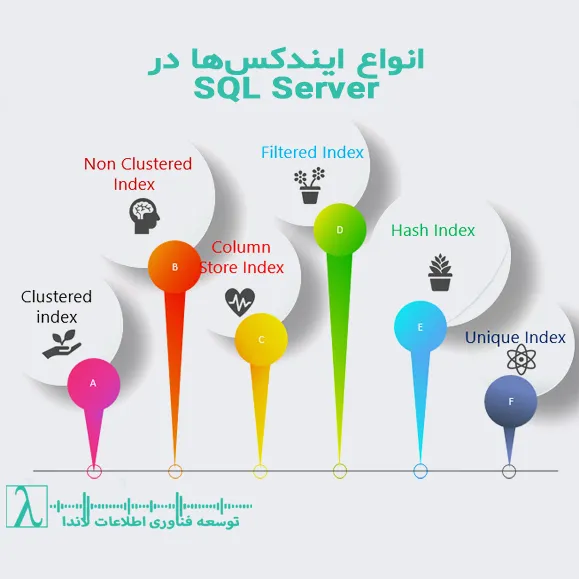
1. ایندکس خوشهای (Clustered Index)
ویژگیها
-
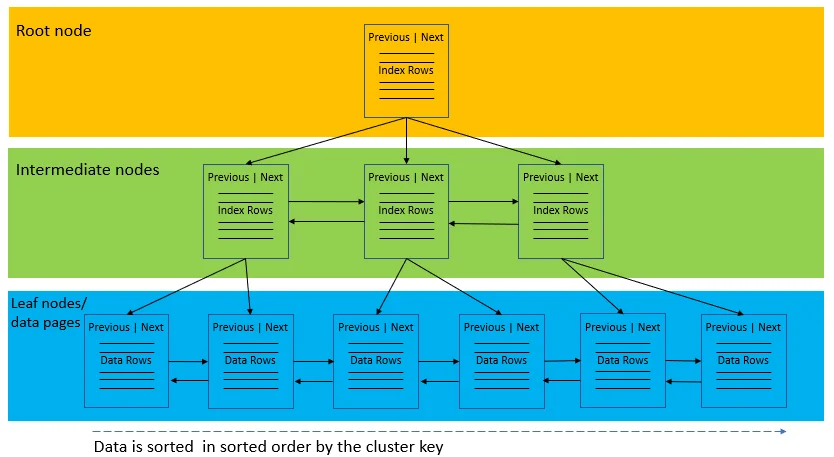
هر جدول تنها میتواند یک ایندکس خوشهای داشته باشد، زیرا دادهها فقط به یک ترتیب فیزیکی ذخیره میشوند.
-
معمولاً روی ستون کلید اصلی (Primary Key) بهصورت پیشفرض ایجاد میشود.
-
به دلیل ذخیره مستقیم دادهها در ساختار ایندکس، جستجو با استفاده از آن بسیار سریع است و نیازی به عملیات اضافه (مانند Lookup) ندارد.
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName NVARCHAR(50),
LastName NVARCHAR(50)
);مزایا
-
عملکرد عالی در کوئریهای مبتنی بر محدوده (Range Queries) مثل WHERE EmployeeID BETWEEN 50 AND 100.
-
مناسب برای جداولی که مرتبسازی یا فیلتر بر اساس یک ستون خاص رایج است.
معایب
-
درج (INSERT) یا بهروزرسانی (UPDATE) دادهها ممکن است کندتر باشد، زیرا مرتبسازی فیزیکی باید حفظ شود.
کاربرد
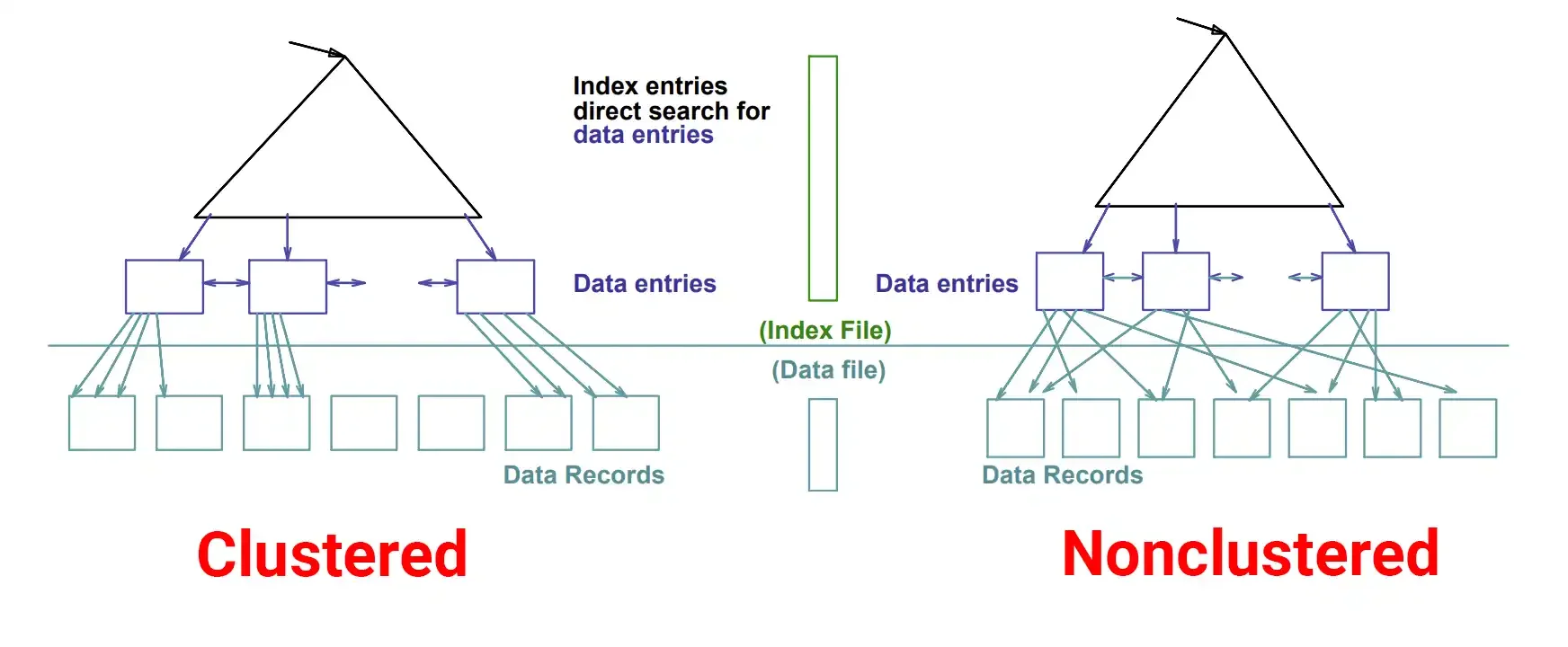
2. ایندکس غیرخوشهای (Non-Clustered Index)
ویژگیها
-
یک جدول میتواند چندین ایندکس غیرخوشهای داشته باشد (حداکثر 999 در SQL Server).
-
برای هر ردیف، اشارهگری به داده اصلی (معمولاً آدرس فیزیکی یا کلید خوشهای) ذخیره میشود.
-
اگر دادههای مورد نظر در ایندکس موجود نباشند، عملیات اضافی به نام Key Lookup انجام میشود.
CREATE NONCLUSTERED INDEX IX_Employees_LastName
ON Employees (LastName);مزایا
-
انعطافپذیری بالا به دلیل امکان ایجاد چندین ایندکس روی ستونهای مختلف.
-
بهبود عملکرد کوئریهای جستجو و مرتبسازی.
معایب
-
فضای ذخیرهسازی بیشتری نیاز دارد، زیرا دادهها در دو مکان (جدول و ایندکس) نگهداری میشوند.
-
درج و بهروزرسانی کندتر است، زیرا ایندکس باید همگامسازی شود.
کاربرد
3. ایندکس منحصربهفرد (Unique Index)
ویژگیها
-
بهطور خودکار هنگام تعریف قید UNIQUE یا کلید اصلی ایجاد میشود.
-
از ورود دادههای تکراری جلوگیری میکند.
CREATE UNIQUE NONCLUSTERED INDEX IX_Employees_Email
ON Employees (Email);مزایا
-
حفظ یکپارچگی دادهها.
-
افزایش سرعت جستجو در ستونهای منحصربهفرد.
معایب
-
محدودیت در ورود دادهها ممکن است برای برخی سناریوها نامناسب باشد.
کاربرد
4. ایندکس فیلترشده (Filtered Index)
ویژگیها
-
فقط ردیفهایی که شرط WHERE را برآورده میکنند، در ایندکس قرار میگیرند.
-
فضای کمتری نسبت به ایندکسهای معمولی اشغال میکند.
CREATE NONCLUSTERED INDEX IX_Employees_Active
ON Employees (DepartmentID)
WHERE IsActive = 1;مزایا
-
کاهش هزینه نگهداری و فضای ذخیرهسازی.
-
بهبود عملکرد کوئریهای خاص.
معایب
-
محدود به سناریوهای خاص با شرطهای ثابت.
کاربرد
5. ایندکس ستونی (Columnstore Index)
ویژگیها
-
دادهها بهصورت فشرده ذخیره میشوند و عملیاتهایی مثل جمع (SUM) یا میانگین (AVG) را تسریع میکنند.
-
میتواند خوشهای یا غیرخوشهای باشد.
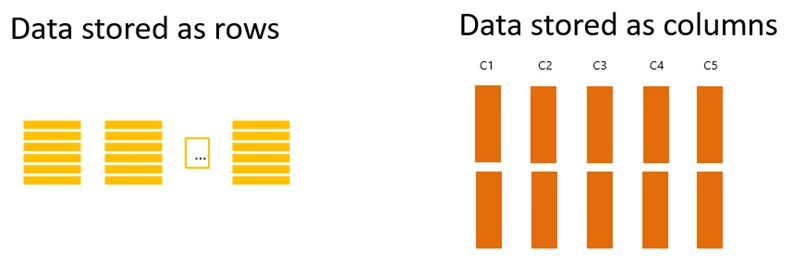
CREATE COLUMNSTORE INDEX IX_Sales_Columnstore
ON Sales (SaleDate, Amount);مزایا
-
عملکرد فوقالعاده در تحلیل دادهها.
-
کاهش حجم ذخیرهسازی با فشردهسازی.
معایب
-
برای جداول با عملیات نوشتن زیاد (INSERT/UPDATE) مناسب نیست.
6. ایندکس فضایی (Spatial Index)
ویژگیها
-
روی ستونهای نوع GEOMETRY یا GEOGRAPHY اعمال میشود.
-
از الگوریتمهای خاص (مثل Tessellation) برای تقسیمبندی فضا استفاده میکند.
CREATE SPATIAL INDEX IX_Locations_Spatial
ON Locations (GeoLocation);کاربرد
7. ایندکس XML
CREATE PRIMARY XML INDEX IX_Employees_XmlData
ON Employees (XmlData);کاربرد
8. ایندکس Full-Text
CREATE FULLTEXT INDEX ON Employees (Resume)
KEY INDEX PK_Employees;کاربرد
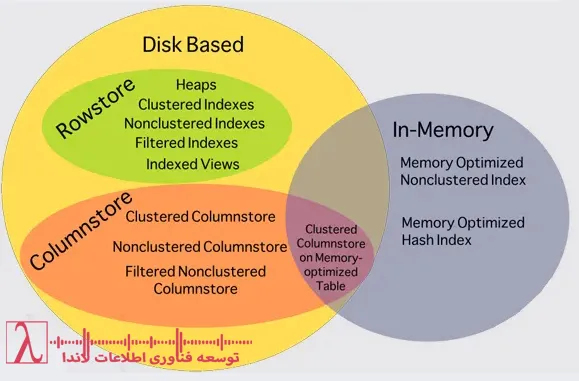
9. ایندکس مبتنی بر دیسک (Disk-Based Index)
ویژگیها
-
دادهها بهصورت دائمی روی دیسک (هارد دیسک یا SSD) ذخیره میشوند.
-
برای اکثر سناریوهای پایگاه داده که پایداری دادهها مهم است، استفاده میشود.
-
سرعت دسترسی به دادهها به عملکرد دیسک وابسته است.
CREATE NONCLUSTERED INDEX IX_Employees_Disk
ON Employees (FirstName);مزایا
-
پایداری بالا به دلیل ذخیرهسازی دائمی.
-
مناسب برای جداول بزرگ که در حافظه جا نمیشوند.
معایب
-
کندتر از ایندکسهای مبتنی بر حافظه به دلیل تأخیر I/O دیسک.
-
وابستگی به سرعت سختافزار ذخیرهسازی.
کاربرد
10. ایندکس مبتنی بر حافظه (In-Memory Index)
ویژگیها
-
از ساختارهای بهینهشده مثل Hash Index یا Non-Clustered Bw-Tree استفاده میکند.
-
دادهها در حافظه نگهداری میشوند و نیازی به دسترسی به دیسک ندارند.
-
معمولاً با جداول In-Memory (Memory-Optimized Tables) استفاده میشود.
CREATE TABLE InMemoryEmployees (
EmployeeID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 10000),
FirstName NVARCHAR(50),
LastName NVARCHAR(50)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);مزایا
-
سرعت بسیار بالا به دلیل حذف تأخیر I/O دیسک.
-
مناسب برای عملیات تراکنشی با حجم بالا (High Throughput).
معایب
-
نیاز به حافظه زیاد دارد و برای جداول بزرگ ممکن است هزینهبر باشد.
-
در صورت قطع برق، دادهها ممکن است از دست بروند، مگر اینکه گزینه پایداری (Durability) فعال باشد.
کاربرد
مدیریت ایندکسها
-
تحلیل عملکرد: از Execution Plan در SSMS برای بررسی استفاده از ایندکسها استفاده کنید.
-
حذف ایندکسهای بلااستفاده: با دستور DROP INDEX فضای اضافی را آزاد کنید.
-
تعادل بین خواندن و نوشتن: ایندکسهای زیاد میتوانند عملیات نوشتن را کند کنند.
-
انتخاب بین دیسک و حافظه: برای سیستمهای با نیاز به سرعت بالا، In-Memory و برای پایداری، Disk-Based را انتخاب کنید.
نتیجهگیری
سوالات متداول (FAQ)
1. ایندکس خوشهای و غیرخوشهای چه تفاوتی دارند؟
ایندکس خوشهای دادهها را بهصورت فیزیکی مرتب میکند، اما ایندکس غیرخوشهای فقط مسیر اشاره به دادهها را نگه میدارد.
2. آیا ساخت ایندکس زیاد باعث کندی سیستم میشود؟
بله، بهخصوص در عملیات INSERT و UPDATE، زیرا هر ایندکس باید بهروزرسانی شود.
3. بهترین نوع ایندکس برای جداول بزرگ چیست؟
برای جداول تحلیلی بزرگ، Columnstore Index بهترین انتخاب است.
4. چگونه بفهمیم ایندکس استفاده نمیشود؟
با استفاده از DMVها و Execution Plan در SQL Server Management Studio
پیشنهاد مطالعه: Cover Index در SQL Server
تماس و مشاوره با لاندا
انتخاب درست نوع ایندکس و مدیریت هوشمندانه آن، میتواند سرعت کوئریها را چندین برابر کند و فشار بر منابع سرور را کاهش دهد.
شرکت توسعه فناوری اطلاعات لاندا با تجربه تخصصی در بهینهسازی SQL Server، آماده است تا ایندکسهای پایگاه داده شما را تحلیل، طراحی و پیادهسازی کند.


No comment