 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید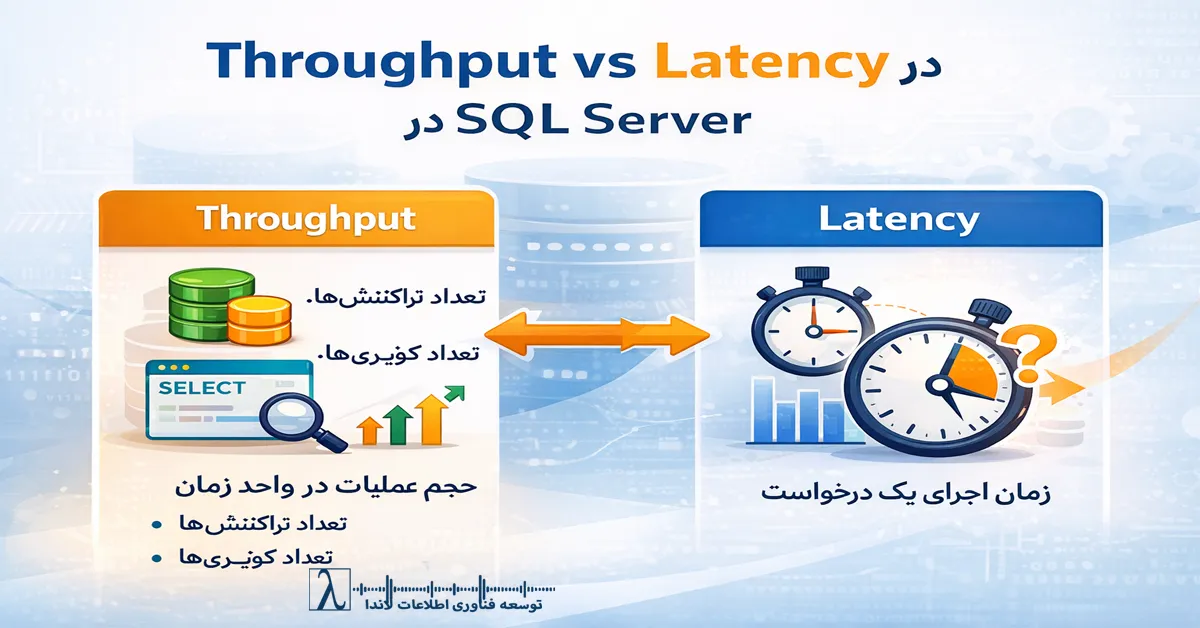
در بسیاری از سازمانها، وقتی صحبت از Performance در SQL Server میشود، نگاه اولیه فقط روی سرعت اجرای یک کوئری است. مدیران اغلب میپرسند: «این کوئری چند میلیثانیه اجرا میشود؟». اما تجربه نشان داده است که سرعت یک کوئری معیار سلامت کل سیستم نیست.
سلامت واقعی یک دیتابیس سازمانی زمانی مشخص میشود که بتواند در بازههای زمانی مشخص، حجم بالایی از درخواستها را بدون افت عملکرد پردازش کند. این همان مفهومی است که با نام Throughput شناخته میشود.
اگر Latency نشان میدهد یک درخواست چقدر طول کشیده است، Throughput پاسخ میدهد: «در یک بازه زمانی مشخص، چند درخواست با موفقیت پردازش شد؟».
در محیطهای Production با کاربران و Jobهای متعدد، معمولاً Throughput از Latency اهمیت بیشتری دارد.
تعریف دقیق Throughput در SQL Server
به میزان کار انجام شده توسط SQL Server در یک بازه زمانی مشخص گفته میشود. این معیار به سرعت یک عملیات وابسته نیست، بلکه ظرفیت کلی سیستم برای پاسخگویی به حجم درخواستها را نشان میدهد.
شاخصهای رایج برای اندازهگیری
- Transactions per Second (TPS): تعداد تراکنشهای کاملشده در ثانیه
- Batch Requests/sec: تعداد Batch Request پردازش شده در ثانیه
- Queries per Minute: تعداد Query اجرا شده در دقیقه
- MB Read/Write per Second: میزان داده خوانده یا نوشته شده در ثانیه
- Log Flush per Second: تعداد دفعات فلش شدن Log در ثانیه
فرمول ساده:
اجزای فرمول
حجم عملیات انجام شده
این قسمت نشاندهنده مقدار کاری است که سیستم انجام میدهد.
بسته به نوع سیستم یا دیتابیس، میتواند شامل موارد زیر باشد:
تعداد تراکنشها (Transactions)
تعداد Batch Requestها
تعداد Queryهای اجرا شده
حجم داده خوانده یا نوشته شده (MB)
تعداد Log Flushها
مثال: اگر در یک ثانیه ۱۰۰ تراکنش کامل شده باشد، حجم عملیات انجام شده = 100 تراکنش.
واحد زمان
این همان بازه زمانی است که میخواهیم Throughput را برای آن محاسبه کنیم.
معمولاً ثانیه (sec) یا دقیقه (min) استفاده میشود.
مثال: اگر ۱۰۰ تراکنش در یک ثانیه انجام شود، واحد زمان = ۱ ثانیه.
اهمیت فرمول
Throughput نشان میدهد که ظرفیت واقعی سیستم برای پاسخگویی به حجم درخواستها چقدر است. بر خلاف Latency که فقط زمان یک درخواست را اندازه میگیرد، و تصویر کلی سلامت سیستم را نشان میدهد.
تفاوت Throughput و Latency
یکی از اشتباهات رایج مدیران IT این است که Throughput و Latency را یکی میدانند. این دو مفهوم اگرچه مرتبط هستند، اما اهداف کاملاً متفاوتی دارند.
| معیار | Latency | Throughput |
|---|---|---|
| تمرکز | سرعت اجرای یک درخواست | حجم کل عملیات در واحد زمان |
| واحد اندازهگیری | میلیثانیه (ms) | Request/sec یا Transaction/sec |
| مناسب برای | بررسی تک کوئری | بررسی سلامت کل سیستم |
| خطر رایج | کوئری سریع اما سیستم ضعیف | سیستم پایدار اما تک کوئری کند |
مثال:
یک کوئری ممکن است تنها 50ms طول بکشد، اما اگر کل سیستم توان پردازش ۲۰ درخواست در ثانیه داشته باشد، در ساعات پیک با صف طولانی و Wait بالا مواجه میشود.
چرا Throughput شاخص واقعی سلامت SQL Server است.
در محیطهای Production، سیستم تنها یک کوئری را اجرا نمیکند. شرایط معمول شامل:
- صدها کاربر همزمان
- Jobهای پسزمینه و ETL
- APIهای فعال و Queryهای همزمان
- گزارشهای تحلیلی و Real-time Reporting
اگر سیستم نتواند حجم این درخواستها را مدیریت کند، حتی با کوئریهای بهینه، مشکلات زیر بروز میکند:
- صف شدن Sessionها
- افزایش Wait Time
- رشد Blocking و Locking
- افت محسوس تجربه کاربری
- Timeout و Failover
نتیجه: Throughput پایین یعنی سیستم نزدیک به مرز اشباع است و حاشیه امن عملیاتی ندارد.
عوامل مؤثر بر Throughput
زیرسیستم I/O
سرعت دیسک و Storage تاثیر مستقیم روی توان عملیاتی دارد. کندی خواندن و نوشتن باعث ایجاد صف I/O میشود و Throughput کاهش مییابد.
سناریو عملی: در یک بانک، یک فایل Log روی Storage کند بود. تراکنشها منتظر Log Flush میماندند و کل سیستم توانایی پردازش بیش از ۱۲۰ Batch/sec نداشت، حتی با CPU و Queryهای بهینه.
اشباع CPU
زمانی که مصرف CPU بهصورت پایدار بالای ۸۰٪ است، توان پردازش همزمان کاهش مییابد. CPU Saturation معمولاً نشاندهنده نزدیک بودن سیستم به سقف Throughput است.
فشار
حافظه (Memory Pressure)
کمبود حافظه باعث کاهش Page Life Expectancy و افزایش دسترسی به دیسک میشود که در نهایت Throughput را محدود میکند.
Locking و Blocking
طراحی نامناسب تراکنشها یا Queryهای طولانی میتواند باعث ایجاد Lock و Blocking شود و ظرفیت پردازش همزمان را کاهش دهد.
طراحی Index
ایندکسهای بیش از حد (Over-Indexing) یا با Selectivity پایین میتوانند Write Throughput را کاهش دهند. این موضوع به ویژه در سیستمهای OLTP با حجم بالای Insert/Update اهمیت دارد.
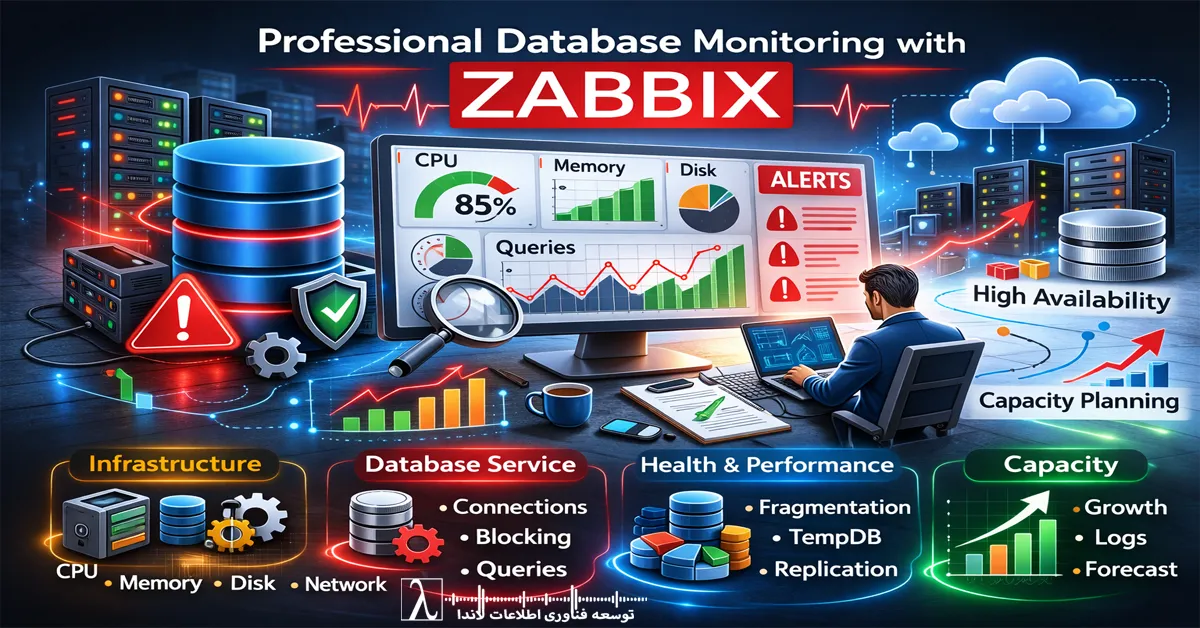
چگونه Throughput را در SQL Server اندازهگیری کنیم؟
Batch Requests/sec
SELECT cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Batch Requests/sec'
تعداد درخواستهای دریافتشده در هر ثانیه را نشان میدهد و یکی از مهمترین شاخصها است.
Transactions/sec
SELECT *
FROM sys.dm_os_performance_counters
WHERE counter_name LIKE '%Transactions/sec%'
حجم تراکنشهای کاملشده را در واحد زمان نمایش میدهد.
Wait Statistics
افزایش Waitها نشاندهنده گلوگاه است:
SELECT wait_type, wait_time_ms
FROM sys.dm_os_wait_stats
ORDER BY wait_time_ms DESC
تحلیل Wait Types کمک میکند Bottleneckهای CPU، I/O یا Locking شناسایی شوند.
Log Flush
سرعت Log Flush تاثیر مستقیم روی توان عملیاتی سیستم OLTP دارد. هر تراکنش منتظر Log Flush میماند، کندی این مرحله Throughput را محدود میکند.
Throughput و برنامهریزی ظرفیت (Capacity Planning)
Throughput پایه اصلی Capacity Planning است. سوال کلیدی ممیزی دیتابیس: «اگر تعداد کاربران دو برابر شود، سیستم چه رفتاری نشان میدهد؟»
اگر مقدار فعلی نزدیک سقف باشد، حتی افزایش جزئی بار کاری میتواند منجر به:
- Timeout
- Deadlock
- Crash یا Failover ناخواسته
شناخت سقف واقعی Throughput امکان پیشبینی رشد و مدیریت ریسک را فراهم میکند.
نشانههای Throughput ناکافی
- CPU بالا در حالی که Queryها کوتاه هستند
- Disk Queue Length افزایش یافته
- رشد ناگهانی Wait Typeهای مرتبط با I/O
- افزایش زمان Log Flush
- افزایش Latency در ساعات پیک
این نشانهها معمولاً به Bottleneckهای زیرساخت یا طراحی بازمیگردند، نه فقط Queryهای تکی.
مثالهای عملی
مثال ۱: Bottleneck در Log File
یک سیستم با Queryهای بهینه و CPU زیر ۶۰٪، توانست تنها ۱۲۰ Batch/sec پردازش کند. علت اصلی کندی Log Flush روی Storage بود، نه Query.
مثال ۲: Over-Indexing و Write Throughput
در یک دیتابیس OLTP، وجود بیش از ۳۰ ایندکس روی جدول Transactions باعث کاهش توان نوشتن شد. پس از حذف ایندکسهای غیرضروری، Throughput نوشتن ۲۵٪ افزایش یافت بدون تغییر در Queryها.
مثال ۳: Memory Pressure
در یک محیط با حجم بالای ETL، کمبود حافظه باعث شد SQL Server مجبور شود صفحات را به سرعت از Buffer Cache خارج کند، که منجر به افزایش I/O و کاهش Throughput شد.
توصیههای عملی برای بهبود
- بهینهسازی Storage و Log: استفاده از SSD یا NVMe برای Log فایلها.
- بررسی و اصلاح Indexها: حذف ایندکسهای غیرضروری و بهبود Selectivity.
- مانیتورینگ CPU و Memory: پیشبینی نیازهای سختافزاری و جلوگیری از Saturation.
- تحلیل Wait Statistics: شناسایی Bottleneck و رفع Lock یا Blocking غیرضروری.
- Batch کردن تراکنشها: کاهش فشار روی I/O و افزایش Throughput.
Throughput و ممیزی حرفهای دیتابیس
در ممیزی حرفهای SQL Server، تحلیل Throughput ضروری است. بدون آن، ممکن است:
- سیستم امروز سالم باشد، اما با رشد کاربران در آینده فروبپاشد.
- گلوگاههای معماری شناسایی نشوند.
- تصمیمات بهینهسازی نادرست اتخاذ شود.
در فرآیند Database Performance Assessment ما شامل:
- تحلیل کامل Throughput
- بررسی Waitها و شناسایی Bottleneck
- پیشبینی ظرفیت آینده سیستم
- ارائه Roadmap فنی و سازمانی برای بهینهسازی
جمعبندی مدیریتی
- Latency: نشاندهنده سرعت اجرای یک درخواست
- Throughput: نشاندهنده ظرفیت واقعی سیستم
در محیطهای سازمانی، ظرفیت پایدار بسیار مهمتر از سرعت یک عملیات تکی است. ممیزی حرفهای دیتابیس بدون تحلیل Throughput ناقص است.
سوالات متداول (FAQ)
۱. Throughput بهتر است یا Latency؟
هر دو مهم هستند، اما در محیطهای سازمانی، Throughput شاخص اصلی سلامت سیستم است.
۲. چگونه محدودیت Throughput را شناسایی کنیم؟
با بررسی Batch Requests/sec، Transactions/sec و Wait Statistics میتوان Bottleneckها را شناسایی کرد.
۳. آیا افزایش Throughput همیشه خوب است؟
خیر، بدون کنترل منابع و معماری مناسب، افزایش Throughput میتواند باعث افت پایدار سیستم شود.
۴. چه عواملی بیشترین تأثیر را روی Throughput دارند؟
زیرسیستم I/O، CPU، حافظه، Locking و طراحی Index.
۵. ممیزی دیتابیس بدون بررسی Throughput کافی است؟
خیر، Throughput پایین ممکن است سیستم را در آینده با بار اضافی فروبپاشد.
ظرفیت واقعی دیتابیس خود را پیش از رسیدن به بحران بسنجید.
آیا میدانید دیتابیس SQL Server شما در ساعات پیک تا چه میزان توان پردازش دارد؟ آیا Bottleneckها پنهان ممکن است عملکرد سیستم را فلج کنند؟
با مشاوره تخصصی Performance Assessment و Database Audit ما، شما:
سقف واقعی Throughput سرور خود را خواهید شناخت.
Bottleneckهای I/O، CPU، Memory و Locking را شناسایی خواهید کرد.
ظرفیت واقعی سیستم برای رشد آینده را پیشبینی خواهید کرد.
یک Roadmap عملی و سازمانی برای بهینهسازی و پایداری دریافت خواهید کرد.
همین امروز اقدام کنید تا از افت عملکرد، Crash یا Failover غیرمنتظره جلوگیری کنید و تجربه کاربری سازمان خود را تضمین کنید.
برای دریافت مشاوره حرفهای و تحلیل کامل، همین حالا با کارشناسان لاندا تماس ✆ بگیرید.



No comment