در دنیای هوش تجاری، مدیریت داده و اتوماسیون فرآیندهای ETL اهمیت حیاتی دارد. Dataflow در Power BI ابزاری قدرتمند برای ایجاد یک معماری داده متمرکز است که امکان تعریف، نگهداری و بهروزرسانی منطق استخراج و تبدیل داده (ETL) را فراهم میکند.
Dataflow در Power BI چیست؟
دیتافلو مجموعهای از موجودیتها (Entities) است که در Power BI Service تعریف میشوند و مراحل M Query برای استخراج، پاکسازی و انتقال داده را ذخیره میکنند. خروجی هر Entity بهصورت جدولی یا مدل Common Data Model (CDM) قابل دسترسی است و میتوان آن را از طریق گزارشها و ابزارهای تحلیلی مصرف کرد.
مزایا و کاربردهای Dataflow
- مدیریت متمرکز منطق ETL، تفکیک وظایف توسعه و نگهداری
- اشتراکگذاری هوشمند دادهها بین گزارشها و پروژههای مختلف
- کاهش هزینه پردازش با بهرهگیری از Query Folding و Incremental Refresh
- تسهیل یکپارچهسازی با سایر سرویسهای Azure مانند Synapse و Databricks
| مزیت | توضیحات |
|---|---|
| مقیاسپذیری | اجرای موازی مراحل و توزیع بار با Enhanced Compute Engine |
| یکپارچگی داده | خروجی CDM روی Azure Data Lake Gen2 |
| امنیت و کنترل | تعریف Row-Level Security و مدیریت دسترسی در Workspace |
| اتوماسیون | راهاندازی خودکار با REST API و PowerShell |
پیشنهاد مطالعه: ۱۰ اصل طلایی طراحی Data Model در Power BI
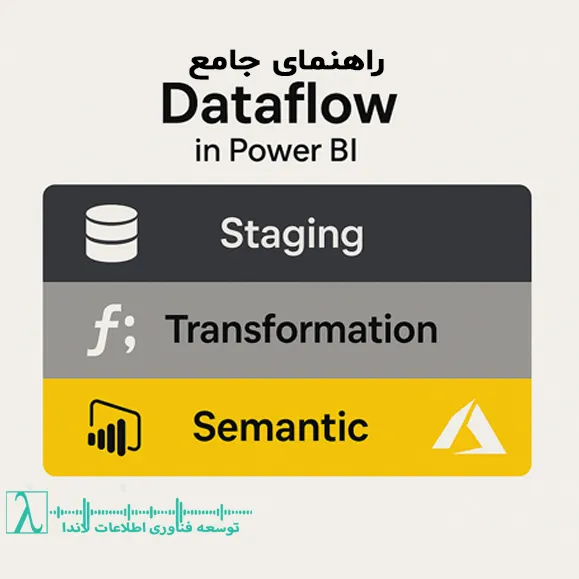
معماری لایهای Dataflow
لایه 1: Staging
در این لایه دادههای خام از منابع مختلف استخراج و فیلتر میشوند. حذف ستونهای غیرضروری در این مرحله، حجم پردازش را کاهش میدهد.
let
Source = Sql.Database(SourceServer, SourceDB),
SalesRaw = Source{[Schema="dbo",Item="Sales"]}[Data],
Filtered = Table.SelectRows(
SalesRaw,
each [SaleDate] >= DateFrom and [SaleDate] <= DateTo
)
in
Filtered
لایه 2: Transformation
با تعریف توابع سفارشی M میتوانید عملیات پیچیدهای مانند پارسکردن JSON یا محاسبات تجمیعی را انجام دهید. جداسازی هر گام در Entityهای مجزا، قابلیت تست و نگهداری را بهبود میبخشد.
تابع سفارشی برای پارسکردن JSON
(fn_ParseJson as text) as record =>
let
Parsed = Json.Document(fn_ParseJson),
Flatten = Record.ToTable(Parsed)
in
Record.FromTable(Flatten)
مثال Entity تبدیل (Trf_Sales)
let
Source = Stg_Sales,
ParsedDetails = Table.AddColumn(
Source,
"DetailsRecord",
each fn_ParseJson([SalesDetails])
),
Expanded = Table.ExpandRecordColumn(
ParsedDetails,
"DetailsRecord",
{"ProductID","Quantity","UnitPrice"}
),
Renamed = Table.RenameColumns(
Expanded,
{{"UnitPrice", "PricePerUnit"}}
)
in
Renamed
لایه 3: Semantic (Presentation)
خروجی نهایی که برای گزارش و مدل تحلیلی آماده است، در این لایه شکل میگیرد. گروهبندی و محاسبات تجمیعی دادهها در این مرحله انجام میشود.
let
Source = Trf_Sales,
Grouped = Table.Group(
Source,
{"ProductID"},
{
{"TotalQuantity", each List.Sum([Quantity]), type number},
{"TotalRevenue", each List.Sum(List.Transform([Quantity],[Quantity] * [PricePerUnit])), type number}
}
),
MergedProduct = Table.NestedJoin(
Grouped,
"ProductID",
Products,
"ID",
"ProductInfo",
JoinKind.LeftOuter
),
Final = Table.ExpandRecordColumn(
MergedProduct,
"ProductInfo",
{"Name","Category"}
)
in
Final
تعریف پارامترهای پویا و Incremental Refresh
استفاده از پارامترها، Dataflow را پویا و آماده بهروزرسانی فشرده میکند.
let
DateFrom = #date(2023, 1, 1),
DateTo = #date(2023, 12, 31),
SourceServer = "my-sql-server.database.windows.net",
SourceDB = "SalesDB"
in
[
DateFrom = DateFrom,
DateTo = DateTo,
SourceServer = SourceServer,
SourceDB = SourceDB
]
برای فعالسازی Incremental Refresh:
- به تنظیمات Entity (مثلاً Trf_Sales) بروید.
- پارامترهای DateFrom و DateTo را به فیلد تاریخ متصل کنید.
- دوره نگهداری و بارگذاری جدید را تنظیم و ذخیره کنید.
امکانات پیشرفته Dataflow
- Enhanced Compute Engine: اجرای موازی مراحل و افزایش سرعت Refresh
- Mapping Dataflow: نگاشت خودکار منطق CDM بدون نیاز به نوشتن M
- ذخیرهسازی CDM در Azure Data Lake Gen2 برای Lakehouse Pattern
- REST API و PowerShell برای اتوماسیون CI/CD و مدیریت نسخه
Invoke-RestMethod -Method Post `
-Uri "https://api.powerbi.com/v1.0/myorg/groups/{groupId}/dataflows/{dataflowId}/refreshes" `
-Headers @{ Authorization = "Bearer $token" }
بهترین روشها برای طراحی و پیادهسازی
- تعریف Naming Convention استاندارد (
df_,stg_,trf_) - استفاده از پارامترها و توابع سفارشی برای کوئریهای پویا
- پایش و لاگگیری با Query Diagnostics و Performance Analyzer
- بهرهگیری از Incremental Refresh و پارامترهای تاریخ
- پیادهسازی Security ردیفی و Versioning در Git یا Azure DevOps
نتیجهگیری
Dataflow در Power BI، بستر مناسبی برای مدیریت یکپارچه ETL در سطح سازمان است. با استفاده از معماری لایهای، مثالهای عملی M Query و امکانات پیشرفته، میتوانید عملکرد پروژههای Power BI را بهینه کرده و از مقیاسپذیری و امنیت بالاتری بهرهمند شوید.
منابع پیشنهادی برای مطالعه عمیقتر
برای گسترش دانش خود در زمینه زبان M، DAX و طراحی داشبوردهای حرفهای در Power BI، پیشنهاد میشود کتابهای زیر را مطالعه کنید:
- کتاب طراحی داشبوردهای مدیریتی در Microsoft Power BI
- کتاب مرجع زبان فرمول نویسی M در پاورکوئری ( Power Query )
- مرجع زبان DAX افزونه کوئری نویسی در اکسل و POWER BI
- توابع پیشرفته DAX در Power BI
تماس و مشاوره با لاندا
برای پیادهسازی سناریوی عملی و مشاوره بیشتر، هماکنون با تیم لاندا در تماس باشید!
برای اطلاعات بیشتر و مشاوره میتوانید از طریق زیر با ما در ارتباط باشید:



No comment