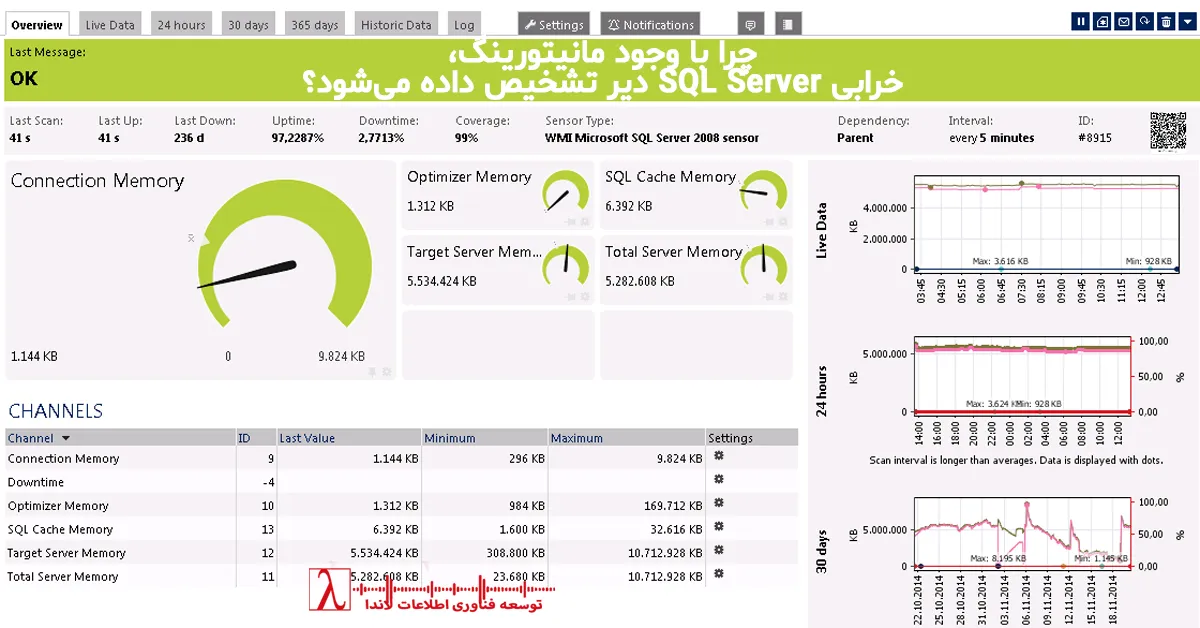
در بسیاری از سازمانها، مانیتورینگ SQL Server وجود دارد. داشبورد هست، Alert تعریف شده، لاگها جمعآوری میشوند و حتی ابزارهای گران قیمت هم خریداری شدهاند. با این حال، یک اتفاق تکراری همچنان رخ میدهد:
- مشکل جدی پیش میآید، اما دیر فهمیده میشود.
- کاربران زودتر از تیم فنی متوجه کندی میشوند.
- مدیران قبل از تیم IT از اختلال خبر میگیرند.
و در نهایت، سؤال آشنا مطرح میشود: «پس این همه مانیتورینگ دقیقاً چه چیزی را پایش میکرد؟»
این مسئله تصادفی نیست و به کمکاری فردی هم ربطی ندارد. ریشه مشکل معمولاً در برداشت اشتباه از مفهوم Monitoring نهفته است.
مانیتورینگ داریم، اما Observability نداریم.
بسیاری از سازمانها Monitoring را با Observability یکی میدانند، در حالی که این دو یکسان نیستند.
Monitoring به این سؤال پاسخ میدهد:
- آیا چیزی از آستانه عبور کرده است یا نه؟
اما Observability تلاش میکند بفهمد:
- چرا این وضعیت به وجود آمده است؟
در SQL Server، مانیتورینگ سنتی معمولاً روی این موارد متمرکز است:
- CPU
- Memory
- Disk IO
- Space
- Availability
اینها لازم هستند، اما کافی نیستند.
مشکل اینجاست که بیشتر خرابیها از جنس Resource نیستند.
آنها از جنس رفتار هستند؛ رفتار Query، رفتار Workload، رفتار کاربران و حتی رفتار Deployment.
چرا خرابیها دیر دیده میشوند؟ ریشههای واقعی مسئله
۱. مانیتورینگ مبتنی بر Threshold، نه رفتار
بخش زیادی از Alertها بر اساس عدد تعریف شدهاند:
- CPU بالاتر از ۸۰٪
- Disk Latency بالاتر از X
- Memory کمتر از Y
اما بسیاری از مشکلات SQL Server قبل از رسیدن به این Thresholdها آغاز میشوند.
مثلاً:
- یک Query جدید وارد سیستم میشود که Execution Plan ناپایدار دارد.
- TempDB بهتدریج تحت فشار قرار میگیرد.
- Lockها به صورت مقطعی بالا میروند، اما هنوز بحرانی نیستند.
در این شرایط، سیستم هنوز «سبز» است، اما مسیر خرابی شروع شده.
۲. تمرکز روی سرور، نه روی Workload
مانیتورینگ کلاسیک سرورمحور است:
- سرور سالم است یا نه؟
- منابع در چه وضعیتی هستند؟
اما کاربران به سرور اهمیت نمیدهند.
آنها به پاسخ این سؤال اهمیت میدهند:
- چرا گزارش دیر Load میشود؟
- چرا عملیات ثبت سفارش کند شده؟
- چرا Query که دیروز سریع بود، امروز کند است؟
وقتی مانیتورینگ به Workload وصل نباشد، مشکل دیر دیده میشود.
۳. Alert Fatigue و بیاعتمادی به هشدارها
در بسیاری از سازمانها:
- Alert زیاد است
- هشدارها تکراری هستند
- اکثر آنها false positive محسوب میشوند
در نتیجه:
- تیم Ops به Alertها عادت میکند
- هشدارها نادیده گرفته میشوند
- Alert واقعی در میان Noise گم میشود
این وضعیت یکی از خطرناکترین حالتهای پایش است.
۴. نبود Context در Alertها
یک Alert بدون Context معمولاً این شکل است:
- CPU بالا رفت
اما سؤالهای اصلی بیپاسخ میمانند:
- کدام Query؟
- کدام Database؟
- کدام کاربر؟
- از چه زمانی؟
- نسبت به چه چیزی غیرعادی است؟
وقتی Context وجود نداشته باشد، تشخیص ریشه مشکل زمانبر میشود.
۵. فاصله بین مانیتورینگ و تصمیم عملیاتی
در بسیاری از تیمها:
این فاصله معمولاً پیامدهای مشخصی دارد؛ مدیران داده را میبینند، اما تیمها تصمیمگیری را به تعویق میاندازند و در نهایت تصمیم یا با تأخیر گرفته میشود یا اصلاً گرفته نمیشود. Monitoring بدون Runbook عملی، فقط تولید نمودار است.
نشانههای سازمانهایی که مشکل را دیر میفهمند.
اگر این الگوها آشنا هستند، احتمالاً مسئله همینجاست:
- کاربران اولین گزارشدهنده اختلال هستند.
- مشکل بعد از SLA شناسایی میشود.
- Root Cause Analysis همیشه بعد از بحران انجام میشود.
- تیم Ops دائماً در حالت Reactive کار میکند.
- داشبوردها زیادند، اما تصمیمها کماند.
این نشانهها معمولاً به ضعف ابزار اشاره نمیکنند، بلکه به ضعف طراحی پایش اشاره دارند.
مانیتورینگ مؤثر SQL Server چه تفاوتی دارد؟
مانیتورینگ مؤثر چند ویژگی مشخص دارد:
۱. رفتارمحور است، نه عددمحور
۲. به Query و Workload متصل است.
۳. Context تولید میکند.
۴. به Runbook ختم میشود.
۵. قابل اقدام است، نه فقط قابل مشاهده
اجزای کلیدی یک پایش حرفهای SQL Ops
Queryهای بحرانی
- شناسایی Queryهای پرتکرار
- شناسایی Regressionهای Plan
- پایش Duration و IO بهصورت روندی
Lock و Blocking
- تشخیص الگوهای Blocking
- تحلیل دورهای Lock Escalation
- تفکیک رفتار نرمال و غیرنرمال
پایش TempDB
- Growth Pattern
- Allocation Contention
- Usage بر اساس Object
بررسی تغییرات
- Deployment
- Index Changes
- Configuration Drift
بخش بزرگی از خرابیها دقیقاً بعد از تغییرات رخ میدهند.
چرا داشتن ابزار کافی نیست؟
ابزار فقط داده تولید میکند.
تشخیص، تصمیم و اقدام به طراحی فرآیند وابسته است.
بدون این موارد:
- Definition of Normal
- Owner مشخص
- سناریوی پاسخ
- SLA عملیاتی
حتی بهترین ابزار هم باعث تشخیص دیرهنگام میشود.
الگوی پیشنهادی لاندا برای پایش SQL Server
رویکرد پیشنهادی بر سه اصل استوار است:
۱. تعریف «رفتار نرمال» قبل از تعریف Alert
۲. اتصال Monitoring به Runbook
۳. تمرکز بر تجربه مصرفکننده، نه فقط سرور
در این الگو:
- هر Alert معنا دارد.
- هر هشدار صاحب دارد.
- هر هشدار مسیر اقدام مشخص دارد.
اشتباهات رایج در مانیتورینگ SQL Server
- کپی Threshold از اینترنت
- تمرکز بیش از حد روی CPU
- نادیده گرفتن Query Pattern
- نبود بازبینی دورهای Alertها
- جدا بودن مانیتورینگ از DBA
این اشتباهات باعث میشوند مشکل بسیار دیر دیده شود.
نتیجهگیری
داشتن مانیتورینگ بهتنهایی نشانه بلوغ عملیاتی نیست. آنچه تفاوت ایجاد میکند، کیفیت پایش است، نه تعداد ابزار. تا زمانی که:
- پایش رفتار محور نشود.
- Context تولید نشود.
- و تصمیم عملیاتی تعریف نشود.
خرابی SQL Server همچنان دیر تشخیص داده خواهد شد.
سوالات متداول (FAQ)
1. آیا مشکل از ابزار مانیتورینگ است؟
در اغلب موارد خیر. مشکل از طراحی پایش و فرآیند پاسخ است.
2. آیا مانیتورینگ بدون DBA مؤثر است؟
معمولاً خیر. تفسیر دادهها به تجربه DBA وابسته است.
3. از کجا باید اصلاح را شروع کرد؟
از شناسایی Workloadهای بحرانی و تعریف رفتار نرمال آنها.
4. آیا این رویکرد فقط برای SQL Server است؟
خیر، اما SQL Server به دلیل پیچیدگی Workload بیشترین آسیب را میبیند.
پایش حرفهای SQL Server؛ از ابزار تا تصمیم عملیاتی
در سازمانهایی که با تشخیص دیرهنگام خرابی، Alertهای بیاثر و ناپایداری SQL Server مواجه هستند، تیم لاندا خدمات طراحی پایش حرفهای SQL Ops، بازطراحی Alertها، تعریف Runbook و اتصال مانیتورینگ به تصمیم عملیاتی را ارائه میدهد.
این خدمات شامل:
- ارزیابی وضعیت فعلی Monitoring
- شناسایی نقاط کور پایش
- طراحی چارچوب Alert مؤثر
- و آمادهسازی SQL Server برای Ops پایدار است.
برای دریافت مشاوره تخصصی پایش و Monitoring حرفهای SQL Server، با کارشناسان لاندا تماس ✆ بگیرید.


No comment