در دنیای پایگاههای داده، بهینهسازی عملکرد کوئریها یکی از مهمترین وظایف مدیران و توسعهدهندگان پایگاه داده است. SQL Server بهعنوان یکی از محبوبترین سیستمهای مدیریت پایگاه داده، ابزارها و تکنیکهای متعددی برای بهبود عملکرد ارائه میدهد. یکی از این تکنیکها، استفاده از Cover Index یا ایندکس پوششی است. در این مقاله، بهطور جامع به تعریف، نحوه عملکرد، مزایا، معایب، و نکات طراحی Cover Index در SQL Server میپردازیم.
Cover Index چیست؟
Cover Index به ایندکسی گفته میشود که تمام ستونهای مورد نیاز برای اجرای یک کوئری خاص را در خود جای داده است. به این ترتیب، SQL Server میتواند دادههای مورد نیاز را مستقیماً از ساختار ایندکس بخواند و نیازی به دسترسی به جدول اصلی (چه بهصورت Heap یا Clustered Index) نداشته باشد. این ویژگی باعث کاهش عملیات ورودی/خروجی (I/O) و افزایش سرعت اجرای کوئریها میشود.
بهطور کلی، Cover Index معمولاً از نوع Non-Clustered Index است و میتواند با استفاده از قابلیت Included Columns در SQL Server طراحی شود. این ایندکسها بهگونهای ساخته میشوند که تمام ستونهای موجود در بخشهای مختلف کوئری (مانند SELECT, WHERE, JOIN, GROUP BY, یا ORDER BY) را پوشش دهند.
عملکرد ایندکس پوششی
برای درک بهتر نحوه عملکرد Cover Index، ابتدا باید با ساختار ایندکسها در SQL Server آشنا شویم. ایندکسها بهصورت درختهای B+ ذخیره میشوند و شامل کلیدهای ایندکس و اشارهگرهایی به دادههای جدول هستند. در یک ایندکس غیرکلاستری (Non-Clustered Index)، کلیدهای ایندکس و ستونهای اضافی (در صورت استفاده از INCLUDE) ذخیره میشوند.
وقتی یک کوئری اجرا میشود، بهینهساز کوئری (Query Optimizer) در SQL Server بررسی میکند که آیا ایندکسی وجود دارد که بتواند تمام ستونهای مورد نیاز کوئری را فراهم کند. اگر چنین ایندکسی پیدا شود، SQL Server از آن بهعنوان یک Cover Index استفاده میکند و نیازی به مراجعه به جدول اصلی نخواهد داشت. این فرآیند بهصورت زیر انجام میشود:
-
تحلیل کوئری: بهینهسازی کوئری ستونهای استفاده شده در بخشهای مختلف کوئری (مثل فیلترها، انتخابها، یا مرتبسازی) را شناسایی میکند.
-
جستجوی ایندکس: بررسی میکند که آیا ایندکسی وجود دارد که تمام این ستونها را در خود داشته باشد.
-
اجرای کوئری: اگر ایندکس مناسب پیدا شود، دادهها مستقیماً از ایندکس خوانده میشوند، که باعث کاهش زمان اجرا و مصرف منابع میشود.
مزایای استفاده از Cover Index
استفاده از Cover Index مزایای متعددی دارد که در ادامه به برخی از آنها اشاره میکنیم:
-
افزایش سرعت اجرای کوئریها: از آنجا که دادهها مستقیماً از ایندکس خوانده میشوند و نیازی به دسترسی به جدول اصلی نیست، زمان اجرای کوئری بهطور قابلتوجهی کاهش مییابد.
-
کاهش عملیات ورودی/خروجی (I/O): دسترسی به جدول اصلی معمولاً به تعداد صفحات داده بیشتری نیاز دارد، اما ایندکسها معمولاً حجم کمتری دارند و خواندن آنها سریعتر است.
-
بهینهسازی برای کوئریهای پرتکرار: Cover Index میتواند برای کوئریهایی که بهطور مکرر اجرا میشوند طراحی شود، که در سیستمهای با بار کاری بالا بسیار مفید است.
-
انعطافپذیری در طراحی: با استفاده از قابلیت INCLUDE، میتوان ستونهای اضافی را به ایندکس اضافه کرد بدون اینکه در کلید ایندکس قرار گیرند، که باعث کاهش اندازه ایندکس و بهبود عملکرد میشود.
معایب و چالشهای Cover Index
با وجود مزایای متعدد، استفاده از Cover Index بدون چالش نیست. در ادامه به برخی از معایب و محدودیتهای آن اشاره میکنیم:
-
مصرف فضای ذخیرهسازی بیشتر: هر ایندکس اضافی فضای بیشتری در دیسک اشغال میکند. اگر تعداد زیادی Cover Index ایجاد شود، حجم پایگاه داده افزایش مییابد.
-
هزینه نگهداری ایندکس: هرگونه عملیات درج، بهروزرسانی، یا حذف در جدول باعث بهروزرسانی ایندکسها میشود، که میتواند عملکرد این عملیاتها را کاهش دهد.
-
پیچیدگی طراحی: انتخاب ستونهای مناسب برای ایندکس و طراحی آن بهگونهای که کوئریهای مختلف را پوشش دهد، نیاز به تحلیل دقیق و درک عمیق از الگوهای کوئری دارد.
-
محدودیت در تعداد ستونها: در SQL Server، یک ایندکس غیرکلاستری میتواند حداکثر 16 ستون کلید و تعداد محدودی ستون INCLUDE داشته باشد، که ممکن است برای کوئریهای بسیار پیچیده کافی نباشد.
مثال عملی از Cover Index
برای درک بهتر، فرض کنید جدولی به نام Orders با ساختار زیر دارید:
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
TotalAmount DECIMAL(10, 2)
);حال، فرض کنید کوئری زیر بهطور مکرر اجرا میشود:
SELECT CustomerID, OrderDate
FROM Orders
WHERE CustomerID = 100;برای بهینهسازی این کوئری، میتوانید یک ایندکس غیرکلاستری بهصورت زیر ایجاد کنید:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate
ON Orders (CustomerID)
INCLUDE (OrderDate);توضیح ایندکس
-
کلید ایندکس: ستون CustomerID بهعنوان کلید ایندکس استفاده شده است، زیرا در شرط WHERE به کار میرود.
-
ستونهای INCLUDE: ستون OrderDate در بخش INCLUDE قرار گرفته است، زیرا در بخش SELECT استفاده میشود.
نتیجه: این ایندکس تمام ستونهای مورد نیاز کوئری را پوشش میدهد و SQL Server میتواند دادهها را مستقیماً از ایندکس بخواند.
اگر این ایندکس وجود نداشته باشد، SQL Server ممکن است نیاز به اسکن جدول یا مراجعه به Clustered Index داشته باشد، که کندتر خواهد بود.
نکات طراحی
برای طراحی یک Cover Index کارآمد، باید به نکات زیر توجه کنید:
-
تحلیل کوئریهای پر تکرار: ابتدا کوئریهایی که بیشترین تأثیر را بر عملکرد سیستم دارند شناسایی کنید. ابزارهایی مانند SQL Server Profiler یا Extended Events میتوانند به شناسایی این کوئریها کمک کنند.
-
انتخاب ستونهای مناسب:
-
ستونهایی که در شرطهای WHERE, JOIN, یا GROUP BY استفاده میشوند را بهعنوان کلید ایندکس قرار دهید.
-
ستونهایی که فقط در بخش SELECT یا ORDER BY هستند را در بخش INCLUDE قرار دهید.
-
-
استفاده از ابزارهای بهینهسازی: ابزار Database Engine Tuning Advisor در SQL Server میتواند پیشنهادهای مفیدی برای ایجاد ایندکسهای مناسب ارائه دهد.
-
محدود کردن تعداد ایندکسها: ایجاد ایندکسهای زیاد میتواند عملکرد عملیات درج، بهروزرسانی، و حذف را کاهش دهد. بنابراین، فقط ایندکسهایی را ایجاد کنید که تأثیر قابلتوجهی بر عملکرد دارند.
-
بررسی دورهای ایندکسها: با تغییر الگوهای کوئری یا ساختار دادهها، ممکن است برخی ایندکسها دیگر مفید نباشند. از ابزارهایی مانند Index Usage Statistics برای شناسایی ایندکسهای بلااستفاده استفاده کنید.
مقایسه با سایر ایندکسها
برای درک بهتر جایگاه Cover Index، آن را با سایر انواع ایندکسها مقایسه میکنیم:
-
Clustered Index:
-
شامل تمام دادههای جدول است و ترتیب فیزیکی دادهها را تعیین میکند.
-
فقط یک Clustered Index برای هر جدول میتوان ایجاد کرد.
-
در مقابل، Cover Index معمولاً غیرکلاستری است و برای کوئریهای خاص طراحی میشود.
-
-
Non-Clustered Index بدون پوشش:
-
ممکن است فقط بخشی از ستونهای مورد نیاز کوئری را شامل شود و نیاز به Bookmark Lookup برای دسترسی به دادههای جدول داشته باشد.
-
Cover Index این مشکل را با پوشش تمام ستونهای مورد نیاز برطرف میکند.
-
-
Filtered Index:
-
فقط بخشی از دادهها (بر اساس یک شرط خاص) را ایندکس میکند.
-
میتواند بهعنوان Cover Index نیز عمل کند، اما برای زیرمجموعهای از دادهها.
-
نتیجه گیری
Cover Index یکی از تکنیکهای قدرتمند در SQL Server برای بهینهسازی عملکرد کوئریها است. با طراحی ایندکسهایی که تمام ستونهای مورد نیاز یک کوئری را پوشش میدهند، میتوان زمان اجرای کوئریها را کاهش داد و مصرف منابع را به حداقل رساند. با این حال، استفاده از Cover Index نیازمند تحلیل دقیق کوئریها و مدیریت تعادل بین عملکرد خواندن و نوشتن است.
برای موفقیت در استفاده از Cover Index، توصیه میشود:
-
کوئریهای پرتکرار را شناسایی کنید.
-
از ابزارهای تحلیل و بهینهسازی SQL Server استفاده کنید.
-
ایندکسها را بهصورت دورهای بررسی و بهینه کنید.
اگر به دنبال بهبود عملکرد پایگاه داده خود هستید، این نوع ایندکس میتواند یکی از ابزارهای کلیدی در جعبه ابزار شما باشد. با طراحی هوشمندانه و مدیریت صحیح، این ایندکسها میتوانند تأثیر قابلتوجهی بر عملکرد سیستم داشته باشند.


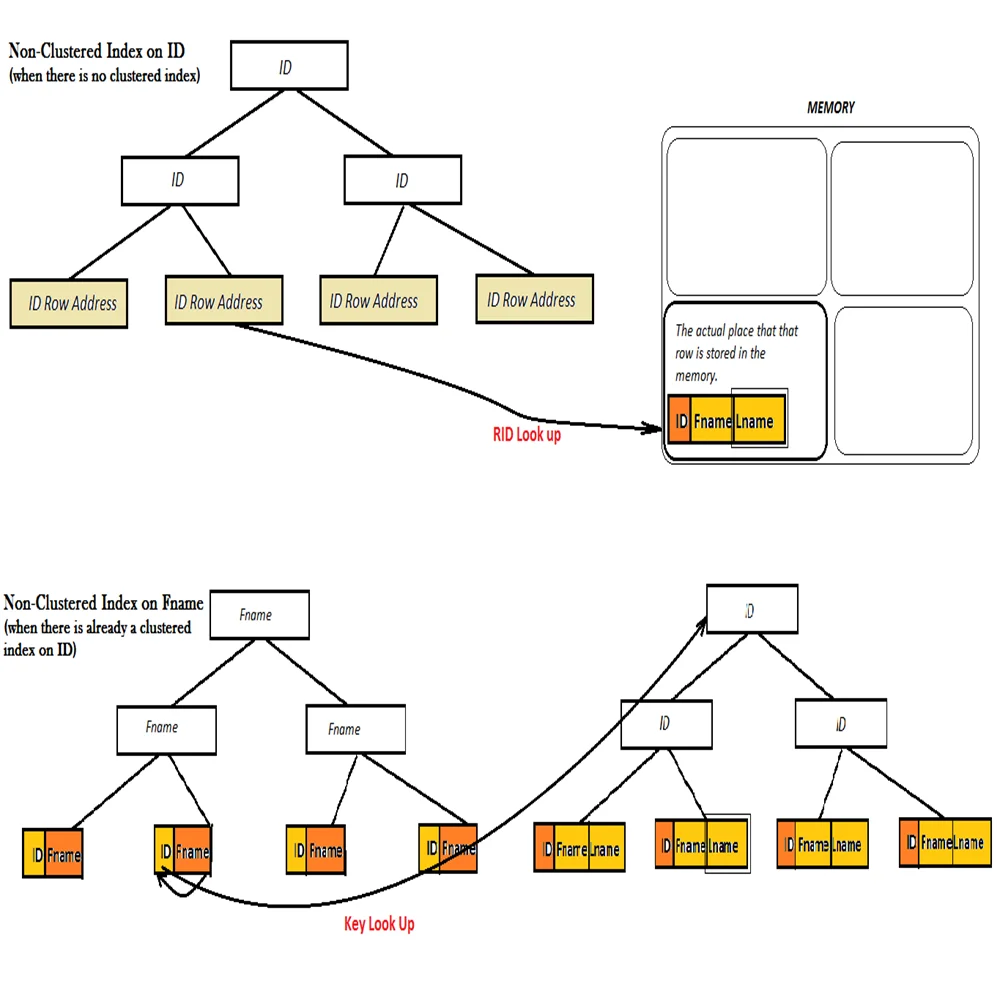
تفاوت این ایندکس با index view چیه؟
تفاوت Index و Indexed View در SQL Server به نحوه ذخیرهسازی و استفاده از دادهها مربوط میشود:
Index (ایندکس معمولی):
– روی جدولهای معمولی اعمال میشود.
– به بهینهسازی عملکرد کوئریها کمک میکند.
– میتواند خوشهای (Clustered) یا غیر خوشهای (Non-Clustered) باشد.
– دادهها را مستقیماً در جدول ذخیره میکند و فقط مسیرهای دسترسی سریعتر را فراهم میکند.
Indexed View (نماهای ایندکسشده):
– روی View اعمال میشود، نه روی جدول.
– دادهها را بهصورت فیزیکی ذخیره میکند، برخلاف Viewهای معمولی که فقط یک کوئری هستند.
– میتواند عملکرد کوئریهای پیچیده را بهبود قابلتوجهی ببخشد.
– برای استفاده از Indexed View، باید WITH SCHEMABINDING را در تعریف View مشخص کنید.
با سلام و احترام
مطالب بسیار عالی هستند
سپاس
خیلی عالی و کاربردی بود ممنون
ممنون از توجه شما