 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید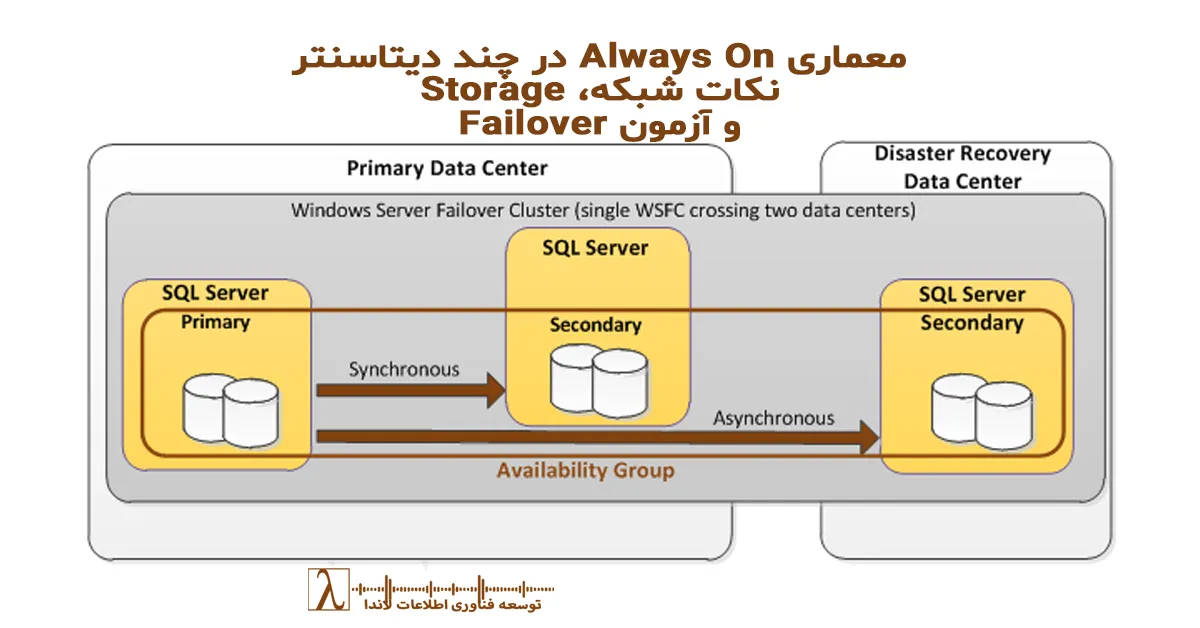
اگر در سازمان شما دیتابیس SQL Server باید همیشه در دسترس باشد، داشتن یک معماری Always On که در چند دیتاسنتر پخش شده باشد، معمولاً تنها راهکار واقعی برای High Availability و Disaster Recovery است. اما پیادهسازی صحیح یک Distributed Always On با دو یا سه سایت (Site A، Site B و حتی Site C بهعنوان DR) چیزی فراتر از فعال کردن AG و ساخت Listener است.
این معماری، وقتی واقعاً پای کار میآید، به سه ستون اصلی وابسته است:
- شبکه و Latency
- Storage و رفتار I/O
- پروتکلهای Failover و تستهای دورهای
در این مقاله بهجای توضیحات تکراری، دقیقاً سراغ نکاتی میرویم که در پروژههای واقعی HA چند سایتی باعث موفقیت یا خرابی معماری شدهاند. همراه با یک چکلیست عملی برای اطمینان از اینکه محیط Always On شما واقعاً آماده Failover است.
پیشنهاد مطالعه: چگونه Lag و Latency را در Availability Group مدیریت کنیم
چرا Always On چند دیتاسنتر متفاوت از AG معمولی است؟
در معماریهای تکسایتی، با یک یا دو Replica، شبکه سریع است، Storage یکسان است و Replicaها معمولاً در یک Subnet هستند. اما در نسخه چند سایتی:
- دیتاسنترها IP و Subnet متفاوت دارند.
- Latency شبکه معمولاً بالاتر از ۱–5ms است.
- رفتار Storage در هر سایت ممکن است متفاوت باشد.
- Quorum باید با دقت طراحی شود.
- Listener باید Multi-Subnet باشد.
- امنیت شبکه (Firewall و Routing) پیچیده میشود.
به همین دلیل است که بسیاری از شرکتها Always On را «فعال» میکنند، ولی معماریشان در عمل HA واقعی نیست.
شبکه (Network)، قلب Always On چند دیتاسنتر
۱. Latency بین دیتاسنترها
Latency بهترین معیار سلامت AG است.
مقادیر پیشنهادی:
- Synchronization mode ( synchronous ) → زیر 5ms (ایدهآل ۱–2ms)
- Asynchronous → هر مقداری که زیر 80ms باشد قابل قبول است.
اگر latency زیاد باشد:
- Queueهای AG بزرگ میشوند.
- Secondary دائما lag دارد.
- Failover زمانبر یا غیرقابل پیشبینی میشود.
نکته مهم: سازمانها معمولاً Replicas را سینک میکنند «فقط چون گزینهاش وجود دارد»، اما در معماری Multi-DC تنها ۱ Pair باید Synchronous باشد و بقیه Asynchronous.
۲. Multi-Subnet Listener
برای چند دیتاسنتر باید Listener را Multi-Subnet بسازید:
- RegisterAllProvidersIP = 1
- MultiSubnetFailover = True (در Connection String)
اگر این پارامترها درست تنظیم نشود:
- کلاینتها پس از Failover تا ۲۰–۳۰ ثانیه قطع میشوند.
- کاربران تصور میکنند Failover ناموفق بوده است.
۳. Firewall و Routing
در بسیاری از Failoverهای ناموفق مقصر شبکه است، نه SQL.
موارد حیاتی:
- پورتهای ۵۰۲۲، ۱۴۳۳، ۵۹۹۹۹، RPC، WMI
- عبور ترافیک بین VLANهای سایتها
- NAT و ترجمه آدرسها
- ALB/SLB برای Listener
چکلیست انتهای مقاله این بخش را کاملتر بیان میکند.
Storage، تفاوت دیتاسنترها یعنی تفاوت عملکرد Always On
۱. I/O Secondary باید حداقل ۸۰٪ Primary باشد
اگر Storage سایت دوم کندتر باشد:
- Secondary همیشه عقب میماند.
- Failover باعث افت Performance میشود.
- در سناریوهای synchronous، سرعت Primary هم پایین میآید.
این نکته را بسیاری از تیمهای IT نادیده میگیرند.
۲. اندازه Log مهمتر از سرعت CPU
AG همیشه اول Log را replicate میکند.
اگر Log Drive سایت دوم کند باشد:
- Log Send Queue بالا میرود.
- Commit در حالت synchronous طولانی میشود.
- کاربران تأخیر حس میکنند.
۳. سرور DR را همرده Primary بسازید.
سرور DR برای «روز فاجعه» است، اما همان روز نباید کندتر باشد!
در پروژهها موارد زیادی دیده میشود که:
- Primary با Storage NVMe
- DR با SAN معمولی
این معماری فقط روی کاغذ HA است.
Quorum، بخش حیاتی که معمولا اشتباه تنظیم میشود.
در معماری چند دیتاسنتر، انتخاب Quorum بیشتر از هر چیز بر موفقیت Failover تاثیر دارد.
الگوهای پیشنهادی:
الگوی دو دیتاسنتر (Active/DR):
- Node1 – Site A
- Node2 – Site B
- File Share Witness – Site A یا Cloud Witness
الگوی سه دیتاسنتر (Active/Standby/DR):
- Node1 – Site A
- Node2 – Site B
- Node3 – Site C
- Cloud Witness (بهترین گزینه)
Cloud Witness بیشترین پایداری را ایجاد میکند.
Failover، آزمونی که کمتر کسی واقعاً انجام میدهد.
Failover واقعی با جابهجایی بین دیتاسنتر، فقط وقتی معتبر است که اندازهگیری شود.
تستهایی که باید انجام شوند:
۱. تست زمان قطع سرویس (Failover Time)
- با DNS propagation
- بدون DNS propagation
هدف: کمتر از ۱۰–۱۵ ثانیه برای Multi-Subnet Listener
۲. بررسی Data Loss در حالت Asynchronous
چک کنید:
- Log Send Queue
- Estimated Data Loss
اگر Loss بیش از ۵ ثانیه باشد، Replica برای DR مناسب نیست.
۳. تست Load پس از Failover
کاربران باید روی Replica جدید همان Performance را حس کنند:
- تست Queryهای TCPU
- تست OLTP
- تست DWH ETL
چکلیست سریع قبل از تحویل معماری Always On چند دیتاسنتر
Network
- Latency زیر 5ms برای synchronous
- Listener Multi-Subnet
- MultiSubnetFailover=true
- پورتهای AG و SQL باز
- ارتباط دائمی بین Subnetها
Storage
- سرعت I/O سایتها نزدیک به هم
- Log Drive سریع در تمام Replicaها
- TempDB همرده Primary
Quorum
- Witness مناسب (Cloud یا File Share)
- Voting درست تقسیم شده
- Site Failover بدون رفتن به حالت Split-Brain
Failover
- اندازهگیری زمان Failover
- تست Under Load
- بررسی Data Loss
- بررسی رفتار Client بعد از Failover
نتیجهگیری
معماری Always On در چند دیتاسنتر یکی از پیچیدهترین پروژههای HA است. موفقیت آن وابسته است به:
- یک شبکه پایدار
- Storage همسطح
- تنظیم Quorum صحیح
- و مهمتر از همه تستهای واقعی Failover
اگر این چهار ستون درست طراحی و پیادهسازی شوند، شما یک معماری HA خواهید داشت که در شرایط واقعی (از قطعی برق تا خرابی SAN) واقعاً از کسبوکار محافظت میکند.
سوالات متداول (FAQ)
۱. آیا میتوان همه Replicaها را synchronous کرد؟
بههیچوجه، در Multi-DC فقط Replica داخل همان دیتاسنتر باید synchronous باشد. بقیه asynchronous.
۲. اگر سایت DR خیلی دور باشد، چه کنیم؟
فقط حالت asynchronous و Data Loss باید در بازه قابل قبول باشد.
۳. آیا Always On جایگزین Backup است؟
خیر، Backup سیاست جداگانه است و حتی در HA سهسایتی اجباری است.
۴. Listener در دو دیتاسنتر قطع میشود—مشکل چیست؟
احتمال ۹۹٪ تنظیم نبودن MultiSubnetFailover یا مشکل در DNS/A-Record.
تماس و مشاوره با لاندا در خصوص تخصصی “HA چندسایتی” برای سازمانها
اگر معماری Always On شما:
- Failover ناموفق دارد.
- Replicaها Lag دارند.
- Listener دیر متصل میشود.
- یا قصد راهاندازی معماری سهسایتی دارید.
توسعه فناوری اطلاعات لاندا میتواند کل معماری شبکه، Storage، Quorum، Listener، تست Failover و DR را برای شما تحلیل، بهینه و مستندسازی کند.
برای دریافت مشاوره تخصصی HA چندسایتی، با مشاوران لاندا تماس ✆ بگیرید.




نظری داده نشده