 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید
در بسیاری از سازمانها، زمانی که کاربران از کندی سیستمها شکایت میکنند، نگاهها به سمت دیتابیس برمیگردد. اما مشکل اصلی اغلب نه خود دیتابیس، بلکه تحلیل اشتباه Performance آن است. تصمیمهایی که بر پایه برداشتهای سطحی گرفته میشوند، میتوانند هزینههای سنگین مالی، اتلاف زمان تیم فنی و حتی اختلال در سرویسهای حیاتی سازمان را به دنبال داشته باشند.
ارتقای بیدلیل سختافزار، تغییرات شتابزده در معماری، یا اجرای پروژههای پرریسک برای مهاجرت، در بسیاری از موارد نتیجه یک تحلیل ناقص از وضعیت واقعی Performance است. در این مقاله، نشانههای رایجی را بررسی میکنیم که نشان میدهند رویکرد فعلی شما در تحلیل Performance دیتابیس نیاز به بازنگری جدی دارد.
تمرکز بیش از حد بر CPU و RAM و نادیده گرفتن گلوگاههای واقعی
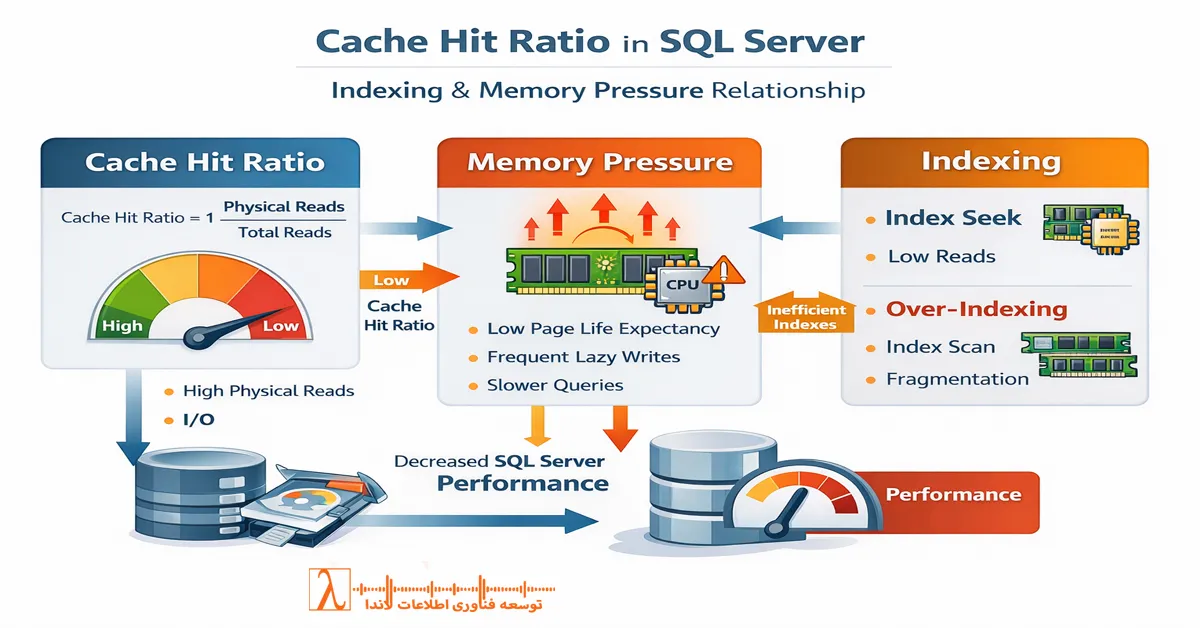
یکی از اولین خطاها زمانی رخ میدهد که سلامت دیتابیس صرفا با دو شاخص CPU و RAM سنجیده میشود. این دو معیار مهم هستند، اما بهتنهایی تصویر دقیقی از وضعیت Performance ارائه نمیدهند.
مصرف پایین CPU لزوما به معنای عملکرد مناسب نیست. در بسیاری از سناریوها، Queryها نه در حال پردازش، بلکه در حال انتظار برای I/O دیسک یا آزاد شدن Lock هستند. در چنین حالتی، CPU بیکار است اما کاربران همچنان کندی را تجربه میکنند. از طرف دیگر، مصرف بالای CPU نیز همیشه نشانه بحران نیست و ممکن است نتیجه پردازشهای تحلیلی ضروری باشد.
در یک نمونه واقعی، دیتابیسی با CPU زیر ۳۰ درصد با شکایت گسترده کاربران مواجه بود. بررسی دقیقتر نشان داد عامل اصلی، تاخیر در Storage و Wait Typeهای مرتبط با I/O بود. بنابراین تمرکز صرف بر CPU باعث شده بود ریشه مشکل کاملا نادیده گرفته شود.
اتکای کامل به داشبوردهای Monitoring بدون تحلیل فنی عمیق
ابزارهای Monitoring دید مناسبی از وضعیت کلی سیستم میدهند، اما زمانی که جای تحلیل تخصصی را میگیرند، به منبع خطا تبدیل میشوند. داشبوردها معمولا دادهها را خلاصه و میانگینگیری میکنند و همین موضوع میتواند رفتارهای غیرعادی یا Queryهای مسئلهدار را پنهان کند.
ممکن است میانگین زمان پاسخ مناسب باشد، اما یک Query خاص با Execution Plan بسیار پرهزینه در ساعات اوج بار، کل سیستم را تحت تاثیر قرار دهد. این نوع مشکلات در نمودارهای کلی دیده نمیشوند و فقط با بررسی جزئیات فنی قابل شناسایی هستند.
Monitoring باید نقطه شروع تحلیل باشد، نه پایان آن. تصمیمگیری بدون بررسی Execution Plan و الگوی واقعی مصرف منابع، ریسک تشخیص اشتباه را به شدت افزایش میدهد.
نادیده گرفتن Wait Stats و نشانههای داخلی موتور دیتابیس
SQL Server و سایر موتورهای دیتابیس، اطلاعات دقیقی درباره این که Queryها منتظر چه منبعی هستند ثبت میکنند. این اطلاعات در قالب Wait Stats ارائه میشود و یکی از مهمترین ابزارها برای شناسایی Bottleneck واقعی است.
زمانی که تیم فنی فقط زمان اجرای Query را میبیند، اما بررسی نمیکند این زمان صرف انتظار برای چه منبعی شده، تحلیل ناقص باقی میماند. برای مثال، Waitهای مربوط به PAGEIOLATCH معمولا نشاندهنده مشکل در I/O دیسک هستند، در حالی که Waitهای مرتبط با Lock میتوانند نشانه طراحی نامناسب تراکنشها یا ایندکسها باشند.
نادیده گرفتن این دادهها مانند تلاش برای درمان یک بیماری بدون انجام آزمایشهای تشخیصی است.
تمرکز اشتباه فقط بر Queryهای کند
یکی دیگر از نشانههای تحلیل نادرست، تمرکز صرف بر Queryهایی است که زمان اجرای بالایی دارند. در حالی که در بسیاری از سیستمهای عملیاتی، Queryهای کوتاه اما بسیار پرتکرار، فشار اصلی را بر CPU و I/O وارد میکنند.
یک Query با زمان اجرای ۵۰ میلیثانیه که میلیونها بار در روز اجرا میشود، میتواند تاثیر بسیار بیشتری نسبت به یک Query ۵ ثانیهای با تعداد اجرای محدود داشته باشد. اگر فقط به زمان اجرای بالا نگاه شود، این مصرفکنندگان پنهان منابع هرگز شناسایی نخواهند شد.
تحلیل صحیح باید ترکیبی از تعداد اجرا، مدت اجرا و میزان مصرف منابع باشد.
وجود Indexهای زیاد و تصور اشتباه بهبود Performance
بسیاری از تیمها تصور میکنند هرچه تعداد Index بیشتر باشد، Performance بهتر خواهد شد. در حالی که Index بیش از حد میتواند به یک مانع جدی برای عملیات نوشتن تبدیل شود.
هر عملیات Insert، Update یا Delete باید همه Indexهای مرتبط را بهروزرسانی کند. در دیتابیسهایی که سالها بدون بازبینی رشد کردهاند، معمولا Indexهای متعددی وجود دارند که یا هرگز استفاده نمیشوند یا کاربرد بسیار محدودی دارند، اما همچنان هزینه نگهداری ایجاد میکنند.
در یک پروژه بهینهسازی، دیتابیسی با صدها Index بررسی شد و مشخص شد بخش بزرگی از آنها عملا بلااستفاده هستند. پس از حذف و بازطراحی ساختار Indexها، زمان تراکنشهای عملیاتی به شکل محسوسی کاهش یافت.
رویکرد واکنشی به جای پایش مستمر
اگر تحلیل Performance فقط زمانی انجام شود که کاربران شکایت میکنند، سازمان همیشه یک قدم عقبتر از مشکل خواهد بود. بسیاری از مسائل Performance به صورت تدریجی و در طول زمان ایجاد میشوند؛ رشد حجم داده، تغییر الگوی استفاده، افزایش Fragmentation و بزرگ شدن فایلهای Log از جمله این موارد هستند.
بدون داشتن Baseline از وضعیت نرمال سیستم و تحلیل روندهای تاریخی، تشخیص این انحرافها بسیار دشوار خواهد بود. نتیجه این میشود که مشکلات زمانی شناسایی میشوند که به مرحله بحران رسیدهاند.
اتکای صرف به Alertها و Thresholdهای عددی
Alertها ابزارهای مفیدی هستند، اما تنها زمانی که در کنار تحلیل روندی استفاده شوند. Thresholdهای از پیش تعریفشده همیشه با واقعیت هر سازمان همخوانی ندارند.
ممکن است یک شاخص هرگز از حد تعیینشده عبور نکند، اما افزایش تدریجی آن در طول چند ماه، تجربه کاربری را به شدت تحت تاثیر قرار دهد. این نوع افت تدریجی معمولا از دید Alertهای ساده پنهان میماند.
بیتوجهی به Execution Plan و بهینهسازی Query
گاهی ریشه اصلی مشکل، نه در سختافزار و نه در حجم داده، بلکه در نحوه اجرای یک Query کلیدی است. Execution Plan نشان میدهد موتور دیتابیس چگونه به داده دسترسی پیدا میکند و چه عملیاتی انجام میدهد.
Table Scanهای غیرضروری، Lookupهای تکراری، تخمینهای اشتباه به دلیل Statistics قدیمی و انتخاب نامناسب روش Join میتوانند بار سنگینی ایجاد کنند. بدون بررسی این Planها، بسیاری از تیمها به اشتباه سراغ ارتقای سرور میروند، در حالی که مشکل با بازنویسی یک Query یا ایجاد یک Index هدفمند قابل حل است.
نادیده گرفتن تاثیر لایههای زیرساخت و اپلیکیشن
Performance دیتابیس همیشه فقط به خود دیتابیس مربوط نیست. تاخیر در Storage اشتراکی، محدودیتهای شبکه، تنظیمات نامناسب ماشین مجازی یا طراحی غیربهینه در لایه اپلیکیشن میتوانند مستقیما بر رفتار دیتابیس اثر بگذارند.
زمانی که تحلیل فقط به داخل SQL Server محدود شود، ممکن است تیم فنی مدتها روی بخشی کار کند که اصلا منبع اصلی مشکل نیست. تحلیل صحیح باید مسیر کامل درخواست از کاربر تا دیتابیس و بالعکس را در بر بگیرد.
سوالات متداول FAQ
آیا مصرف بالای CPU همیشه نشانه مشکل Performance است؟
خیر. مصرف بالای CPU میتواند ناشی از پردازشهای تحلیلی سنگین اما طبیعی باشد. برای تشخیص مشکل واقعی باید CPU در کنار Wait Stats، I/O دیسک و الگوی اجرای Queryها بررسی شود.
چرا با وجود نرمال بودن منابع سرور، کاربران کندی احساس میکنند؟
زیرا بسیاری از مشکلات Performance به دلیل Wait روی منابعی مثل دیسک، Lockها یا شبکه ایجاد میشوند. این موارد لزوماً باعث افزایش CPU یا RAM نمیشوند اما زمان پاسخ سیستم را بالا میبرند.
آیا ابزارهای Monitoring بهتنهایی برای تحلیل Performance کافی هستند؟
خیر. ابزارهای Monitoring دید کلی میدهند، اما برای شناسایی ریشه مشکل باید Execution Plan، Queryهای پرتکرار، Indexها و Wait Stats بهصورت فنی بررسی شوند.
آیا اضافه کردن Index همیشه باعث افزایش سرعت میشود؟
خیر. Indexهای زیاد میتوانند عملیات Insert و Update را کند کنند و سربار نگهداری ایجاد کنند. طراحی Index باید بر اساس الگوی واقعی Queryها انجام شود، نه به صورت حدسی.
چرا فقط بررسی Queryهای کند کافی نیست؟
چون Queryهای سریع اما پرتکرار ممکن است در مجموع بیشترین مصرف منابع را داشته باشند. تحلیل باید ترکیبی از تعداد اجرا، مدت اجرا و مصرف منابع باشد.
چگونه میتوان Bottleneck واقعی دیتابیس را شناسایی کرد؟
با تحلیل همزمان Wait Types، Execution Plan، شاخصهای سیستمی، ساختار Indexها و روندهای تاریخی Performance میتوان گلوگاه اصلی را با دقت بالا مشخص کرد.
هر چند وقت یکبار باید تحلیل Performance انجام شود؟
در محیطهای سازمانی، پایش باید مستمر باشد و تحلیل عمیق بهصورت دورهای انجام شود. بررسی فقط در زمان بروز مشکل معمولاً دیرهنگام است و هزینه اصلاح را افزایش میدهد.
جمعبندی
نشانه مشترک همه موارد بالا این است که تحلیل Performance به صورت تکبعدی، مقطعی و بدون نگاه سیستمی انجام شده است. در چنین شرایطی، سازمان به جای حل مسئله واقعی، وارد چرخهای از تصمیمات پرهزینه و کماثر میشود.
رویکرد حرفهای به Performance یعنی تحلیل همزمان شاخصهای سیستمی، Wait Stats، رفتار Queryها، ساختار Indexها، Execution Plan و همچنین در نظر گرفتن زیرساخت و اپلیکیشن. فقط در این صورت میتوان Bottleneck واقعی را شناسایی و اقدامات اصلاحی را با اطمینان اجرا کرد.
قبل از ارتقای سختافزار، این ارزیابی Performance را انجام دهید
اگر در سازمان شما کندی سیستمها به یک مسئله تکرارشونده تبدیل شده، اگر برای هر مشکل Performance اولین راهکار مطرحشده ارتقای سختافزار است، یا اگر تیم فنی زمان زیادی صرف آزمون و خطا میکند بدون آنکه به یک علت ریشهای برسد، زمان آن رسیده که رویکرد تحلیل Performance بهصورت اساسی بازبینی شود.
یک ارزیابی تخصصی و ساختاریافته Performance میتواند گلوگاههای پنهان را شناسایی کند، از هزینههای غیرضروری جلوگیری کند و پایداری سرویسهای حیاتی را به شکل محسوسی افزایش دهد. سرمایهگذاری روی تحلیل درست، بسیار کمهزینهتر از تصمیمات اشتباهی است که بر پایه تحلیل ناقص گرفته میشوند.



نظری داده نشده