 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید
فشرده سازی داده در SQL Server یک جدول علاوه بر کاهش حجم دیسک مصرفی، به ما کمک می کند که IO کمتری اتفاق بیفتد. به عبارتی Physical Read و Logical Read کمتری اتفاق می افتد و تعداد صفحات کمتری از روی Disk و حافظه خوانده می شود و همچنین باعث کاهش ترافیک شبکه و نهایتا کوئری شما با سرعت بالاتری اجرا خواهد شد. پس با فشرده سازی داده در SQL Server، دادهها در صفحات کمتری ذخیره می شوند و دستورات Select نیاز به خواندن صفحات کمتری از دیسک دارند.
انواع فشردهسازی داده در SQL Server
SQL Server سه روش اصلی برای فشردهسازی ارائه میدهد:
Row Compression
تبدیل Data Type های Fixed Length به Variable Length
حذف فضای اشغالشده توسط مقادیر
NULLیا صفرمناسب برای دادههایی که تغییرات کمی دارند
صرفهجویی متوسط در فضا، CPU مصرف کمتری نسبت به Page Compression
Page Compression
شامل Row Compression بهعلاوه:
Prefix Compression: ذخیره پیشوندهای تکراری یکبار و ارجاع به آنها
Dictionary Compression: ذخیره مقادیر تکراری در یک دیکشنری و ارجاع به آنها
صرفهجویی بیشتر در فضا، اما مصرف CPU بالاتر
Columnstore Compression
فشردهسازی دادهها در قالب Columnstore Index
بسیار مؤثر برای جداول بزرگ تحلیلی و گزارشگیری
بالاترین میزان صرفهجویی در فضا و بهترین عملکرد برای اسکنهای بزرگ
سناریوهای مناسب برای فشردهسازی
جداول Fact در دیتابیسهای Data Warehouse
پارتیشنهای آرشیوی جداول پارتیشنبندیشده
سیستمهای گزارشگیری با اسکن بالا و تغییرات کم
دادههای تاریخی و آرشیوی
جداولی که بهصورت مداوم UPDATE یا DELETE میشوند، نامزد خوبی برای فشردهسازی نیستند.
مقایسه صرفهجویی در فضا
| روش فشردهسازی | حجم قبل | حجم بعد | صرفهجویی |
|---|---|---|---|
| بدون فشردهسازی | 18MB | — | — |
| Row Compression | 18MB | 10MB | ۴۴% |
| Page Compression | 18MB | 4MB | ۷۸% |
| Columnstore Compression | 18MB | 3MB | ۸۳% |
فشردهسازی داده در SQL Server
همینطور در جداول فشرده، هنگام عملیات Insert، خصوصا عملیات Bulk، مدت زمان بیشتری صرف خواهد شد. از آنجایی که Cost مربوط به Disk و Memory و CPU و Network می باشد، لذا با فشرده سازی داده در SQL Server می توانید Cost مربوط به Disk و Memory را در هنگام Select به شدت کاهش دهید. ولی اگر روی جداول فشرده بخواهید عملیات Update انجام دهید، CPU به شدت درگیر خواهد شد و Cost بالا خواهد رفت. برای اطلاعات بیشتر این لینک را مطالعه کنید.
فشرده سازی را می توانید در موارد زیر انجام دهید:
- A whole table that is stored as a heap.
- A whole table that is stored as a clustered index.
- A whole nonclustered index.
- 4A whole indexed view.
- For partitioned tables and indexes, you can configure the compression option for each partition, and the various partitions of an object do not have to have the same compression setting.
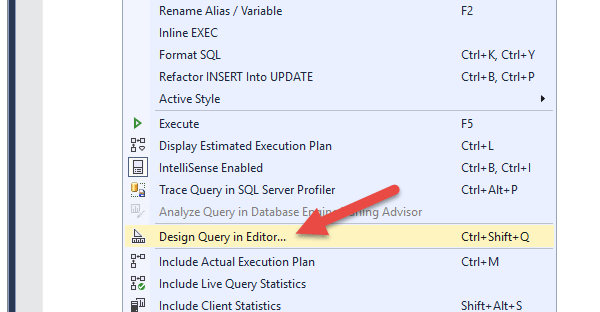
در این قسمت به یک مثال ساده می پردازیم. دیتابیس Adventureworks2019 را انتخاب نموده و سپس در محیط new Query کلیک راست نموده و بر روی گزینه Design Query in Editor مطابق شکل زیر کلیک کنید.
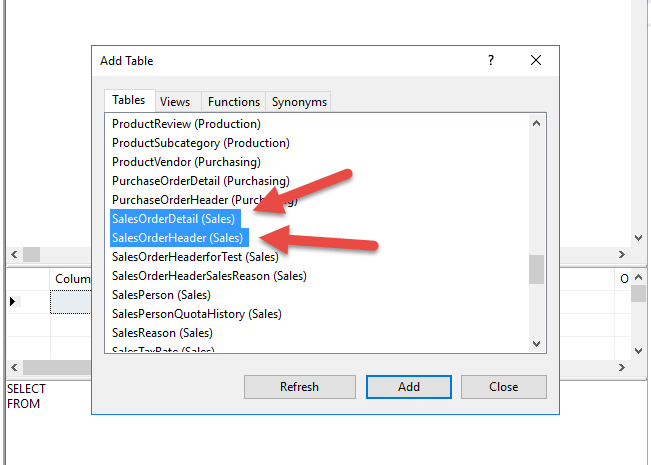
در پنجره ظاهر شده مطابق شکل زیر جداول SalesorderHeader و SalesOrderDetail را انتخاب کنید.
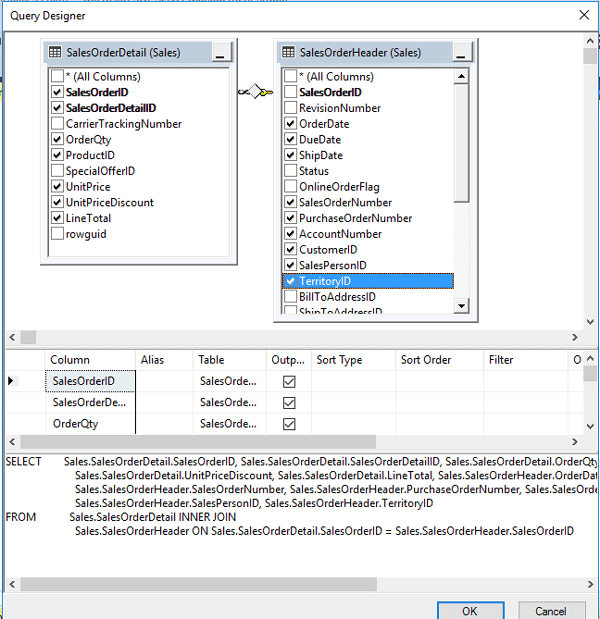
حال مطابق شکل زیر تعدادی از فیلدهای هر دو جدول را به دلخواه انتخاب کنید. در نهایت بر روی دکمه OK کلیک کنید تا کوئری مربوط به این انتخابها برای شما ایجاد شود.
تذکر: اگر بر روی سرور خود Redgate انتخاب نمودهاید، کافیست کل کوئری را انتخاب و بر روی آن کلیک راست و گزینه Format SQL و یا کلیدهای Ctrl+K, Ctrl+Y را بگیرید تا کدهای شما مطابق شکل زیر مرتبط شوند.
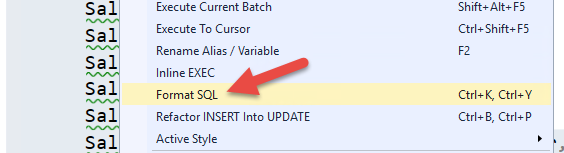
حال در این کوئری قبل از کلمه From از دستور INTO TestDB..tblSales استفاده کنید. (لازم به ذکر است که دیتابیس تستی ما TestDB و اسکیمای ما dbo و نام جدولی که بناست ایجاد شود tblSales نامیده می شود).
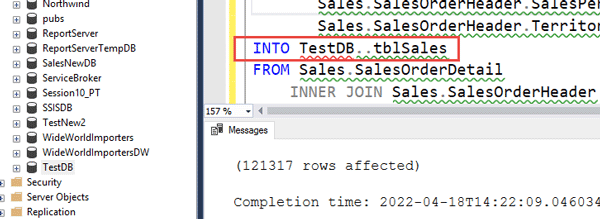
همانطور که در شکل فوق دیده می شود تعداد ۱۲۱۳۱۷ رکورد به جدول tblSales واقع در دیتابیس TestDB منتقل شد. لازم به ذکر است که شما می توانید با استفاده از دستور SP_Spaceused تعداد رکوردهای جدول tblSales را مشاهده نمایید.
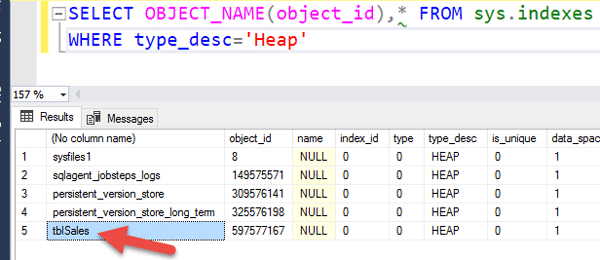
تذکر: جدولی که به این روش ساخته می شود یک جدول Heap می باشد. شما می توانید با کوئری زیر جداول Heap را شناسایی کنید.
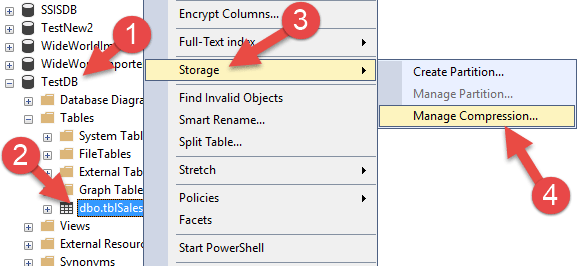
اگر بخواهید جدولی را فشرده کنید، هم می توانید با استفاده از کوئری این کار را انجام دهید و هم می توانید به صورت Wizard ای این کار را انجام دهید. اگر بخواهید به صورت Wizard ای یک جدول را فشرده کنید،کافیست روی جدول مورد نظرد کلیک راست نموده و گزینه Storage و سپس گزینه Manage Compression را کلیک نمایید.
در این صورت پنجره ای مطابق شکل زیر نمایان می شود(پنجره خوش آمد گویی). بر روی دکمه Next کلیک کنید تا به مرحله بعد بروید.
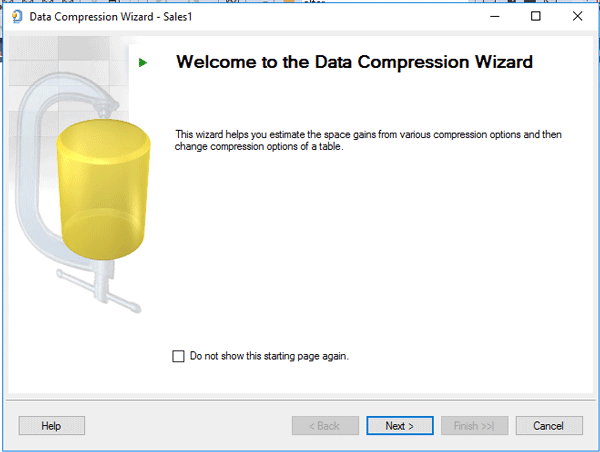
شما می توانید یک جدول را مطابق شکل زیر به دو حالت فشرده کنید. حالت Row Compression و حالت Data Compression (لازم به ذکر است که آیتم دیگر برای فشرده سازی به نام ColumnStore وجود دارد که در اینجا دیده نمی شود).
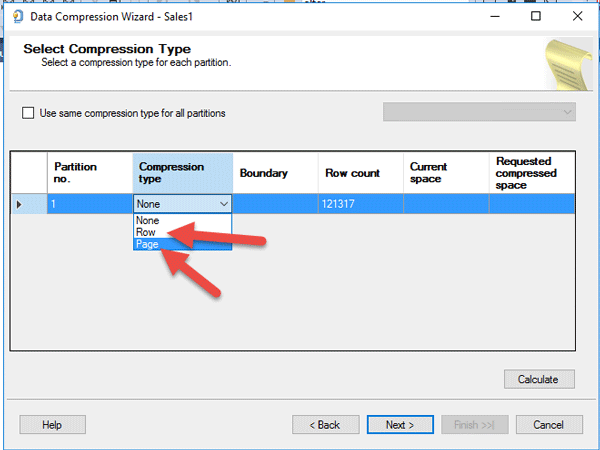
نوع فشرده سازی Row را انتخاب نموده و بر روی دکمه Calculate کلیک می نماییم. شما در پنجره زیر، میزان فشرده سازی بر اساس تکنیک Row Compression را مشاهده می کنید. در اثر این نوع فشرده سازی تا میزان تقریبا هشت مگابایت جدول شما فشرده خواهد شد. این میزان فشرده سازی همیشه ثابت نیست و به داده های شما بستگی دارد.
حالت بعدی فشرده سازی بر اساس Page Compression می باشد. مطابق شکل زیر در اثر این نوع فشرده سازی، حجم جدول شما از تقریبا ۱۸ مگابایت به ۴ مگابایت خواهد رسید(تقریبا یک چهارم).
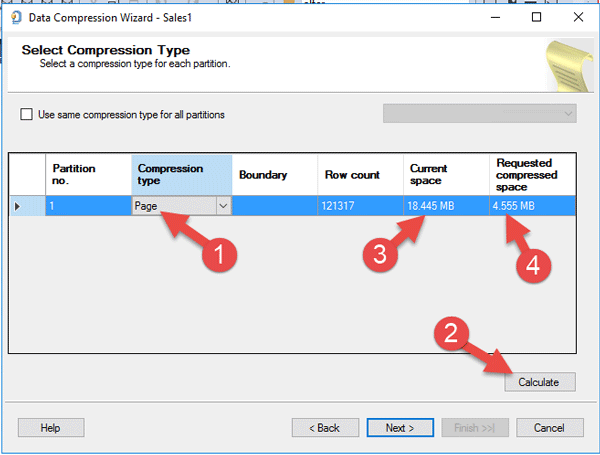
همانطور که در دو شکل فوق می بینید، فشرده سازی در سطح Page به مراتب کلانتر از فشرده سازی در سطح Row می باشد. در شکل فوق بر روی دکمه Next کلیک کرده تا داده های خود را فشرده کنیم.
در اثر فشرده سازی دیتا چقدر در فضا صرفه جویی خواهد شد؟
شما می توانید به کمک SP سیستمی به نام SP_estimate_data_compression_saving مطابق شکل زیر حجم مربوط به جدول را قبل و بعد از فشرده سازی را مشاهده نمایید. این SP مطابق شکل زیر دارای ۵ پارامتر ورودی می باشد.
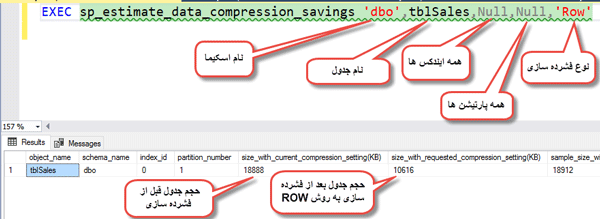
حال اگر بخواهید فشرده سازی داده در SQL Server به روش Row را با فشرده سازی به روش Page و فشرده سازی به روش ColumnStore مقایسه کنیم، مطابق شکل زیر خواهید دید که در اثر فشرده سازی به روش Row حجم جدول ما از 18MB به 10MB تقلیل خواهد یافت و در روش Page حجم جدول از 18MB به 4MB و در روش ColumnStore حجم جدول از 18MB به 3MB تقلیل خواهد یافت.
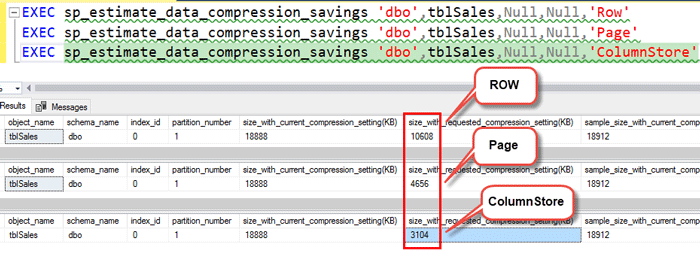 تذکر: با دستور ColumnStore مطابق کد زیر نمی توان داده ها را فشرده کرد، ولی مطابق شکل فوق می توان تخمین زد که اگر روی جدول Column Store Index قرار گیرد به طور اتوماتیک داده ها به چه میزان فشرده خواهد شد (کد زیر غلط است):
تذکر: با دستور ColumnStore مطابق کد زیر نمی توان داده ها را فشرده کرد، ولی مطابق شکل فوق می توان تخمین زد که اگر روی جدول Column Store Index قرار گیرد به طور اتوماتیک داده ها به چه میزان فشرده خواهد شد (کد زیر غلط است):
آیا بهتر نیست که همه جداول فشرده شوند؟
نکتهای که باید به آن توجه کرد، این است که فشرده سازی داده در SQL Server جداول باعث کاهش سرعت دستورات Insert و Delete و Update می شود، ولی به شدت باعث افزایش سرعت Select می شود. مخصوصا در جداول Fact مربوط به دیتابیس های Data Warehouse و پارتیشن های آرشیو جداول مربوط به جداول پارتیشن بندی شده (نه پارتیشن مثلا ماه جاری) و دیتابیس های آرشیو و سامانه هایی که از جنس Report هستند و به طور کلی جداولی که دارای Scan بالایی هستند و تقریبا Update روی آنها صورت نمی گیرد، گزینه مناسبی برای فشرده سازی هستند.
سوال: چه عملیاتی در SQL Server وجود دارد که کل جدول را Scan می کنند؟ به بعضی از آنها اشاره خواهیم کرد:
- Cursor
- Order By
- Aggregate Function (چون Group By انجام می دهد)
لذا تا جایی که می توانید از موارد بالا که باعث کاهش Performance می شوند، استفاده نکنید.
تذکر مهم: وقتی جدولی را فشرده می کنید، این جدول Rebuild می شود و تمامی Dirty Page های مربوط به این جدول، روی دیسک، Persist می شوند. پس خود عملیات فشرده سازی هزینه بر می باشد.
وقتی جدولی را بر اساس Row Level Compression فشرده می کنید چه اتفاقی می افتد؟
Data Type هایی که در SQL Server وجود دارد را از یک نگاه به ۲ قسمت میتوان تقسیم بندی کرد:
- Fix Lengthها
دیتا تایپ هایی که Fix Length هستند عبارتند از:
- عددی ها مثل: مانند Tinyint , Smallint , int , bigint
- رشته ایی ها مثل:مانند Char , NChar
- تاریخ مثل: مانند SmallDateTime , DateTime , Date , Time
- سایر دیتا تایپ ها: مانند Uniqueidentifier
- Variable Lengthها
مفهوم Row Level Compression
فرض کنید در جدول SalesOrderDetail شما فیلدی به نام OrderQty دارید که دیتا تایپ مربوط به آن را از نوع Int انتخاب کرده اید. حال فرض کنید در آن مقدار عدد ۱۲ را وارد کنید، در این صورت ۴ بایت فضا اشغال خواهد شد. حال اگر عدد ۲۱۴۷۰۰۰۰۰۰ هم وارد کنید باز هم چهار بایت فضا اشغال خواهد شد. وقتی جدولی به روش Row فشرده می شود، الگوریتم فشرده سازی آن به این صورت است که نگاه می کند و میبیند که عدد ۱۲ را می تواند توی یک فضای ۱ بایت هم جای دهد، لذا به جای اینکه فضای ۴ بایت به آن اختصاص دهد، آن عدد ۱۲ را در فضای ۱ بایت جای می دهد. به عبارت بهتر در این الگوریتم Fix Length ها را به Variable Length ها تغییر می یابند.
همچنین در الگوریتم Row برای Null ها فضا دیگر اشغال نمی شود و همچنین در این روش برای صفرها نیز فضا اشغال نمی شود. در نهایت الگوریتم فشرده سازی ROW بیشتر تمرکزش روی Data است. لازم به ذکر است که دیتا تایپ هایی همچون Tinyint و یا SmallDateTime و Uniqueidentifier و Time را نمی توان فشرده کرد.
نکته: اگر قرار باشد، فضای مربوط به عدد ۱۲ که از ۴ بایت به ۱ بایت رسانده شود، شما بیایید عدد ۱۲ را بنا به هر دلیلی به عدد ۱۲۰۰ تغییر دهید در این صورت Page Split رخ داده و باعث کاهش Performance می شود. به خاطر همین است که توصیه میشود که سعی کنید روی دیتاهایی که Report ای و یا آرشیو هستند عملیات فشرده سازی داده در SQL Server را انجام دهید.
مفهوم Page Level Compression
در الگوریتم فشرده سازی به روش Page Level Compression، به طور پیش فرض Row Level Compression اتفاق می افتد. در ضمن دو تا Compression دیگر نیز در الگوریتم Page Level Compression اتفاق می افتد، یکی Prefix Column Compression و دیگری Dictionary Compression می باشد. اگر در ستون LastName ما ۲ تا فامیلی اکبری داشته باشیم و فرض کنید که طراح دیتابیس دیتا تایپ این فیلد را به اشتباه Char(30) گرفته باشد، قاعدتا باید ۶۰ بایت فضا اشغال می شد.
ولی اگر شما عملیات فشرده سازی (به روش Page) را انجام دهید در این صورت در قدم اول ۵۰ بایت فشرده سازی خواهید داشت، یعنی اول الگوریتم Row را اعمال می کند(به ازاء هر نام اکبری، ۲۵ بایت فضا Save خواهید داشت). در قدم بعدی الگوریتم فشرده سازی به روشPage ،SQL Server می آید، یک نام اکبری را نگه داشته و مابقی را Reference می دهد(شبیه کاری که در Column Store Index انجام می شود). نتیجه اینکه در جداولی که کاردیتالیتی دیتا در ستون ها پایین است (میزان تکرار داده ها بالاست (مثل ستون نام)) در این صورت نتیجه فشرده سازی بسیار متفاوت خواهد بود.
تذکر: فشرده سازی روی ستون های BLOB چندان تاثیرگذار نیست.
اسکریپت مربوط به فشرده سازی به روش Page Level Compressing
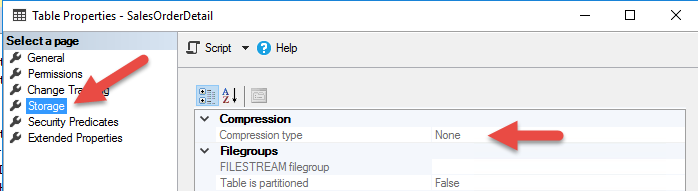
اگر بر روی جدول مورد نظرتان کلیک راست نموده و گزینه Properties را کلیک کنید و در پنجره ظاهر شده مطابق شکل زیر، بر روی Storage کلیک کنید در این صورت در قسمت Compression Type، نوع فشرده سازی را خواهید دید، که در شکل زیر None می باشد.
حال چنانچه از اسکریپت زیر برای فشرده سازی به روش Page Level Compressing استفاده کنید(در کد زیر در ضمن می خواهیم دو تا Core های سرورمان درگیر شوند)
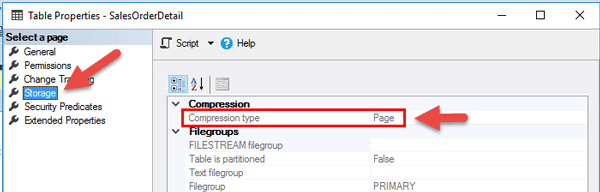
در این صورت مطابق شکل زیر در قسمت Compression Type گزینه Page را خواهید دید.
بعد از اجرای کد مربوط به فشرده سازی با الگوریتم Page Level Compression مطابق شکل زیر در قسمت Compression Type گزینه Page را خواهید دید.
اگر بنا به هر دلیلی از فشرده سازی جدول مورد نظرتان پشیمان شدید کافیست کد زیر را اجرا کنید:
تذکر: شما می توانید ایندکس های نان کلاستر را نیز فشرده کنید. حتی می توانید فقط داده های مربوط به پارتیشن های خاص را فشرده کنید.
تذکر: اگر خواستید یک نان کلاستر ایندکس را فشرده کنید در این صورت می توانید مطابق کد زیر عمل نمایید. به مثال زیر دقت کنید:
نحوه بدست آوردن آبجکت های فشرده شده
برای بدست آوردن آبجکت های فشرده شده در یک دیتابیس می توانیم از کوئری زیر استفاده کنیم:
تذکر: در جداول دیتابیس های Data Warehouse هیچگاه جداول Fact Less Fact فشرده نمی کند. این جدول که به آن Junction Table نیز گفته می شود حاصل ارتباط چند به چند بین جدول Fact و یک جدول Dimension است.
مثال: یک کپی از جدول tblSales با داده هایش با نام tblSales2 بسازید. سپس جدول اول یعنی tblSales را با الگوریتم Page فشرده کنید.
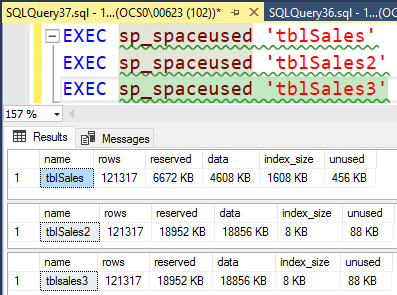
مشاهده حجم اشغالی توسط دو جدول tblSales و tblSales2 توسط گزارش های خود SQL Server
در این صورت پنجره ای مطابق شکل زیر نمایان می شود.
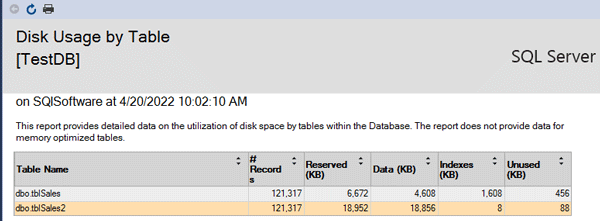
در قدم بعدی می خواهیم Cost دو کوئری را به کمک Execution Plan دو کوئری زیر را با هم مقایسه کنیم:
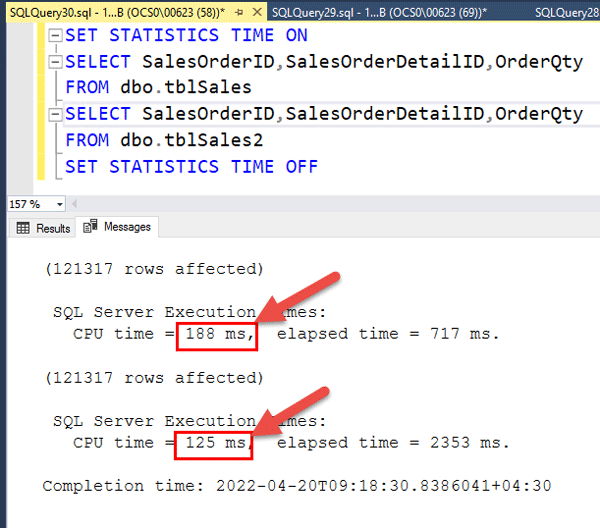
Actual Execution Plan رو فعال کنید و یک Select از دو جدول بگیرید در این صورت خواهید دید که Cost حالت فشرده ۲۳% و Cost جدول غیرفشرده ۷۷% می باشد.
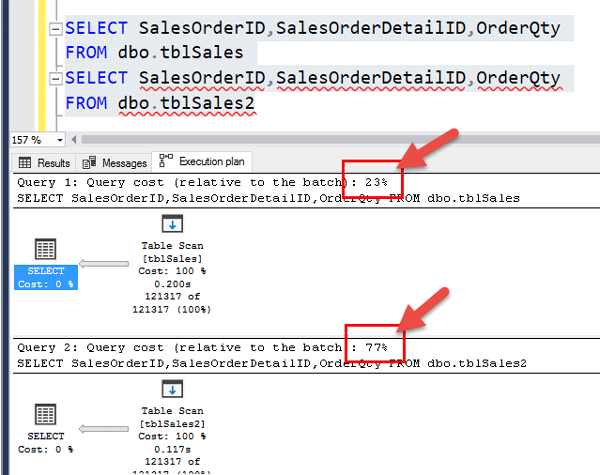
در قدم بعدی، مطابق شکل زیر به کمک دستور Set Statistics IO ON آمار مربوط به تعداد Physical Read و Logical Read مربوط به دو جدول را بدست آورده و با هم مقایسه کنید. همانطور که مشاهده می کنید آمار تعداد IO های مربوط به Logical Reads مربوط به جدول فشرده ۵۷۶ عدد می باشد(یعنی ۵۷۶ عدد Page از هارد دیسک خونده و آورده به حافظه) و آمار تعداد IO های مربوط به Logical Reads مربوط به جدول عادی ۲۳۵۷ عدد می باشد.
به این نکته توجه کنید که Cost ،CPU Usage مربوط به جدول فشرده مطابق شکل زیر بالاتر می رود که کاملا طبیعی است.
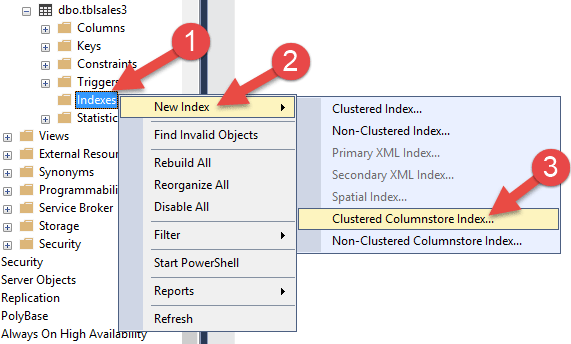
در مرحله بعدی، جدول سوم درست کنید و داده های آن را مطابق کوئری زیر پر کنید و سپس روی آن یک Columnstore Index درست کنید.
کافیه در جدول جدید یعنی tblSales3 که یک جدول Heap است کلیک راست کرده و گزینه New Index و سپس گزینه Clustered Columnstore Index را مطابق شکل زیر کلیک کنید.
حال اگر بخواهیم حجم ۳ جدول را با هم مقایسه کنید، شکلی مطابق شکل زیر خواهید داشت.
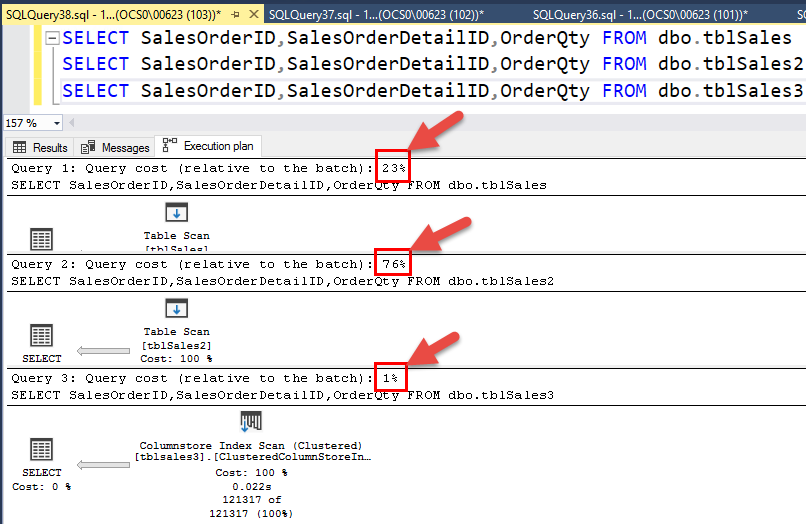
نتیجه گیری
Cost سه جدول را با استفاده از Execution Plan مشاهده کنید، مطابق شکل زیر خواهید دید که روی جدول سوم که Columnstore Index زده شده است، میزان Cost، یک درصد می باشد و جدول اول که با الگوریتم Page فشرده شده است میزان Cost آن ۲۳% شده است و جدول عادی یعنی tblSales میزان Cost اش ۷۶% می باشد.
پرسشهای متداول (FAQ)
۱. آیا فشردهسازی همیشه باعث بهبود عملکرد میشود؟
خیر. اگر جدول شما زیاد UPDATE یا DELETE میشود، فشردهسازی ممکن است باعث افزایش مصرف CPU و کاهش عملکرد شود.
۲. بهترین روش فشردهسازی کدام است؟
برای دادههای تحلیلی و آرشیوی بزرگ، Columnstore بهترین گزینه است. برای دادههای نیمهساختیافته با تغییرات کم، Page Compression مناسبتر است.
۳. آیا میتوان فقط بخشی از جدول را فشرده کرد؟
بله. در جداول پارتیشنبندیشده، میتوانید فقط پارتیشنهای خاص را فشرده کنید.
۴. آیا ایندکسها هم فشرده میشوند؟
بله. هم ایندکسهای کلاستر و هم نانکلاستر را میتوان فشرده کرد.
ارتباط و مشاوره
اگر قصد دارید پرفورمنس SQL Server خود را بهینه کنید و حجم دیتابیس را بهشکل چشمگیری کاهش دهید، تیم ما در شرکت لاندا آماده ارائه مشاوره، آموزش و اجرای تخصصی فشردهسازی برای پروژههای شماست.




نظری داده نشده