در مدیریت پایگاههای داده، ایندکسها ابزارهایی کلیدی هستند که سرعت و کارایی پرسوجوها را به شکل چشمگیری افزایش میدهند. SQL Server، یکی از محبوبترین سامانههای مدیریت پایگاه داده، دو نوع اصلی ایندکس را ارائه میدهد: Clustered Index و Non-Clustered Index به دلیل قابلیتهای منحصربهفرد خود نقشی اساسی در بهینهسازی عملکرد پایگاههای داده ایفا میکند.
Clustered Index چیست؟
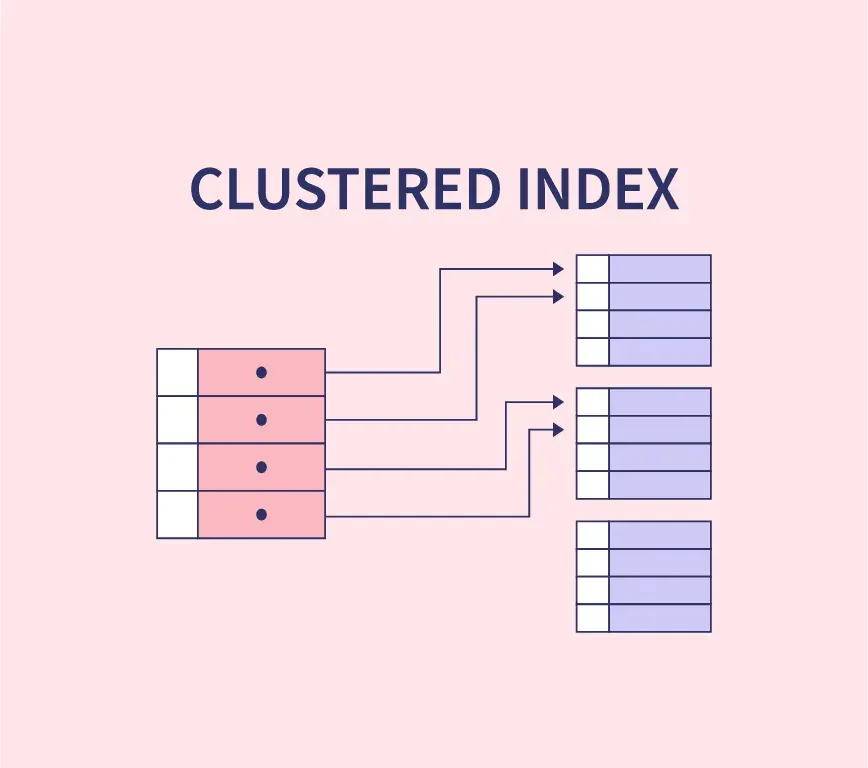
ایندکس خوشهای نوعی ایندکس است که دادههای جدول را بر اساس کلید ایندکس مرتب و ذخیره میکند. برخلاف Non-Clustered Index، که تنها به محل دادهها اشاره دارد، Clustered Index دادهها را به ترتیب مشخص در جدول قرار میدهد و در نتیجه ترتیب فیزیکی دادهها با ترتیب کلید ایندکس هماهنگ است. از آنجا که این نوع ایندکس ترتیب فیزیکی دادهها را مشخص میکند، هر جدول میتواند تنها یک ایندکس خوشهای داشته باشد.
ساختار و عملکرد
Clustered Index از ساختار B-Tree بهره میبرد که به سه بخش اصلی تقسیم میشود:
- گره ریشه (Root Node): نقطه آغاز ایندکس.
- گرههای واسط (Intermediate Nodes): گرههایی که عملیات جستجو و مرتبسازی را تسهیل میکنند.
- گرههای برگ (Leaf Nodes): گرههایی که دادههای واقعی جدول را نگهداری میکنند.
این ساختار با سازماندهی دادهها به صورت سلسله مراتبی امکان دسترسی سریعتر به اطلاعات را فراهم میآورد.
مزایا و محدودیتها
مزایا
- سرعت بخشیدن به پرسوجوها: عملیات خواندن و جستجوی دادهها به دلیل مرتب بودن داده، بهینهتر انجام میشود.
- بهینهسازی پرسوجوهای بازهای (Range Queries): پرسوجوهایی که دادهها را در بازههای مشخص فیلتر میکنند، با استفاده از Clustered Index سریعتر اجرا میشوند.
- کاهش عملیات I/O: مرتب بودن دادهها موجب کاهش عملیات ورودی/خروجی دیسک میشود که در جداول بزرگ بسیار کاربردی است.
- تسهیل عملیات Join: در پرسوجوهایی که به مقایسه دادههای دو یا چند جدول نیاز است، ایندکس خوشهای نقش مهمی در کاهش بار پردازشی ایفا میکند.
- ایجاد نظم در ذخیرهسازی دادهها: با کاهش پراکندگی دادهها، فضای ذخیرهسازی بهینهتر مورد استفاده قرار میگیرد.
محدودیتها
- زمانبر بودن عملیات درج و بهروزرسانی: به دلیل نیاز به بازآرایی دادهها هنگام تغییرات.
- محدودیت تعداد: هر جدول تنها یک ایندکس خوشهای میتواند داشته باشد.
- استفاده از فضای بیشتر برای ذخیره ساختار ایندکس.
نقش Clustered Index در بهینهسازی دیتابیس
1. افزایش سرعت پرسوجوها
ترتیب فیزیکی دادهها بر اساس کلید ایندکس به SQL Server امکان میدهد دادهها را با سرعت بیشتری پردازش کند. به ویژه در پرسوجوهای بازهای و مقایسهای، این ویژگی بسیار کاربردی است.
2. کاهش بار I/O
با سازماندهی دادهها به صورت مرتب، عملیات دسترسی به دادهها نیاز کمتری به خواندن دیسک پیدا میکند، که منجر به کاهش زمان پردازش و بهبود عملکرد کلی دیتابیس میشود.
3. بهینهسازی ذخیرهسازی و گزارشدهی
ایندکس خوشهای با مرتب نگه داشتن دادهها، امکان تولید گزارشهای دقیق و سریعتر را فراهم میآورد. این ویژگی برای سیستمهایی که نیاز به تولید گزارشهای پیچیده دارند، بسیار مفید است.
4. عملکرد بهینه در عملیات پیچیده
عملیات پیچیده مانند JOIN بین جداول بزرگ، با کمک Clustered Index به صورت بهینهتر اجرا میشوند و باعث کاهش زمان پردازش میشوند.
نحوه ایجاد Clustered Index
برای ایجاد یک Clustered Index در SQL Server، از دستور زیر استفاده میشود:
CREATE CLUSTERED INDEX index_name
ON table_name(column_name);
به عنوان مثال:
CREATE CLUSTERED INDEX idx_customer_id
ON Customers(CustomerID);
انتخاب کلید مناسب برای ایندکس خوشهای بسیار حائز اهمیت است. این کلید باید یکتا، ثابت و مرتبط با نیازهای کاربردی باشد.
تماس و مشاوره با لاندا
برای اطلاعات بیشتر و مشاوره میتوانید از طریق زیر با ما در ارتباط باشید:


No comment