 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید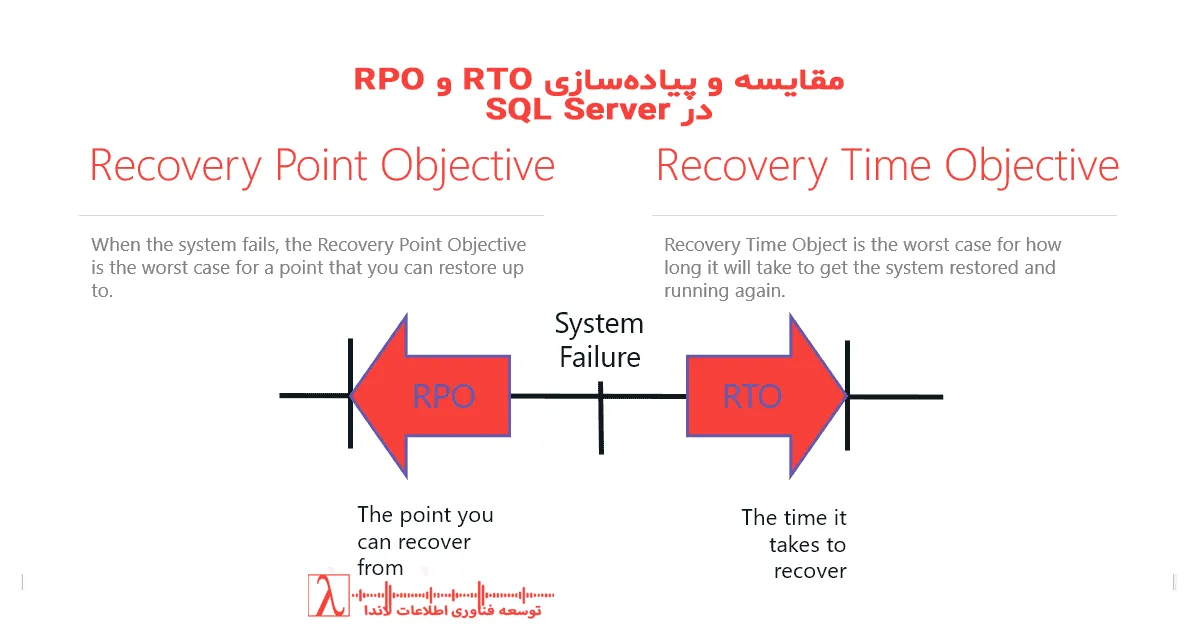
وقتی زمان، از دست رفتن داده مهمتر میشود.
در دنیای پایگاهدادهها، خرابی اجتنابناپذیر است، اما میزان توقف سرویس (RTO) و حجم دادهای که از دست میرود (RPO)، انتخاب ماست. این دو شاخص حیاتی تعیین میکنند که پس از وقوع خرابی، چقدر طول میکشد تا سیستم دوباره در دسترس قرار گیرد و چه مقدار داده از آخرین بکاپ تا لحظه حادثه از بین میرود.
در بسیاری از شرکتها، مدیران فناوری تصور میکنند داشتن بکاپ روزانه کافی است، اما در واقعیت وقتی یک سرور SQL از کار میافتد، همین دو مورد هستند که کیفیت پاسخ به بحران را مشخص میکنند. این دو معیار، پایهایترین اجزای Disaster Recovery Plan (DRP) و High Availability (HA) در SQL Server محسوب میشوند.
در این مقاله، هر دو مفهوم را بهصورت فنی، مقایسهای و اجرایی بررسی میکنیم تا بدانیم چگونه میتوان آنها را در معماریهای مدرن SQL Server بهینه کرد.
RTO و RPO چیستند؟
زمان بازیابی RTO (Recovery Time Objective)
Recovery Time Objective مدت زمانی است که یک سازمان میتواند بدون سرویس فعال بماند پیش از آنکه آسیب تجاری جدی وارد شود.
مثلاً:
اگر RTO شما ۳۰ دقیقه تعریف شده، یعنی باید بتوانید ظرف حداکثر نیم ساعت پس از خرابی، SQL Server را دوباره در دسترس قرار دهید.
نقطه بازیابی RPO (Recovery Point Objective)
Recovery Point Objective مقدار دادهای است که میتوان از دست داد بدون آنکه به کسبوکار آسیب جدی برسد.
مثلاً:
اگر RPO برابر با ۵ دقیقه باشد، یعنی در بدترین حالت فقط ۵ دقیقه داده از بین میرود، چون یا Log Backupها یا Replication در بازههای زمانی کوتاه فعال بودهاند.
تفاوت RTO و RPO
| ویژگی | RTO | RPO |
|---|---|---|
| تعریف | حداکثر زمان مجاز برای بازیابی سرویس | حداکثر میزان داده قابلازدسترفتن |
| هدف | کاهش Downtime | کاهش Data Loss |
| وابستگی به | زیرساخت، بکاپ، سرور ثانویه | استراتژی بکاپ و لاگها |
| ابزارهای مؤثر | Always On, Cluster, Log Shipping | Log Backup, Replication, Mirroring |
| معیار اندازهگیری | دقیقه یا ساعت | ثانیه، دقیقه یا ساعت |
محاسبهی RTO و RPO در SQL Server
۱. محاسبه Recovery Time Objective
به فاکتورهای متعددی بستگی دارد:
- حجم پایگاهدادهها
- سرعت سختافزار و Storage
- روش بازیابی (Full Restore، Log Restore، Standby)
- وجود سرورهای آماده (Failover Node)
فرمول تقریبی
RTO = زمان تشخیص خرابی + زمان بازیابی سیستم + زمان تست و دسترسی کاربر
۲. محاسبه Recovery Point Objective
مستقیماً به فاصلهی بین Backupها یا Replication وابسته است:
RPO = فاصله بین آخرین Backup معتبر تا زمان وقوع حادثه
اگر هر ۱۵ دقیقه Log Backup انجام میدهید، RPO شما ۱۵ دقیقه است.
اما با استفاده از Always On Synchronous Replica ،RPO میتواند تقریباً صفر باشد.
نقش RTO و RPO در معماری SQL Server
۱. در Backup & Restore
اگر تنها روش بازیابی شما بکاپهای روزانه باشد، RTO میتواند چند ساعت و RPO تا ۲۴ ساعت باشد — یعنی خطر بالا.
اما اگر Log Backup هر ۵ دقیقه و Full Backup روزانه بگیرید، RPO کاهش چشمگیری مییابد.
۲. در Log Shipping
Log Shipping یکی از سادهترین روشهای دستیابی به RTO و RPO متوسط است.
با زمانبندی مناسب بین ارسال و Restore لاگها، میتوانید به RTO ≈ ۱۵ دقیقه و RPO ≈ ۵ دقیقه برسید.
۳. Database Mirroring / Always On
در حالت Synchronous Commit، دادهها همزمان روی Replica ذخیره میشوند → RPO تقریباً صفر.
در Asynchronous Commit، سرعت بالاتر است ولی ممکن است چند ثانیه داده از دست برود.
۴. در Failover Cluster
Cluster باعث کاهش RTO میشود چون در زمان خرابی، Node دیگر بلافاصله فعال میگردد، اما RPO همچنان صفر نیست مگر از روشهای همزمانسازی استفاده شود.
مقایسه فناوریهای SQL Server از نظر RTO و RPO
| فناوری | میانگین RTO | میانگین RPO | توضیح |
|---|---|---|---|
| Full + Log Backup | ۳۰–۹۰ دقیقه | ۵–۶۰ دقیقه | مناسب برای سیستمهای کمترافیک |
| Log Shipping | ۱۰–۳۰ دقیقه | ۱–۱۵ دقیقه | راهکار کلاسیک با هزینه کم |
| Database Mirroring (Sync) | < 1 دقیقه | ~۰ دقیقه | سریع ولی در نسخههای جدید منسوخ شده |
| Always On Availability Groups (Sync) | < 1 دقیقه | ~۰ دقیقه | راهکار مدرن HA |
| Asynchronous Always On | چند دقیقه | چند ثانیه تا دقیقه | مناسب برای فواصل جغرافیایی |
| Failover Cluster Instance | ۱–۵ دقیقه | ۰ دقیقه | برای High Availability محلی |
| Replication | وابسته به تنظیمات | وابسته به Delay | مناسب برای Read-Only یا Reporting |
| Azure Geo-Replication | < 60 ثانیه | ~۰ دقیقه | گزینه ابری با SLA بالا |
طراحی استراتژی بهینه RTO/RPO
۱. تحلیل ریسک
پیش از تعیین RTO و RPO، باید ریسکها و Criticality سیستم را ارزیابی کنید:
- بانک اطلاعات مالی → RTO: زیر ۵ دقیقه، RPO: صفر
- سایت فروش آنلاین → RTO: زیر ۳۰ دقیقه، RPO: کمتر از ۵ دقیقه
- سامانه گزارشدهی → RTO: چند ساعت، RPO: ۱ ساعت
۲. انتخاب فناوری مناسب
هیچ راهحل واحدی وجود ندارد، بسته به نیاز سازمان ترکیب زیر پیشنهاد میشود:
| نیاز | فناوری پیشنهادی |
|---|---|
| حداکثر دسترسپذیری | Always On (Sync) + Cluster |
| پایداری منطقهای | Asynchronous AG + Geo Replica |
| هزینه پایین | Log Shipping + Backup |
| محیط ابری | Azure Managed Instance + Auto Failover Groups |
۳. پیادهسازی Backup Layered
برای دستیابی به RPO نزدیک صفر:
- Full Backup روزانه
- Differential Backup ساعتی
- Log Backup هر ۵ دقیقه
- تست مداوم بازیابی (Restore Verification)
ابزارهای عملی برای کنترل RTO و RPO
SQL Server Management Studio (SSMS)
- ابزار مانیتورینگ Backup History
- تست بازیابی و زمان Restore
PowerShell Automation
با استفاده از اسکریپتهای زمانبندیشده میتوان Log Backup و Test Restore را خودکار کرد.
Zabbix
در لاندا، ما از Zabbix هم برای کنترل و هشدار RTO/RPO استفاده میکنیم:
- پایش وضعیت Replicaها
- بررسی تأخیر Log Shipping
- اعلام هشدار در صورت افزایش RTO/RPO از آستانه مجاز
عوامل تأثیرگذار بر بهینهسازی RTO و RPO
| فاکتور | تأثیر |
|---|---|
| نوع Storage | سرعت بازیابی را تعیین میکند |
| تعداد Replica | بر زمان Failover اثر مستقیم دارد |
| فاصله Backupها | تعیینکنندهی RPO |
| سرعت شبکه | مهم در Always On Async |
| تستهای دورهای DR | تنها راه اطمینان از صحت RTO واقعی |
سناریوهای واقعی از پروژههای لاندا
۱ — بانک مرکزی داده
- حجم دیتابیس: ۲ ترابایت
- نیاز: RTO < ۵ دقیقه، RPO = ۰
- راهکار: Always On Sync + Cluster + Azure Backup
۲ — شرکت تولید نرمافزار SaaS
- چند دیتابیس Tenant محور
- نیاز: RTO < ۱۵ دقیقه، RPO < ۵ دقیقه
- راهکار: Log Shipping + Diff Backup + Zabbix Alerts
۳ — مهاجرت به Azure SQL MI
- استفاده از Auto Failover Group
- دستیابی به SLA: RTO < ۳۰ ثانیه، RPO ≈ صفر
مزایا و معایب رویکردهای مختلف
| نوع استراتژی | مزایا | معایب |
|---|---|---|
| Backup محور | ساده و ارزان | RTO و RPO بالا |
| Log Shipping | قابل پیشبینی و پایدار | نیاز به زمانبندی دقیق |
| Always On Sync | کمترین RTO/RPO | هزینه و پیچیدگی بالا |
| Always On Async | مناسب مناطق دور | احتمال اندک از دست دادن داده |
| Cluster محلی | Failover سریع | نیاز به Shared Storage |
چگونه RTO و RPO را به سطح سازمانی برسانیم؟
۱. تدوین SLA رسمی برای هر سامانه
۲. مستندسازی کامل فرایند بازیابی
۳. تست دورهای Disaster Simulation
۴. مانیتورینگ خودکار با Monitor
۵. استفاده از Storageهای پرسرعت SSD/NVMe
نتیجهگیری
Recovery Time Objective و Recovery Point Objective قلب استراتژی بازیابی در SQL Server هستند.
داشتن بکاپ بدون تعریف این دو شاخص، مثل داشتن چتر بدون اطلاع از طوفان است.
در سال ۲۰۲۵، سازمانهای حرفهای نه تنها از Always On و Log Shipping برای دسترسپذیری استفاده میکنند، بلکه با ابزارهایی مثل Zabbix، این شاخصها را بهصورت پویا اندازهگیری و کنترل میکنند.
به یاد داشته باشید:
- هر دقیقه Downtime، هزینهای واقعی برای سازمان دارد.
- هر مگابایت داده از دست رفته، میتواند اعتماد مشتری را نابود کند.
بنابراین طراحی و تست منظم RTO و RPO، از الزامات حیاتی DBA مدرن است.
سوالات متداول (FAQ)
۱. تفاوت بین RTO و RPO چیست؟
RTO زمان لازم برای بازیابی سیستم است، RPO مقدار داده قابل از دست دادن.
۲. آیا Always On میتواند RPO = ۰ ارائه دهد؟
بله، در حالت Synchronous Commit.
۳. چگونه میتوان RTO را کاهش داد؟
با استفاده از Cluster یا Replica آماده (Warm Standby).
۴. آیا RTO و RPO باید برای تمام دیتابیسها یکسان باشد؟
خیر، بر اساس Criticality هر دیتابیس باید جداگانه تعریف شوند.
۵. چه ابزاری برای مانیتورینگ RTO/RPO مناسب است؟
SolarWinds ،Zabbix و SQL Agent Alerts.
خدمات Disaster Recovery و مانیتورینگ SQL Server لاندا
اگر هنوز RTO و RPO سیستمهای خود را نمیدانید، لاندا به شما کمک میکند تا ارزیابی، طراحی و پیادهسازی کامل Disaster Recovery Plan مخصوص محیط SQL Server سازمانتان را انجام دهید.
برای ارزیابی رایگان عملکرد SQL Server، با مشاوران لاندا تماس✆ بگیرید.




سلام وقتتون بخیر
ممنون از اینکه اطلاعاتتون را با ما به اشتراک میگذارید.
سپاس از توجه شما