 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید
در عصر داده، سازمانها برای استخراج ارزش واقعی از اطلاعات، نیازمند داشتن سیستمهای هوش تجاری قوی هستند. فرآیند ETL (Extract, Transform, Load) به عنوان ستون فقرات این سیستمها، باعث یکپارچهسازی دادههای پراکنده و آمادهسازی آنها برای تحلیلهای عمیق میشود. در این مقاله به بررسی جامع و تخصصی نحوه پیادهسازی ETL پرداخته و نکات کلیدی لازم جهت بهبود کارایی، کیفیت و امنیت دادهها را بیان میکنیم.
تعریف و اهمیت فرآیند ETL در هوش تجاری
فرآیند ETL شامل ۳ مرحله اصلی استخراج (Extract)، تبدیل (Transform) و بارگذاری (Load) است که هر کدام نقش حیاتی در آمادهسازی دادهها برای تحلیلهای عمیق دارند.
- استخراج دادهها: دادهها از منابع مختلف مانند پایگاههای داده، فایلهای اکسل، APIها و سیستمهای ERP بهصورت بهینه و بدون از دست دادن اطلاعات ارزشمند استخراج میشوند.
- تبدیل دادهها: دادههای خام از طریق اعمال الگوریتمهای پاکسازی، استانداردسازی، نرمالسازی، تجمیع و دیگر عملیات پردازشی به قالبی یکپارچه و قابل استفاده تبدیل میشوند.
- بارگذاری دادهها: دادههای پردازششده در انبار دادهها (مانند Data Warehouse یا Data Lake) وارد شده و سپس توسط ابزارهای تحلیل مانند Power BI، Tableau یا Qlik Sense مورد استفاده قرار میگیرند.
با بهرهگیری از این فرآیند، سازمانها میتوانند به بهرهبرداری بهینه از دادههای خود بپردازند، تصمیمگیریهای استراتژیک را بهبود بخشند و عملکرد کسبوکار را افزایش دهند.
مراحل پیادهسازی ETL در پروژههای BI
۱. تحلیل نیازهای دادهای و تعیین معماری
ابتدا باید نیازهای دادهای پروژه شناسایی شده و سوالاتی مانند «چه نوع دادههایی مورد نیاز است؟»، «این دادهها از کدام منابع استخراج خواهند شد؟» و «چگونه باید پردازش شوند؟» پاسخ داده شوند. سپس معماری فرآیند ETL مشخص میگردد. در این راستا انتخاب بین پردازش دستهای (Batch Processing) و پردازش در لحظه (Real-time Processing) یا حتی یک رویکرد هیبریدی، بر اساس حجم دادهها و نیازهای پروژه تعیین میشود.
۲. طراحی مدل داده و انتخاب ابزارهای مناسب
در این مرحله از طراحی، مدل دادهای مطابق با نیازهای تجاری تدوین شده و انبار داده مناسب مانند Snowflake، Azure Synapse یا Google BigQuery انتخاب میشود. علاوه بر این، ابزارهای مناسب ETL مانند Microsoft SQL Server Integration Services (SSIS)، Talend یا Apache NiFi با توجه به پیچیدگی پروژه و نوع پردازش داده باید تعیین شوند. انتخاب ابزار مناسب از شروع به انتقال دادههای صحیح و بهموقع در سیستمهای BI اطمینان میدهد.
۳. پیادهسازی استخراج دادهها (Extract)
در این بخش فرآیند استخراج دادهها به صورت بهینه اجرا میشود. استفاده از تکنیکهایی مانند:
- Change Data Capture (CDC): استخراج فقط تغییرات داده به جای کل مجموعه اطلاعات
- Incremental Extraction: دریافت افزایشی دادهها برای کاهش حجم پردازش
- Parallel Extraction: اجرای همزمان استخراج از منابع متعدد جهت افزایش سرعت
همچنین اعمال فیلترهای اولیه در سطح پایگاه داده، نقشی کلیدی در کاهش بار روی منابع دارد.
۴. اجرای مرحله تبدیل دادهها (Transform)
تبدیل دادهها به قالبی یکپارچه شامل پاکسازی، استانداردسازی، نرمالسازی و تجمیع اطلاعات میشود. در این مرحله، مسائل زیر مطرح میشوند:
- Data Cleaning: حذف دادههای تکراری، نادرست یا از کار افتاده
- Schema Mapping: تطبیق ساختار دادهها با مدل انبار داده
- Data Aggregation: ترکیب دادههای مشابه از منابع مختلف جهت استخراج شاخصهای کاربردی
- Surrogate Key Assignment: اختصاص کلیدهای جایگزین برای حفظ یکپارچگی داده
اجرای این تکنیکها تضمین میکند که دادههای تولید شده برای تحلیلهای عمیق و دقیق آماده باشند.
۵. پیادهسازی بارگذاری دادهها (Load)
در این مرحله دادههای پردازششده به انبار داده بارگذاری میشوند. استراتژیهای متنوعی نظیر:
- Incremental Load: بارگذاری تغییرات جدید به جای بارگذاری کامل
- Bulk Loading: انتقال دستهای دادههای حجیم
- Partitioning: تقسیم دادهها به بخشهای کوچکتر برای بهبود سرعت پردازش
به کار گرفته میشود. همچنین استفاده از ابزارهای بهینهسازی ایندکسها و مکانیزمهای کش در این مرحله، عملکرد سیستمهای تحلیل BI را بهبود میبخشد.
۶. انجام تستهای عملیاتی و مانیتورینگ
پس از پیادهسازی فرآیند ETL، اجرای تستهای جامع جهت اطمینان از صحت، کارایی و عملکرد صحیح فرآیند ضروری است. سیستمهای مانیتورینگ و لاگگذاری در کنار پیادهسازی هشدارهای خودکار به شناسایی سریع مشکلات کمک کرده و امکان بهبود مستمر را فراهم میکنند. در نهایت، بهینهسازیهای لازم از نظر عملکردی و امنیتی باید بهطور منظم انجام شود.
تکنیکهای پیشرفته ETL
تکنیکهای استخراج (Extract)
در مرحله استخراج، استفاده از تکنیکها و روشهای نوین از اهمیت بالایی برخوردار است. بهکارگیری روشهایی مانند CDC، استخراج افزایشی و پردازش موازی، سرعت و دقت انتقال دادهها را افزایش میدهد. اجرای این تکنیکها موجب کاهش فشار بر روی منابع داده و افزایش کارایی کلی سیستم میشود.
تکنیکهای تبدیل (Transform)
تبدیل دادهها به قالب مناسب نیازمند استفاده از الگوریتمهای پیچیده و ابزارهای پیشرفته است. تکنیکهای پاکسازی داده، نرمالسازی، تجمیع و نقشهبرداری شِما از جمله مواردی هستند که در این مرحله مورد استفاده قرار میگیرند. علاوه بر این، اختصاص کلیدهای جایگزین (Surrogate Key Assignment) به حفظ یکپارچگی دادهها کمک چشمگیری میکند.
تکنیکهای بارگذاری (Load)
برای بهبود عملکرد بارگذاری دادهها، استراتژیهای مختلفی بهکار گرفته میشود. بارگذاری افزایشی بهعنوان یک روش موثر در کاهش مصرف منابع و زمان انتقال داده شناخته میشود. همچنین استفاده از بارگذاری دستهای و تقسیمبندی دادهها (Partitioning) از جمله تکنیکهای مؤثر در بهبود سرعت و کیفیت انتقال دادهها به انبار داده است.
رویکردهای پیشرفته ETL
در برخی موارد، ترکیب روشهای ETL و ELT (Extract, Load, Transform) باعث ایجاد انعطاف بیشتری در پردازش دادهها میشود. روشهای خودکارسازی ETL با بهرهگیری از ابزارهایی نظیر Apache Airflow، Talend و دیگر پلتفرمهای توزیعشده به منظور پیادهسازی پردازشهای موازی و در زمان واقعی پیشرفتهتر شدهاند. این رویکردها با در نظر گرفتن حجم دادههای بزرگ و نیاز به پردازش لحظهای، مزایای قابل توجهی از نظر کارایی و مقیاسپذیری رقم میزنند.
کاربردهای ETL در صنایع مختلف
– بانکداری و خدمات مالی
در صنعت بانکداری، ETL نقش مهمی در تحلیل تراکنشهای مالی، مدیریت ریسک و شناسایی فعالیتهای تقلبی دارد. تجمیع دادههای حسابهای بانکی و تراکنشهای مالی از منابع مختلف بهوسیله ETL، امکان تحلیل دقیق رفتار مشتریان و ارائه خدمات شخصیسازی شده را فراهم میکند.
– تجارت الکترونیک و خردهفروشی
در حوزه تجارت الکترونیک، ETL به مدیریت زنجیره تأمین، بهبود فرآیندهای موجودی و بهینهسازی تبلیغات دیجیتال کمک میکند. جمعآوری، تجمیع و تحلیل دادهها از منابع متعدد مانند سیستمهای سفارش آنلاین و موجودی کالا، از طریق این فرآیند، باعث بهبود تجربه مشتری و افزایش فروش میشود.
– مراقبتهای بهداشتی و پزشکی
در صنعت سلامت، استفاده از ETL در جمعآوری و استانداردسازی سوابق بیماران، پردازش نتایج آزمایشهای بالینی و تحلیل دادههای تحقیقاتی، منجر به بهبود تشخیص و درمان بیماریها میشود. این فرآیند امکان دسترسی به دادههای دقیق و یکپارچه را برای پژوهشگران و متخصصان بهداشت فراهم میکند.
– حمل و نقل و لجستیک
ETL در بهینهسازی مسیرها، تحلیل دادههای GPS و مدیریت لجستیک شرکتهای حمل و نقل موثر است. این فرآیند با تجمیع دادههای مربوط به موجودی کالا، برنامهریزی حملونقل و بررسی تأخیرهای احتمالی، به ارائه راهکارهای بهینه برای کاهش هزینهها و بهبود زمانبندی کمک میکند.
– صنایع تولیدی
در دنیای تولید، استفاده از ETL برای کنترل کیفیت تولید، مدیریت خط تولید و پیشبینی مشکلات عملکردی، نقش مهمی دارد. از طریق جمعآوری و تحلیل دادههای مربوط به حسگرهای تولید و ماشینآلات، امکان اصلاح فرآیندها و افزایش بهرهوری در خطوط تولید فراهم میشود.
– رسانه و سرگرمی
در صنعت رسانه و سرگرمی، تحلیل دادههای مصرف محتوا، رفتار کاربران و تبلیغات دیجیتال از اهمیت ویژهای برخوردار است. ETL با جمعآوری و پردازش دادههای حاصل از پلتفرمهای پخش، موجب طراحی توصیههای محتوا و بهینهسازی کمپینهای تبلیغاتی میشود.
– دولت و سازمانهای عمومی
در زمینههای دولتی، ETL از جمعآوری و تحلیل دادههای جمعیتی، اقتصادی و اجتماعی در بهبود خدمات عمومی و تدوین سیاستهای هوشمندانه استفاده میشود. همچنین این فرآیند کمک میکند تا دادههای مربوط به امنیت، جرایم و مدیریت بحرانها بهصورت یکپارچه گزارش شوند.
چالشها و مشکلات رایج در فرآیند ETL
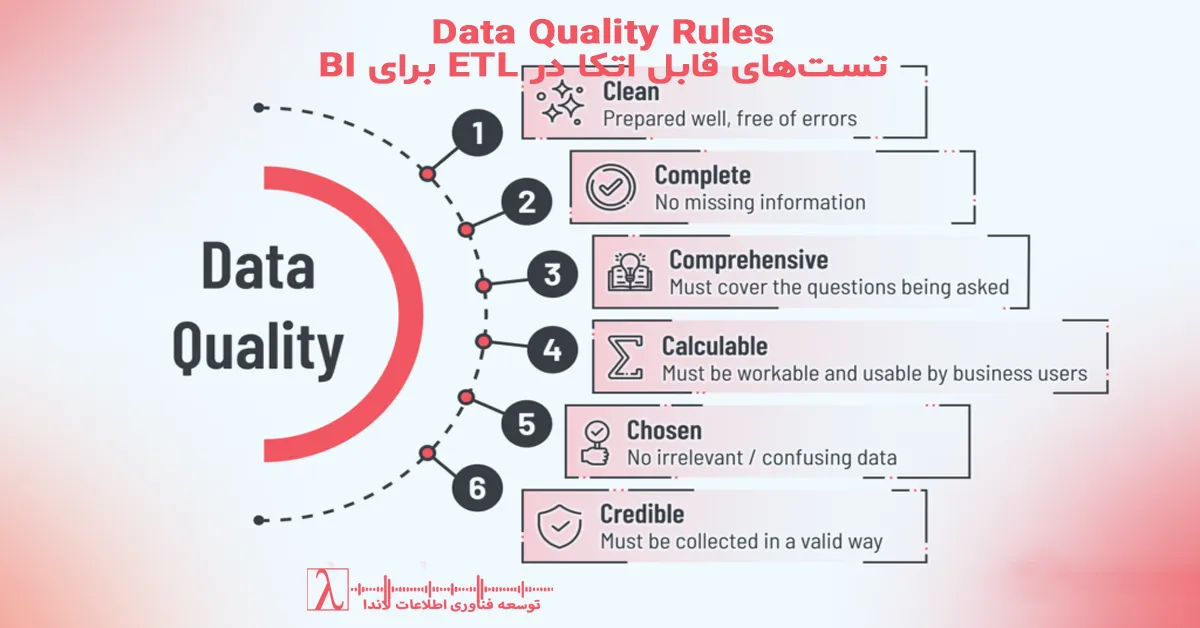
۱. کیفیت پایین دادهها
یکی از چالشهای اصلی در اجرای ETL، مواجهه با دادههای ناسازگار، ناقص یا تکراریست. عدم دقت در پاکسازی دادهها میتواند منجر به انتقال خطاها به مرحله تحلیل شود. برای رفع این مشکل، استفاده از فرآیندهای قوی Data Cleaning و اعمال استانداردهای دقیق دادهای ضروری است.
۲. پیچیدگی در پردازش دادهها
در مواجهه با حجم بالای دادهها یا تنوع ساختاری آنها، تبدیل و پردازش دادهها به یک چالش تبدیل میشود. بهرهگیری از روشهای پردازش موازی (Parallel Processing) و استفاده از ابزارهای پیشرفته جهت استانداردسازی فرمت دادهها از راهکارهای موثر در این زمینه بهشمار میآیند.
۳. عملکرد پایین و سرعت کم
اجرای فرآیند ETL در صورت عدم بهینهسازی، زمانبر بوده و میتواند بر عملکرد کلی سیستم تأثیر منفی بگذارد. بهکارگیری تکنیکهای Incremental Load، بهینهسازی Queryهای پایگاه داده و استفاده از تکنیکهای Partitioning از جمله راهکارهای تأثیرگذار در بهبود سرعت پردازش هستند.
۴. مشکلات اتصال به منابع داده
همچنان که دادهها از منابع متعدد استخراج میشوند، تفاوت فرمتها و محدودیتهای دسترسی به منابع میتواند منجر به بروز مشکلاتی گردد. استفاده از APIهای استاندارد، طراحی Wrapper Services جهت تطبیق فرمتها و تنظیم دقیق دسترسیهای امنیتی میتواند در رفع این موانع مفید باشد.
۵. مدیریت خطاها و Logging
عدم استفاده از سیستمهای مانیتورینگ منظم و روشهای ثبت خطا، میتواند باعث از دست رفتن اطلاعات و دشواری در شناسایی مشکلات شود. پیادهسازی سامانههای Logging پیشرفته با استفاده از هشدارهای خودکار و امکان Rollback در مواقع بروز خطا، در تضمین صحت فرآیند ETL نقشی اساسی دارد.
۶. امنیت دادهها
انتقال دادههای حساس بهوسیله فرآیند ETL نیازمند توجه ویژه به مسائل امنیتی است. رمزنگاری دادهها در حین انتقال، استفاده از Data Masking، و اعمال کنترلهای دسترسی قوی از جمله راهکارهایی هستند که از افشای اطلاعات محرمانه جلوگیری میکنند.
۷. مقیاسپذیری
با افزایش حجم دادهها، فرآیند ETL میتواند تحت فشار قرار گرفته و عملکرد آن کاهش یابد. طراحی معماری ETL مبتنی بر ابر (Cloud-based ETL) و استفاده از چارچوبهای توزیعشده مانند Apache Spark، از راهکارهای مؤثر برای تضمین مقیاسپذیری و افزایش کارایی هستند.
نتیجهگیری
در پایان، میتوان گفت که فرآیند ETL یکی از اجزای حیاتی برای موفقیت پروژههای هوش تجاری محسوب میشود. از استخراج دقیق و بهموقع دادهها تا تبدیل و بارگذاری آنها در قالب مناسب، تمام مراحل ETL نقش کلیدی در بهبود تصمیمگیریهای استراتژیک کسبوکار، افزایش بهرهوری و کاهش هزینهها دارند. پیادهسازی صحیح این فرآیند، استفاده از تکنیکها و ابزارهای بهروز و مواجهه با چالشهای موجود با راهکارهای نوین امنیتی، عملکرد سیستمهای BI را به یک پایه قوی برای موفقیت سازمانی بدل میکند.
تماس و مشاوره با لاندا
برای اطلاعات بیشتر و مشاوره میتوانید از طریق زیر با ما در ارتباط باشید:
ممنون می شم تفاوت بین etlوeltرو بفرمایید🙏
ETL (Extract, Transform, Load) و ELT (Extract, Load, Transform) دو روش پردازش داده هستند که تفاوتهای مهمی دارند:
ETL (استخراج، تبدیل، بارگذاری)
ابتدا دادهها از منابع مختلف استخراج میشوند.
سپس دادهها در یک محیط واسط تبدیل میشوند (پاکسازی، تغییر فرمت، ترکیب دادهها و غیره).
در نهایت دادههای پردازششده به انبار داده منتقل و ذخیره میشوند.
مناسب
برای دادههای ساختاریافته و سیستمهای سنتی.
ELT (استخراج، بارگذاری، تبدیل)
ابتدا دادهها از منابع مختلف استخراج میشوند.
سپس دادهها مستقیماً در انبار داده یا دریاچه داده بارگذاری میشوند.
در نهایت، تبدیل دادهها در همان انبار داده انجام میشود.
تحلیل دقیق مراحل ETL واقعاً نقطه قوت این مقالهست، مخصوصاً بخش مربوط به Data Cleansing که معمولاً در پروژههای واقعی کمتوجهی میشه. استفاده از نمودارها به درک بهتر کمک زیادی کرد. اگر در آینده مقالهای درباره تفاوتهای ETL با ELT بنویسید، عالی میشه.
سپاس از نطر شما و حتما نوشته خواهد شد
ممنون از مقالهتون. یک سوال ذهنم رو مشغول کرده: در پروژههایی که حجم داده بسیار بالاست، آیا مرحله Transform بهتره قبل از بارگذاری انجام بشه یا بعد از اون؟ خوشحال میشم تجربهتون رو بدونم.
در پروژههایی با حجم داده بسیار بالا، معمولاً مرحله Transform قبل از بارگذاری (ETL: Extract, Transform, Load) انجام میشود. این روش به دلیل مزایای زیر ترجیح داده میشود:
۱. کاهش حجم داده قبل از ذخیرهسازی: با تبدیل دادهها قبل از بارگذاری، میتوان حجم دادههای ورودی را کاهش داد، که باعث صرفهجویی در منابع ذخیرهسازی و پردازش میشود.
2. بهینهسازی عملکرد بارگذاری: پردازش دادههای خام در مرحله استخراج و تبدیل، باعث بهبود کارایی پایگاه داده مقصد میشود، زیرا از ورود دادههای نامناسب جلوگیری میکند.
3. افزایش کیفیت دادهها: در فرآیند ETL، دادهها قبل از ورود به سیستم نهایی پاکسازی، نرمالسازی و یکپارچهسازی میشوند، که کیفیت و صحت دادهها را تضمین میکند.
اما در برخی موارد خاص، روش ELT (Extract, Load, Transform) نیز کاربرد دارد، که در آن دادهها ابتدا بارگذاری شده و سپس تبدیل میشوند. این روش برای سیستمهای کلانداده و پردازشهای موازی مناسبتر است، زیرا امکان استفاده از قدرت پردازشی پایگاه دادههای توزیعشده مانند Snowflake، BigQuery یا Redshift را فراهم میکند.
من بهصورت تخصصی در حوزه BI نیستم اما با خوندن این مقاله تونستم درک اولیه خوبی از ساختار ETL پیدا کنم. متن بهزبان ساده نوشته شده و برای افراد مبتدی هم قابلفهمه. ممنون بابت محتوا.
سپاس از شماموفق باشید
با اینکه مقاله ساختار خوبی داره، اما بهنظرم بهتر بود در بخش ابزارهای ETL به ابزارهای ابری مثل AWS Glue یا Google Dataflow هم اشاره میشد. این ابزارها تو پروژههای مدرن نقش پررنگتری پیدا کردن.
چشم حتما در ادامه پرداخته خواهد شد