 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید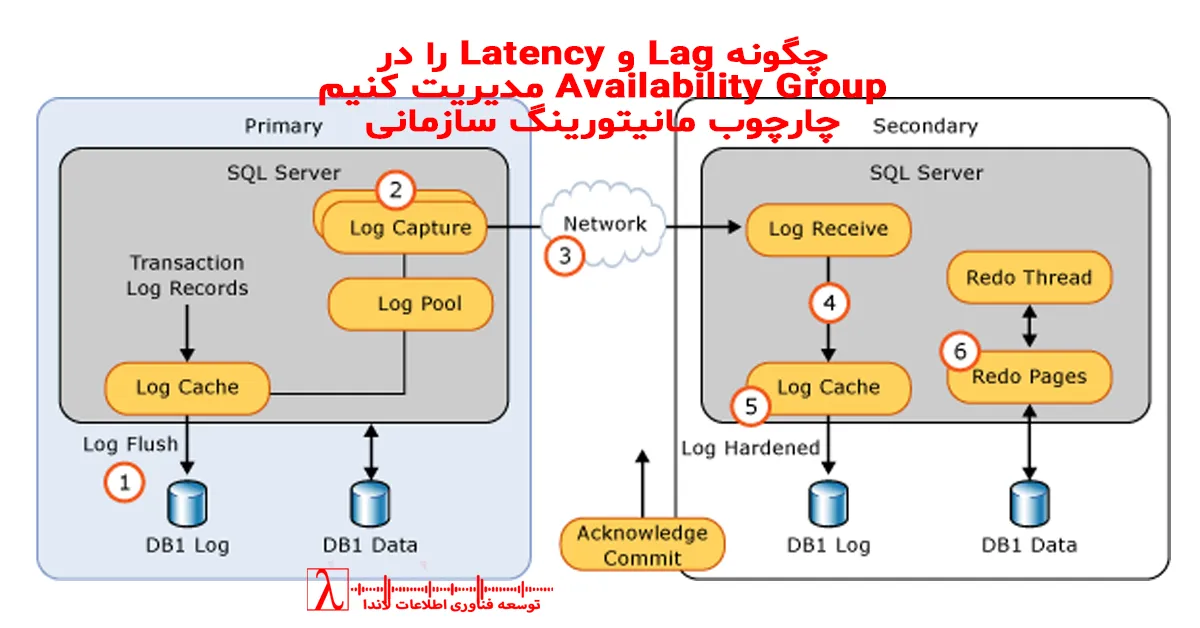
مفهوم تداوم خدمات و دسترس پذیری بالا در سازمانها زمانی واقعی و قابل اتکا می شود که نه تنها معماری High Availability یا همان HA به شکل اصولی طراحی شود، بلکه عملکرد آن نیز به طور مداوم پایش گردد. یکی از مهمترین عناصر در پایش زیرساخت Always On Availability Group، نظارت دقیق بر Replication Lag و Data Latency است. این دو شاخص تعیین می کنند که آیا Replicaها هماهنگ و در وضعیت سالم هستند یا در انتقال دادهها دچار تاخیر شدهاند. این تاخیرها میتوانند پیامدهای جدی برای سرویسهای حیاتی سازمان ایجاد کنند که شامل ریسک از دست رفتن داده، ناسازگاری داده و اختلال در Failover میشود.
۱. اهمیت سازمانی Monitoring Lag و Latency در AG
Availability Group در SQL Server یکی از قدرتمندترین معماریهای دسترسپذیری برای بانکهای اطلاعاتی است. اگرچه AG طراحی شده است تا Replicaها را همواره در وضعیت همگام نگه دارد، اما شرایط واقعی زیرساخت سازمانها همیشه مطابق استاندارد نیست. عواملی مانند محدودیت پهنای باند، بار پردازشی زیاد، حجم زیاد تراکنشها، Storage با عملکرد ضعیف و مشکلات شبکه میتوانند به سرعت باعث ایجاد تاخیر شوند.
چرا پایش Lag و Latency برای سازمان حیاتی است؟
• تضمین یکپارچگی داده ها
در صورت افزایش Lag، Replicaها نسخههای متفاوتی از داده خواهند داشت. این وضعیت برای سازمانها با سرویسهای حساس قابل قبول نیست.
• پیشگیری از Failover خطرناک
اگر Replica دارای تاخیر باشد اما Failover اتفاق بیفتد، بخشی از دادهها از دست می رود. مانیتورینگ لحظهای این خطر را حذف می کند.
• کاهش ریسک DR Site
سازمانها معمولا Replicaها را در سایت پشتیبان قرار می دهند. Latency بالا بین دو مرکز داده می تواند تاثیر مستقیم روی قابلیت بازیابی داشته باشد.
• تحلیل عملکرد زیرساخت
با بررسی شاخصهای تاخیر می توان ضعفهای شبکه، Storage یا I/O را کشف کرد.
• پیشگیری از اختلالات آینده
Lag به عنوان Early Warning عمل می کند و سازمان را از وقوع بحرانهای احتمالی آگاه می کند.
بنابراین مانیتورینگ Lag و Latency یک اقدام تکنیکی ساده نیست بلکه یک ضرورت مدیریت ریسک و عملیات سازمانی است.
۲. مفاهیم کلیدی Lag و Latency در Availability Group
۲.۱. Log Send Queue
این شاخص نشان میدهد چه مقدار دیتا در حال انتظار برای ارسال به Replica است.
افزایش این مقدار معمولا نشانه کندی شبکه، CPU یا Storage است.
۲.۲. Redo Queue
Replicaهای Asynchronous برای اعمال دادهها از Redo Log استفاده میکنند. اگر این مقدار زیاد شود یعنی Replica نمیتواند تراکنشها را کافی سریع Replay کند.
۲.۳. Send Latency
این شاخص مدت زمان ارسال Log از Primary به Replica را اندازه میگیرد.
۲.۴. Redo Latency
مدت زمان اعمال دادهها در Replica را نشان میدهد.
۲.۵. Recovery Point Objective و تاثیر آن
اگر Latency زیاد باشد، RPO در خطر قرار میگیرد. مثلا اگر سازمان RPO برابر ۳۰ ثانیه دارد، اما Latency شما ۴ دقیقه است، این مغایر SLA خواهد بود.
۳. ابزارهای داخلی SQL Server برای Monitoring Latency
SQL Server مجموعهای از Dynamic Management Views ارائه میکند که امکان نظارت دقیق بر عملکرد AG را فراهم میسازد.
۳.۱. DMV اصلی: sys.dm_hadr_database_replica_states
شاخص های مهم:
• log_send_queue_size
• redo_queue_size
• synchronization_state
• last_received_time
• last_redone_time
SQL Query پیشنهادی برای مانیتورینگ:
SELECT
ag.name AS AGName,
ar.replica_server_name,
drs.database_id,
drs.log_send_queue_size,
drs.redo_queue_size,
drs.last_received_time,
drs.last_redone_time
FROM sys.dm_hadr_database_replica_states drs
JOIN sys.availability_replicas ar ON drs.replica_id = ar.replica_id
JOIN sys.availability_groups ag ON ar.group_id = ag.group_id;
۳.۲. sys.dm_os_performance_counters
کانترهای حیاتی:
• Log Bytes Sent per sec
• Redo Bytes Per sec
• Send Queue Size
• Redo Queue Size
۳.۳. Extended Events
ایونتهای مهم:
• hadr_log_transport_diagnostics
• hadr_db_commit_mgr_harden
این روش برای ریشهیابی مشکلات پیچیده عالی است.
۴. ابزارهای خارجی برای مانیتورینگ Lag و Latency
سازمانها معمولا علاوه بر ابزارهای داخلی، از ابزارهای زیر نیز استفاده میکنند:
۴.۱. SQL Server Monitoring Tools
• SentryOne
• Redgate SQL Monitor
• Idera SQL Diagnostic Manager
• Quest Foglight
مزیت ها:
• داشبوردهای آماده
• آلارمهای دقیق و قابل تنظیم
• گزارشدهی سازمانی
• تحلیل تاریخی Trend
۴.۲. SIEM و Observability Tools
• Elastic Stack
• Splunk
• Datadog
• Prometheus
• Grafana
این ابزارها امکان اتصال به Log، Metric و Alert را فراهم می کنند و برای سازمانهای بزرگ توصیه میشوند.
۵. Threshold های استاندارد برای Lag و Latency
باید توجه داشت که Threshold ها به سازمان، SLA، زیرساخت و نوع بار تراکنشی وابسته است. اما استانداردهایی منطقی وجود دارد.
۵.۱. Threshold پیشنهادی سازمانی
| شاخص | وضعیت سالم | وضعیت هشدار | وضعیت بحرانی |
|---|---|---|---|
| Log Send Queue Size | کمتر از ۵۰ مگابایت | ۵۰ تا ۲۰۰ مگابایت | بیشتر از ۲۰۰ مگابایت |
| Redo Queue Size | کمتر از ۱۰ مگابایت | ۱۰ تا ۱۰۰ مگابایت | بیش از ۱۰۰ مگابایت |
| Latency | کمتر از ۵ ثانیه | ۵ تا ۳۰ ثانیه | بیشتر از ۳۰ ثانیه |
| Sync Replica State | SYNCHRONIZED | SYNCHRONIZING | NOT SYNCHRONIZING |
۶. Root Causeهای رایج Latency در AG
۶.۱. مشکلات شبکه
• پهنای باند پایین
• Packet loss
• فاصله جغرافیایی زیاد بین دیتاسنترها
۶.۲. بار زیاد روی Primary
CPU بالا و حجم زیاد تراکنش باعث عقب افتادگی ارسال Log خواهد شد.
۶.۳. ضعف Storage
Replicaها برای Redo نیاز به I/O سریع دارند.
۶.۴. Backup های همزمان
Backup I/O روی همان دیسک تاثیر مستقیم بر Redo Queue دارد.
۶.۵. Anti Virus یا ابزارهای امنیتی
برخی ویروسیابها فایل Log را قفل میکنند.
۷. Runbook عملی و سازمانی برای Monitoring Lag و Latency
در این بخش یک Runbook رسمی و قابل استفاده برای تیم های DBA و مرکز عملیات شبکه ارائه میشود.
۷.۱. مرحله نخست: شناسایی وضعیت AG
گام ۱: اجرای DMV ها و ثبت مقادیر
گام ۲: بررسی وضعیت Availability Group Dashboard
گام ۳: ثبت Snapshot از Queue Sizes
گام ۴: بررسی Log Transport Status
۷.۲. مرحله دوم: تعیین شدت مشکل
اگر Log Send Queue بیش از ۲۰۰ مگابایت است:
وضعیت بحرانی است و نیاز به اقدام فوری وجود دارد.
اگر Latency بیش از ۳۰ ثانیه است:
Failover نباید انجام شود.
۷.۳. مرحله سوم: تحلیل Root Cause
الف. بررسی شبکه
• ping و latency تست شود.
• بررسی packet loss
• بررسی مصرف پهنای باند
ب. بررسی بار پردازشی
• وضعیت CPU
• تراکنشهای سنگین
• Jobهای زمانبندی شده
پ. بررسی Storage
• IOPS
• Latency در Read و Write
• تداخل Backup
ت. بررسی Event Log و Error Log
۷.۴. مرحله چهارم: رفع مشکل
راهکارهای عملی
• افزایش Bandwidth یا تغییر مسیر شبکه
• انتقال Log از دیسکهای کند به Storage پرسرعت
• غیرفعال کردن اسکن فایل Log توسط Anti Virus
• Optimize کردن Queryهای سنگین
• استفاده از Backup Compression
• فعالسازی Network Compression در SQL Server 2022
۷.۵. مرحله پنجم: مستندسازی و اطلاع رسانی
• ثبت Incident Report
• ثبت اقدامات اصلاحی
• ارائه Trend گزارش به مدیریت فناوری اطلاعات
• پایش دوباره وضعیت پس از ۳۰ دقیقه
۸. چک لیست مدیریتی برای سازمان
این چک لیست میتواند برای مدیران فنی، سرپرستان تیم DBA و مدیر شبکه مورد استفاده قرار گیرد:
• آیا برای AG یک داشبورد مانیتورینگ زنده وجود دارد؟
• آیا برای Lag و Latency آستانه هشدار تعیین شده است؟
• آیا ابزار آلارم دهی با Email یا Teams پیکربندی شده است؟
• آیا RPO و RTO سازمان با Latency سنجیده می شود؟
• آیا سند Runbook معتبر و جدید وجود دارد؟
• آیا تست های دوره ای Failover انجام می شود؟
• آیا Latency متوسط ماهانه ثبت و تحلیل می شود؟
• آیا تیم شبکه و DBA در یک کانال مشترک همکاری می کنند؟
تماس و مشاوره با لاندا
اگر سازمان شما نیاز به پیاده سازی یک مانیتورینگ حرفه ای و پایدار برای Availability Group دارد، تیم لاندا میتواند برای طراحی داشبورد، تعریف Thresholdهای سازمانی، پیاده سازی Runbook، رفع مشکلات Latency و بهینه سازی زیرساخت Always On در کنار شما باشد.
برای دریافت «راه اندازی مانیتورینگ HA» و مشاوره تخصصی، همین حالا تماس ✆ بگیرید.




نظری داده نشده