ایندکسهای ستونی (Columnstore index) یکی از نوآوریهای مهم SQL Server هستند که اولین بار در نسخه ۲۰۱۲ معرفی شدند. این نوع ایندکسها روشی کاملاً متفاوت برای ذخیرهسازی دادهها ارائه میدهند که بهخصوص در انبارهای داده (Data Warehouses) و جداول بزرگ، عملکرد کوئریها را بهصورت قابل توجهی بهبود میبخشند؛ بهطوریکه در برخی موارد، سرعت اجرای کوئریها تا ده برابر افزایش مییابد.
چرا ایندکسهای ستونی اهمیت دارند؟
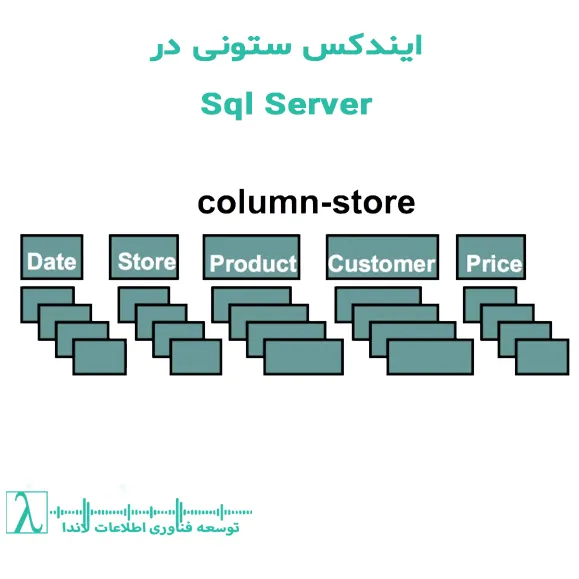
در سیستمهای سنتی پایگاه داده، دادهها بهصورت ردیفی (Rowstore) ذخیره میشوند، یعنی دادههای یک ردیف بهصورت پشت سر هم نگهداری میشوند. اما در ایندکسهای ستونی، دادهها بر اساس ستونها ذخیره میشوند. این تفاوت باعث میشود که در عملیات تحلیلی که فقط به برخی ستونها نیاز داریم، صرفهجویی عظیمی در مصرف حافظه و زمان انجام شود.
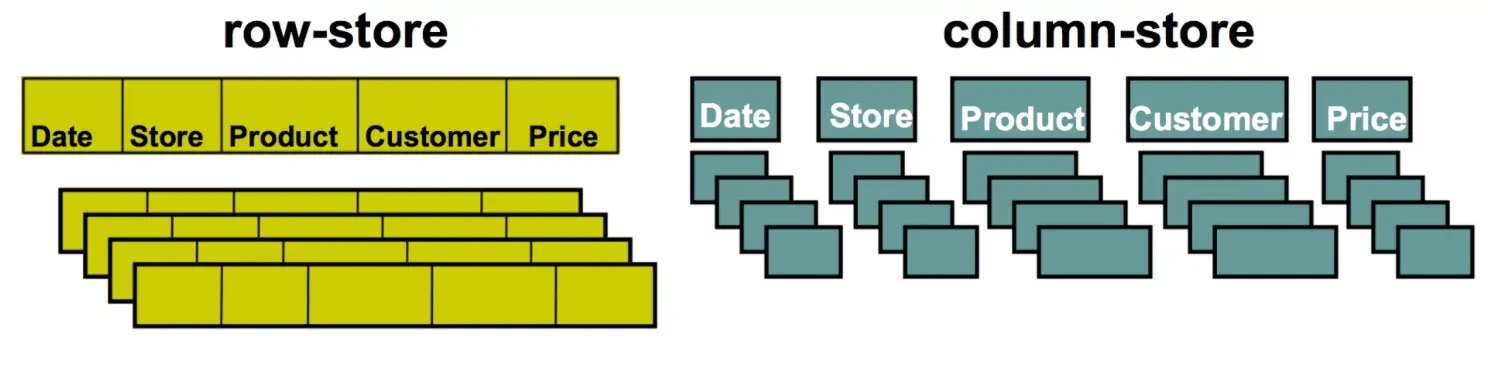
معماری ایندکسهای ستونی و تفاوت با ایندکس ردیفی
ایندکس ردیفی (Rowstore Index)
در این نوع ایندکس، دادهها به صورت کامل و ردیفی ذخیره میشوند؛ یعنی تمامی ستونهای یک ردیف در کنار هم قرار دارند. ساختارهای دادهای مانند درخت B-Tree برای این نوع ایندکسها استفاده میشوند. این روش برای عملیات تراکنشی (OLTP) عالی است، اما برای کوئریهای تحلیلی بزرگ چندان بهینه نیست.
ایندکس ستونی (Columnstore Index)
در این روش، دادهها بهصورت ستونی و جداگانه برای هر ستون ذخیره میشوند. به جای ذخیره کل ردیف در یک صفحه، مثلاً ستون اول چند هزار ردیف پشت سر هم در یک بلوک قرار میگیرد، سپس ستون دوم و به همین ترتیب. این روش مزایای زیادی دارد:
- فشردهسازی بالا: چون دادههای هر ستون همنوع هستند، الگوریتمهای فشردهسازی بهتر عمل میکنند و حجم ذخیرهسازی کاهش مییابد.
- سرعت بالاتر خواندن دادهها: وقتی کوئری فقط به چند ستون نیاز دارد، SQL Server فقط آن ستونها را بارگذاری میکند، که باعث کاهش شدید I/O و حافظه مصرفی میشود.
- پردازش دستهای (Batch Mode): موتور پایگاه داده میتواند تعداد زیادی ردیف را بهصورت همزمان پردازش کند که سرعت اجرای کوئریها را بهخصوص در تحلیلهای آماری و تجمیعی بهشدت بالا میبرد.
پیشنهاد مطالعه: Batch Mode on Rowstore پیادهسازی عملی برای گزارشهای تحلیلی سریع بدون بازطراحی کامل
گروههای ردیف و بخشهای ستون
ایندکسهای ستونی دادهها را به واحدهای منطقی به نام گروه ردیف (Row Group) تقسیم میکنند. هر گروه ردیف حداقل شامل ۱۰۲۴۰۰ ردیف و حداکثر تا حدود ۱ میلیون ردیف است. برای مثال، اگر جدولی ۲.۱ میلیون ردیف داشته باشد، تقریباً دو گروه ردیف با ۱ میلیون ردیف و یک گروه کوچکتر به نام گروه دلتا (Delta Group) تشکیل میشود.
گروه دلتا جایی است که ردیفهای جدید وارد شده قرار میگیرند تا زمانی که به اندازه کافی بزرگ شوند و به یکی از گروههای ردیفی اصلی تبدیل شوند. این گروه دلتا با استفاده از ایندکسهای B-Tree در کنار ایندکس ستونی نگهداری میشود و فرایند انتقال دادهها از گروه دلتا به گروههای اصلی، به نام فرآیند حرکت Tuple (Tuple Mover)، بهصورت خودکار انجام میشود.
این معماری امکان میدهد که ایندکس ستونی بهروزرسانی و درج دادهها را بهتر مدیریت کند.
مزایای اصلی ایندکسهای ستونی
- کاهش قابل توجه حجم ذخیرهسازی: فشردهسازی موثر دادهها باعث کاهش فضای مورد نیاز میشود.
- بهبود چشمگیر سرعت اجرای کوئریهای تحلیلی: بهخصوص کوئریهایی که روی ستونهای خاصی کار میکنند.
- پردازش همزمان دادهها (Batch Processing): با کاهش تعداد عملیات I/O، اجرای کوئریها بسیار سریعتر انجام میشود.
- کاهش بار I/O: فقط ستونهای مورد نیاز خوانده میشوند، نه کل ردیف.
نمونه عملی: ایجاد ایندکس ستونی و مقایسه عملکرد
ابتدا یک جدول ساده به نام FactFinance در دیتابیس آزمایشی SQLTreeoDemo ایجاد میکنیم:
CREATE TABLE FactFinance (
FinanceKey INT PRIMARY KEY,
AccountKey INT,
Amount MONEY,
TransactionDate DATE,
Description NVARCHAR(200)
);
سپس یک ایندکس خوشهای (Clustered Index) روی ستون FinanceKey ایجاد میکنیم:
CREATE CLUSTERED INDEX IX_FactFinance_FinanceKey
ON FactFinance(FinanceKey);
حالا اگر کوئری ساده زیر را اجرا کنیم:
SELECT AccountKey, Amount
FROM FactFinance
WHERE TransactionDate BETWEEN '2023-01-01' AND '2023-12-31';
و طرح اجرایی (Execution Plan) آن را بررسی کنیم، مشاهده میکنیم که SQL Server از اسکن ایندکس خوشهای استفاده میکند.
ایجاد ایندکس ستونی غیر خوشهای (Nonclustered Columnstore Index)
برای بهبود عملکرد، ایندکس ستونی غیر خوشهای روی این جدول ایجاد میکنیم:
CREATE NONCLUSTERED COLUMNSTORE INDEX IX_FactFinance_Columnstore
ON FactFinance (AccountKey, Amount, TransactionDate);
اجرای همان کوئری و بررسی طرح اجرایی نشان میدهد که SQL Server از اسکن ایندکس ستونی استفاده میکند. تحلیل هزینهها به این صورت است:
| شاخص | هزینه I/O تخمینی | هزینه CPU تخمینی |
|---|---|---|
| اسکن ایندکس خوشهای | 0.33 | 0.06 |
| اسکن ایندکس ستونی | 0.07 | 0.06 |
همانطور که میبینید، هزینه I/O تا حد زیادی کاهش یافته است، چون تنها ستونهای مورد نیاز خوانده میشوند. این باعث کاهش فشار روی دیسک و حافظه میشود و سرعت اجرای کوئری را بالا میبرد.
نکات مهم در استفاده از ایندکسهای ستونی (Columnstore Index)
- ایندکس ستونی خوشهای نمیتواند همزمان با ایندکسهای دیگر روی یک جدول باشد. اگر بخواهید ایندکس ستونی خوشهای ایجاد کنید، باید ابتدا ایندکسهای دیگر را حذف کنید یا روی جدول بدون ایندکس این کار را انجام دهید.
- تمام ستونها در ایندکس ستونی خوشهای ذخیره میشوند و این ایندکس نقش اصلی جدول را بازی میکند، برخلاف ایندکسهای نانکلسترد که فقط بخشی از دادهها را پوشش میدهند.
- فرآیند بهروزرسانی ایندکس ستونی بهبود یافته است ولی همچنان برای بارهای کاری تحلیلی و خواندنی (OLAP) بهتر است تا تراکنشی (OLTP).
- اجرای منظم دستور
ALTER INDEX REORGANIZEبرای حفظ سلامت ایندکس و کارایی توصیه میشود، به ویژه برای حرکت دادهها از گروههای دلتا به گروههای ردیفی اصلی.
ایجاد ایندکس ستونی از طریق SQL Server Management Studio (SSMS)
میتوانید به راحتی ایندکس ستونی غیر خوشهای را از طریق محیط گرافیکی SSMS ایجاد کنید:
- وارد کاوشگر اشیاء (Object Explorer) شوید.
- جدول مورد نظر را باز کنید.
- روی شاخه ایندکسها کلیک راست کنید و گزینه “ایندکس جدید” (New Index) را انتخاب کنید.
- در پنجره باز شده، نوع ایندکس را Nonclustered Columnstore Index انتخاب کنید.
- ستونهای مورد نظر را اضافه کنید و ایندکس را ایجاد کنید.
نتیجهگیری
ایندکسهای ستونی در SQL Server یکی از تکنولوژیهای تحولآفرین برای کار با دادههای حجیم و کوئریهای تحلیلی هستند. استفاده درست از آنها میتواند عملکرد دیتابیس شما را بهشدت بهبود بخشد، هزینههای سختافزاری را کاهش دهد و سرعت پاسخگویی به کوئریهای پیچیده را افزایش دهد.
اگر در سازمان شما با دادههای بزرگ و انبار داده کار میکنید، یادگیری عمیق و استفاده بهینه از ایندکسهای ستونی، سرمایهگذاری ارزشمندی است.
سؤالات متداول (FAQ)
1. ایندکس ستونی چه تفاوتی با ایندکس ردیفی دارد؟
ایندکس ردیفی دادهها را بهصورت کامل و پشت سر هم ذخیره میکند، در حالیکه ایندکس ستونی دادهها را بر اساس ستونها جداگانه ذخیره میکند. این تفاوت باعث افزایش چشمگیر سرعت کوئریهای تحلیلی و کاهش مصرف حافظه میشود.
2. آیا ایندکس ستونی برای همه نوع بار کاری مناسب است؟
خیر، ایندکسهای ستونی بیشتر برای بارهای کاری تحلیلی (OLAP) مناسب هستند و در بارهای تراکنشی (OLTP) ممکن است عملکرد مطلوبی نداشته باشند.
3. آیا میتوان همزمان از ایندکس ستونی خوشهای و ایندکسهای دیگر استفاده کرد؟
خیر، ایندکس ستونی خوشهای جایگزین ساختار اصلی جدول میشود و نمیتوان همزمان ایندکسهای دیگر را روی همان جدول نگه داشت.
4. چگونه میتوان ایندکس ستونی را از طریق SSMS ایجاد کرد؟
از طریق Object Explorer در SSMS، روی شاخه ایندکسها کلیک راست کرده و گزینه “ایندکس جدید” را انتخاب کنید. سپس نوع ایندکس را Nonclustered Columnstore Index انتخاب کرده و ستونهای مورد نظر را اضافه کنید.
5. آیا ایندکس ستونی باعث کاهش مصرف دیسک میشود؟
بله، به دلیل فشردهسازی مؤثر دادههای همنوع در هر ستون، حجم ذخیرهسازی بهطور قابل توجهی کاهش مییابد.
تماس و مشاوره با لاندا
آیا آمادهاید عملکرد دیتابیس خود را متحول کنید؟
شرکت لاندا با تیمی متخصص در بهینهسازی SQL Server، آماده است تا به شما در طراحی، پیادهسازی و آموزش ایندکسهای ستونی کمک کند.
از مشاوره رایگان تا اجرای پروژههای حرفهای، ما در کنار شما هستیم.
همین حالا تماس ✆ بگیرید یا فرم درخواست مشاوره را در وبسایت ما پر کنید تا یک قدم به دیتابیس سریعتر و بهینهتر نزدیکتر شوید!


No comment