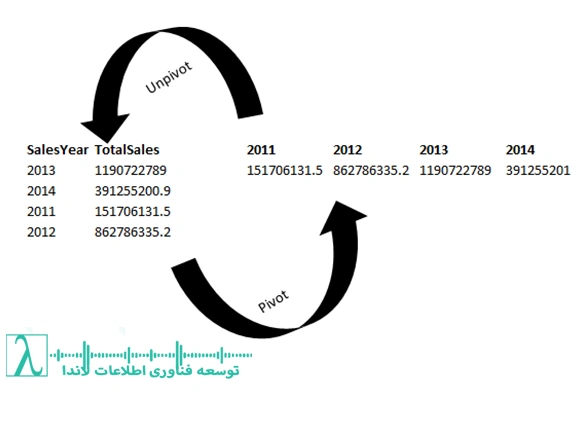
مبانی نظری و تفاوت فرمتهای داده
برای درک عمیقتر، باید ابتدا تفاوت ماهوی فرمتهای داده را بررسی کنیم. هر فرمت برای یک هدف خاص طراحی شده است و انتخاب اشتباه، فرآیند تحلیل را با بنبست مواجه میکند.
| عملیات | تعریف ساده | نتیجه نهایی |
|---|---|---|
|
Pivot |
«ستونها» را تبدیل به «سرستون» کن |
Wide Format |
|
Unpivot |
«ستونهای انتخابی» را تبدیل به سطر کن |
Long Format |
کالبدشکافی فنی و عملکرد داخلی در موتور M
وقتی شما در محیط رابط کاربری دکمه Pivot یا Unpivot را فشار میدهید، موتور M در پشت صحنه توابع خاصی را فراخوانی میکند. درک این توابع برای دیباگ کردن و بهینهسازی کوئریها حیاتی است. موتور M بر اساس اصل ارزیابی تنبل (Lazy Evaluation) کار میکند؛ این بدان معناست که توابع Pivot و Unpivot تا زمانی که شما خروجی نهایی را درخواست نکنید یا دادهها را بارگذاری نکنید، اجرا نمیشوند. این ویژگی به موتور اجازه میدهد تا مراحل مختلف را بهینهسازی کرده و عملیاتهای تکراری را حذف کند.
تحلیل تابع Table.Pivot
- ورودیها و پارامترها: این تابع یک جدول، نام ستون کلید (Key Column)، نام ستون مقدار (Value Column) و یک تابع تجمیعی (Aggregate Function) را دریافت میکند. وجود تابع تجمیعی نشان میدهد که اگر چندین رکورد برای یک کلید وجود داشته باشد، موتور M چگونه باید آنها را ترکیب کند.
- مکانیزم اجرا: موتور ابتدا دادهها را بر اساس ستون کلید گروهبندی میکند. سپس برای هر مقدار یکتا، یک ستون جدید در حافظه اختصاص میدهد و مقادیر را در آن قرار میدهد. این فرآیند نیازمند اسکن کامل دادههاست و اگر دادهها حجیم باشند، گلوگاه ایجاد میکند.
- پیچیدگی زمانی و فضایی: پیچیدگی این عملیات O(n·k) است که n تعداد سطرها و k تعداد مقادیر یکتا در ستون کلید است. اگر k بسیار بزرگ باشد (مثلاً Pivot کردن ستون تاریخ)، تعداد ستونهای خروجی سر به فلک میکشد و موتور با خطای Memory Limit مواجه میشود.
تحلیل توابع Table.UnpivotOtherColumns و UnpivotColumns
- تفاوت رویکردها: تابع UnpivotColumns لیست ستونهایی را که باید تبدیل به سطر شوند میگیرد، اما UnpivotOtherColumns لیست ستونهایی را میگیرد که باید ثابت بمانند و بقیه را Unpivot میکند. در سناریوهای واقعی که تعداد ستونها متغیر است، استفاده از UnpivotOtherColumns پویایی بیشتری ایجاد میکند.
- مکانیزم ماتریسی و Query Folding: این تابع با یک چرخش ماتریسی، ستونها را میخواند و برای هر ستون، یک سطر جدید با نام ستون و مقدار آن ایجاد میکند. نکته بسیار مهم این است که اگر منبع داده شما SQL Server باشد، موتور M این عملیات را به دستور T-SQL UNPIVOT ترجمه میکند و Query Folding به طور کامل حفظ میگردد.
- پیچیدگی: پیچیدگی زمانی O(n·m) است که m تعداد ستونهای Unpivot شده است. از آنجا که این عملیات فقط ساختار را تغییر میدهد و محاسبات سنگینی انجام نمیدهد، معمولاً بسیار سریع اجرا میشود.
پیادهسازی عملی و سناریوهای پیچیده در AdventureWorksDW
برای درک بهتر، بیایید یک سناریوی واقعی را با دیتابیس AdventureWorksDW بررسی کنیم. فرض کنید میخواهیم گزارش فروش ماهانه را برای هر قلمرو فروشگاهی (Sales Territory) تحلیل کنیم.
گام اول: آمادهسازی و فراخوانی داده
let Source =
Sql.Database(“YourServer”, “AdventureWorksDW2019″), SalesFact = Source{[Schema=”dbo”,Item=”FactResellerSales”]}[Data], FilteredColumns = Table.SelectColumns(SalesFact, {“SalesTerritoryKey”,”OrderDateKey”,”SalesAmount”})
in
FilteredColumns
در این مرحله، ما فقط ستونهای ضروری را فراخوانی میکنیم. این کار باعث میشود Query Folding به درستی کار کند و حجم دادههای منتقل شده از سرور SQL به موتور Power Query کاهش یابد.
گام دوم: سناریوی Pivot (گزارش فروش ماهانه)
-
- تبدیل
OrderDateKeyبه ماه و سال:
- تبدیل
AddDate = Table.AddColumn(FilteredColumns, “Month”, each Date.MonthName(Date.FromText(Text.From([OrderDateKey]))), type text)
در اینجا ما یک ستون محاسباتی اضافه میکنیم. توجه داشته باشید که اگر این تبدیل را در سمت سرور SQL انجام دهیم، عملکرد بهتری خواهد داشت، اما برای آموزش مفاهیم M، آن را در Power Query انجام میدهیم.
- اجرای عملیات Pivot:
PivotedTable = Table.Pivot( Table.TransformColumnTypes(AddDate, {{“SalesAmount”, type number}}), List.Distinct(AddDate[Month]), “Month”, “SalesAmount”, List.Sum )
در این کد، ما ابتدا نوع داده SalesAmount را تضمین میکنیم. سپس لیست مقادیر یکتای ماه را به عنوان ستونهای جدید استخراج میکنیم و در نهایت از تابع List.Sum برای تجمیع فروش استفاده میکنیم.
- خروجی:
| SalesTerritoryKey | January | February | … |
این خروجی برای گزارشهای مقایسهای عالی است، اما برای استفاده در اسلایسرهای Power BI مناسب نیست.
گام سوم: سناریوی Unpivot (دادههای آماده تحلیل و مدلسازی)
- فرض کنید جدولی با ستونهای ماهانه از یک فایل اکسل وارد کردهاید:
| Territory | Jan | Feb | Mar | - اجرای عملیات Unpivot:
Unpivoted = Table.UnpivotOtherColumns( MonthWideTable, {“Territory”}, “Month”, “SalesAmount” )
این تابع تمام ستونها به جز Territory را میگیرد و آنها را به دو ستون Month و SalesAmount تبدیل میکند.
- خروجی:
| Territory | Month | SalesAmount |
اکنون دادهها در فرمت طولی قرار دارند و میتوانیم به راحتی آنها را به جدول ابعاد تاریخ متصل کنیم و مدل ستارهای بسازیم.
چالشهای بهینهسازی و معماری ETL
کارشناسان ارشد داده میدانند که استفاده از Pivot و Unpivot بدون در نظر گرفتن معماری زیرساخت، کندی شدید فرآیند Refresh و خطاهای حافظه را به همراه دارد. در ادامه، اصول کلیدی طراحی ETL را بررسی میکنیم.
مدیریت انواع داده در موتور VertiPaq
- مدیریت نوع داده و خطاهای VertiPaq: موتور M پس از عملیات Unpivot، یک ستون جدید با نوع Any یا Text ایجاد میکند. اگر کاربر این ستون را به نوع مناسب (
type number،type date) تبدیل نکند، موتور VertiPaq فشردهسازی بهینهای انجام نمیدهد و حتی هنگام بارگذاری خطا گزارش میدهد. مهندسان داده همیشه در اولین گام بعد از Unpivot، ازTable.TransformColumnTypesاستفاده میکنند. - تأثیر ناهمخوانی نوع داده در Unpivot: اگر ستونهای مبدأ انواع داده متفاوتی داشته باشند (مثلاً یکی Integer و دیگری Text)، موتور M همه آنها را به یک نوع مشترک (معمولاً Text) تبدیل میکند. این عمل فشردهسازی VertiPaq را کاملاً نابود میکند. بنابراین، متخصصان قبل از Unpivot، نوع تمام ستونهای مبدأ را یکسانسازی میکنند.
حفظ Query Folding و معماری سرور منبع
- حفظ Query Folding: مهندسان داده اغلب Query Folding را میشکنند که یکی از بزرگترین اشتباهات در این حوزه است. عملیات Unpivot معمولاً Query Folding را حفظ میکند و پردازش را به سمت سرور منبع هل میدهد، اما Pivot اغلب این قابلیت را از بین میبرد. بنابراین، متخصصان فیلترهای سنگین و تغییرات ساختاری را تا حد امکان در سمت سرور منبع (از طریق View یا Stored Procedure) انجام میدهند و فقط تغییرات نهایی را در Power Query اعمال میکنند.
مدیریت حافظه و بهینهسازی عملکرد
- مدیریت خطای OutOfMemory: اگر کاربر با دادههای بسیار حجیم (مثلاً چند صد میلیون سطر) کار کند، عملیات Pivot رم سرور را پر میکند. در این سناریوها، مهندسان داده به جای Pivot کردن در Power Query، از تکنیکهای Incremental Refresh استفاده میکنند یا دادهها را در لایههای مختلف پارتیشنبندی میکنند.
- استفاده از Table.Buffer در سناریوهای خاص: اگر دادهها کوچک باشند و کاربر بخواهد از ارزیابی مجدد آنها در هر مرحله جلوگیری کند، قبل از Pivot یا Unpivot از تابع
Table.Bufferاستفاده میکند. این تابع دادهها را در حافظه رم بارگذاری میکند و از ارتباط مکرر با سرور منبع جلوگیری میکند. اما استفاده نابجا از این تابع برای دادههای حجیم، رم را پر میکند و عملکرد را به شدت کاهش میدهد.
عیبیابی و شناسایی گلوگاهها
- استفاده از Diagnostics: متخصصان برای شناسایی گلوگاهها، حتماً از تب View و گزینههای Diagnostics استفاده میکنند. آنها با فعال کردن Stage Diagnostics، دقیقاً میبینند کدام مرحله از Unpivot یا Pivot بیشترین زمان را به خود اختصاص میدهد و آیا Query Folding در آن مرحله شکسته است یا خیر.
تحلیل تطبیقی و معماری مدلسازی
انتخاب بین Pivot و Unpivot نباید بر اساس سلیقه شخصی باشد، بلکه باید بر اساس الزامات معماری مدل و نیازهای نهایی کسبوکار انجام شود. جدول زیر این تصمیمگیری را تسهیل میکند:
| موقعیت و سناریو | استفاده از Pivot | استفاده از Unpivot |
|---|---|---|
| ساخت گزارش مقایسهای ماتریسی |
✔ |
✖ |
| آمادهسازی Data Model برای DAX |
✖ |
✔ |
| پایش خطاهای ماهانه و ناهنجاریها |
✔ |
✔ (برای سازگارسازی و فیلتر) |
| ستونهای پویا (مثلاً تاریخ یا محصول) | ✖ (سبب ایجاد تعداد زیاد ستون و مصرف رم) |
✔ |
| اتصال به جداول ابعاد (Dimension Tables) |
✖ |
✔ |
جمعبندی تحلیلی و گامهای بعدی
عملیاتهای Pivot و Unpivot در Power Query صرفاً ابزارهایی برای تغییر شکل جداول نیستند؛ بلکه راهکارهایی استراتژیک برای حل مسئله ناهمخوانی ساختار دادههای عملیاتی و تحلیلی تشکیل میدهند. یک مهندس داده حرفهای میداند که استفاده نابجا از این توابع میتواند مدل داده را سنگین، کند و غیرقابل نگهداری کند. با درک عمیق از مکانیسم داخلی موتور M، مدیریت دقیق نوع دادهها، و رعایت اصول Query Folding، شما میتوانید معماری ETL خود را به گونهای طراحی کنید که هم سرعت بارگذاری را تضمین کند و هم خوانایی گزارشها را برای ذینفعان افزایش دهد. بهینهسازی این فرآیندها، مرز بین یک داشبورد معمولی و یک راهکار هوش تجاری سازمانی است. برای مطالعه بیشتر در زمینه اصول بهینهسازی، میتوانید به مقاله بهینهسازی مراجعه کنید.
سوالات متداول تخصصی (FAQ)
۱. آیا میتوان همزمان دو ستون را pivot کرد و خروجی چندبعدی داشت؟
خیر، تابع Table.Pivot در زبان M صرفاً یک ستون کلید (Key) و یک ستون مقدار (Value) را در هر اجرا میپذیرد. اگر به یک خروجی چندبعدی نیاز دارید، باید این عملیات را در چند مرحله مجزا انجام دهید یا از توابع پیشرفتهتر گروهبندی برای ایجاد ساختارهای تودرتو (Nested Tables) استفاده کنید و سپس آنها را گسترش دهید.
۲. بعد از Unpivot، چگونه خطاهای پنهان و ناهنجاریهای داده را شناسایی کنیم؟
دادههای ورودی از منابع مختلف ممکن است دارای کاراکترهای غیرقابل چاپ یا فرمتهای اشتباه باشند. پس از Unpivot، حتماً از قابلیت Keep Errors یا Remove Errors استفاده کنید. همچنین، تابع Table.Profile در بسته Power Query SDK یا استفاده از Column Distribution در تب View به شما کمک میکند تا توزیع دادهها، مقادیر Null و خطاهای تایپی را به صورت آماری بررسی کنید.
۳. آیا رفتار Pivot/Unpivot در Power BI Desktop و Excel Power Query متفاوت است؟
خیر، موتور پردازشی و توابع M در هر دو محیط کاملاً یکسان هستند و از یک کامپایلر مشترک استفاده میکنند. تفاوت تنها در رابط کاربری (UI) و نحوه نمایش پانل Applied Steps است. اما از آنجا که Excel معمولاً روی فایلهای محلی کار میکند و Power BI به سرویسهای ابری متصل است، محدودیتهای حافظه و Gateway در Excel ممکن است متفاوت ظاهر شود.
۴. چرا پس از Unpivot، حجم فایل PBIX من به جای کاهش، افزایش یافت؟
این اتفاق معمولاً به دلیل عدم تبدیل نوع داده (Data Type) رخ میدهد. وقتی شما ستونهای مختلف را Unpivot میکنید، موتور M ستون جدید را با نوع Any یا Text میسازد. اگر شما آن را به Number یا Date تبدیل نکنید، VertiPaq نمیتواند از الگوریتمهای فشردهسازی ستونی استفاده کند و هر مقدار را به صورت یک رشته متنی جداگانه ذخیره میکند که حجم را به شدت افزایش میدهد.
تحلیل معماری و مشاوره تخصصی با لاندا
طراحی یک معماری داده بهینه و پیادهسازی فرآیندهای ETL کارآمد، نیازمند دانش عمیق و تجربه عملی در سناریوهای پیچیده سازمانی است. اگر در پروژههای هوش تجاری خود با چالشهای عملکردی، مدلسازی داده یا بهینهسازی Power Query مواجه هستید، تیم متخصص ما آماده ارائه راهکارهای مسئلهمحور است.
یادداشت بهروزرسانی:
این مقاله در راستای ارتقای سطح کیفی و انطباق با استانداردهای تخصصی توسعه فناوری اطلاعات لاندا، در خرداد ماه 1405 بازبینی و بازنویسی شده است.
- تغییر رویکرد از ابزارمحوری به مسئلهمحوری: لحن مقاله از حالت آموزش صرفِ ابزار، به رویکرد تحلیلی، مشاورهای و معماری داده تغییر یافت تا چالشهای واقعی مهندسان داده در سناریوهای سازمانی پوشش داده شود.
- افزایش عمق فنی و تخصصی: مباحث جدیدی نظیر تحلیل عملکرد موتور VertiPaq، مدیریت Query Folding، پیچیدگی زمانی/فضایی توابع M و مفهوم ارزیابی تنبل (Lazy Evaluation) به بدنه مقاله افزوده شد.
- توسعه بخشهای عیبیابی و بهینهسازی: نکات پیشرفتهای برای مدیریت خطاهای حافظه (OutOfMemory)، استفاده از
Table.Bufferو یکپارچهسازی نوع دادهها پیش از Unpivot اضافه گردید. - تکمیل سوالات متداول (FAQ): یک سوال بسیار کاربردی و رایج درباره «افزایش بیدلیل حجم فایل PBIX پس از Unpivot» به بخش پرسشهای متداول اضافه شد تا گرههای کورتری از مخاطب باز شود.



No comment