 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید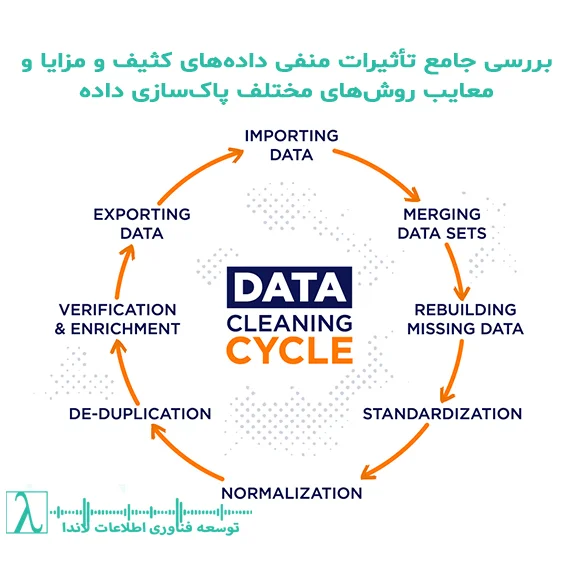
در عصر تحولات سریع دیجیتال، دادهها ستون فقرات هر سازمانی محسوب میشوند. از تحلیلهای مالی گرفته تا استراتژیهای بازاریابی و ارزیابی عملکرد کارکنان، تمامی تصمیمات مبتنی بر دادههای جمعآوری شدهاند. با این حال، دادههای کثیف یا ناصحیح میتوانند باعث اختلال در این فرآیندها و ایجاد هزینههای غیرمنتظره شوند. بنابراین، پاکسازی داده به عنوان یک فعالیت اساسی در بهبود کیفیت داده و تضمین دقت اطلاعات در سازمانها بهکار میرود.
اهمیت پاکسازی دادهها در هوش تجاری
پاکسازی دادهها فرآیندی است که در آن دادههای ناقص، اشتباه، تکراری یا ناسازگار شناسایی و اصلاح میشوند.
این فرآیند شامل مراحل زیر میباشد:
- شناسایی مشکلات: اولین گام، تحلیل دادههای موجود و مشخص کردن نواقص، از جمله دادههای تکراری، نادرست یا ناقص است.
- اصلاح و استانداردسازی: پس از شناسایی مشکلات، از روشهای دستی یا خودکار برای اصلاح دادهها و تبدیل آنها به فرمتهای استاندارد استفاده میشود.
- ادغام و ساختاربندی: دادههای حاصل از منابع مختلف با رویکردهای یکپارچهسازی مجدداً سازماندهی میشوند تا از بروز ناسازگاری جلوگیری شود.
در کل، پاکسازی داده امکان تصمیمگیریهای هوشمندانهتر، کاهش هزینههای اضافه و افزایش بهرهوری سازمان را فراهم میآورد.
تأثیرات منفی دادههای کثیف بر بخشهای مختلف کسبوکار
۱. مدیریت مالی و حسابداری
- گزارشهای مالی نادرست: دادههای ناقص یا اشتباه میتواند منجر به تهیه گزارشهای مالی نادرست گردد که در نتیجه تخصیص اشتباه منابع و بروز مشکلات مالی و حسابرسی میشود.
- تصمیمهای سرمایهگذاری نادرست: عدم دقت در اطلاعات پردازش شده باعث میشود که مدیران سرمایهگذاریهای غلط انجام داده و از فرصتهای سودآور دور بمانند.
۲. بازاریابی و فروش
- تبلیغات غیرهدفمند: استفاده از دادههای قدیمی یا ناقص باعث میشود که استراتژیهای تبلیغاتی به درستی به گروههای هدف ارائه نشود و در نتیجه اثربخشی کمپینها کاهش یابد.
- استراتژیهای قیمتگذاری اشتباه: تحلیلهای نامعتبر و دادههای ناکامل میتواند به تصمیمات اشتباه در قیمتگذاری منجر شود که بازار را از دست بدهد.
۳. مدیریت منابع انسانی
- ارزیابی عملکرد ناعادلانه: دادههای کثیف در اندکسبندی عملکرد و سوابق کاری کارکنان میتواند منجر به تصمیمات اشتباه درباره ارتقاء و پاداش شود.
- افزایش نارضایتی کارکنان: ایجاد بروز خطاهای انسانی بر اساس دادههای ناصحیح موجب کاهش انگیزه و ایجاد تحریف در عملکرد تیمی میشود.
۴. عملیات و زنجیره تأمین
- اختلال در موجودی و سفارشات: اطلاعات نادرست میتواند باعث اشتباه در مدیریت موجودی مواد و سفارشدهی شود؛ بهطوری که یا از یک سو سفارشهای اضافه و یا از سوی دیگر کمبود کالا وجود داشته باشد.
- بهوجود آمدن تداخلهای زنجیره تأمین: ناسازگاری بین دادههای تأمینکنندگان و مشتریان میتواند باعث اختلال در روند سفارش و تحویل کالا گردد.
۵. تحلیل داده و تصمیمگیری استراتژیک
- پیشبینیهای اشتباه: مدلهای تحلیلی و پیشبینی که بر اساس دادههای ناقص ساخته میشوند ممکن است خروجیهای گمراهکنندهای ارائه دهند.
- تصمیمات استراتژیک نامناسب: تصمیمگیریهای کلان بر پایه دادههای اشتباه میتواند باعث انتخاب استراتژیهای نادرست در بازارهای رقابتی شود.
۶. تجربه مشتری و خدمات پس از فروش
- کاهش رضایت مشتری: ارائه پیشنهادات و خدمات بر اساس دادههای نادرست باعث ایجاد تجربه مشتری نامطلوب میشود که در نهایت ممکن است منجر به از دست رفتن مشتریان وفادار شود.
- ضعف در خدمات پشتیبانی: ناهماهنگی در دادههای پشتیبانی مشتری و اطلاعات تماس میتواند منجر به کاهش اثربخشی خدمات مشتری و افزایش نارضایتی آنها گردد.
۷. رعایت مقررات و امنیت اطلاعات
- عدم انطباق با مقررات حقوقی: دادههای ناقص میتوانند باعث عدم رعایت استانداردهای حفاظت از دادهها نظیر GDPR شوند که در نتیجه ممکن است سازمان با جریمههای سنگین مواجه گردد.
- افزایش ریسکهای امنیتی: ناسازگاری و ضعف در کیفیت دادهها میتواند نقاط ضعف امنیتی را ایجاد کند و اطلاعات حساس را در معرض خطر قرار دهد.
بررسی جامع روشهای پاکسازی داده
انتخاب روش مناسب برای پاکسازی داده بستگی به نیازهای کسبوکار، حجم و پیچیدگی دادهها و همچنین منابع موجود دارد. در ادامه به بررسی ۵ روش اصلی پرداخته و مزایا و معایب هر یک را به تفصیل شرح میدهیم.
۱. روشهای دستی (Manual Data Cleansing)
مزایا
- دقت بالا و توجه فردی: متخصصان داده با بررسی دقیق هر رکورد، میتوانند اشتباهات را شناسایی کرده و اصلاحات دقیق انجام دهند.
- امکان شخصیسازی: روش دستی امکان تنظیم اصلاحات بر اساس نیاز ویژه سازمان و شرایط خاص را فراهم میکند.
معایب
- زمانبر بودن: این روش بهویژه در مواجهه با حجمهای عظیم داده زمان زیادی مصرف میکند.
- هزینههای بالای نیروی انسانی: نیاز به استخدام افراد متخصص و پرداخت دستمزدهای بالا همراه است.
- ریسک بروز خطای انسانی: حتی در میان کارشناسان، امکان اشتباهات وجود دارد که ممکن است اصلاحات انجامشده به یک اندازه دقیق نباشند.
۲. الگوریتمهای خودکار (Automated Data Cleansing)
مزایا
- سرعت بالا: الگوریتمهای خودکار میتوانند در زمانهای کوتاه حجمهای بزرگی از دادهها را پردازش و تصحیح کنند.
- کاهش خطای انسانی: اجرای خودکار فرآیند به حذف اشتباهات ناشی از تعامل انسانی کمک میکند.
- همگام با تغییرات: سیستمهای خودکار میتوانند بهطور مداوم بهروزرسانی شوند تا با تغییرات در دادهها سازگار شوند.
معایب
- نیاز به تنظیمات دقیق: برای جلوگیری از حذف اطلاعات مهم، الگوریتمها باید به دقت پیکربندی شوند.
- محدودیت در تشخیص موارد خاص: در شرایط پیچیده و سنتزی ممکن است نتوانند به درستی تعامل کنند.
- سرمایهگذاری اولیه: هزینههای توسعه و راهاندازی این سیستمها ممکن است برای برخی کسبوکارها بالا باشد.
۳. استفاده از تکنیکهای یادگیری ماشین (Machine Learning for Data Cleansing)
مزایا
- تشخیص الگوهای پیچیده: مدلهای یادگیری ماشین قادر به استخراج الگوهای پنهان و شناسایی اشتباهات پیچیده در دادهها هستند.
- خودآموزی و بهبود مستمر: با استفاده از دادههای جدید، مدلها دقت خود را به مرور زمان افزایش میدهند.
- کاهش نیاز به نظارت مداوم: پس از آموزش اولیه، مدلهای یادگیری ماشین به صورت خودکار و بدون دخالت زیاد انسانی عمل میکنند.
معایب
- نیاز به دادههای آموزشی با کیفیت: عملکرد بهینه مدلهای یادگیری ماشین وابسته به داشتن مجموعه دادههای دقیق و معتبر میباشد.
- پیچیدگی فنی بالا: توسعه و تنظیم این مدلها نیازمند تخصصهای فنی و دانش عمیق در زمینه آمار و الگوریتمهای پیشرفته است.
- هزینههای توسعه و نگهداری: اجرای این روش معمولاً هزینههای قابل توجهی برای توسعه و بهروزرسانی مدلها به همراه دارد.
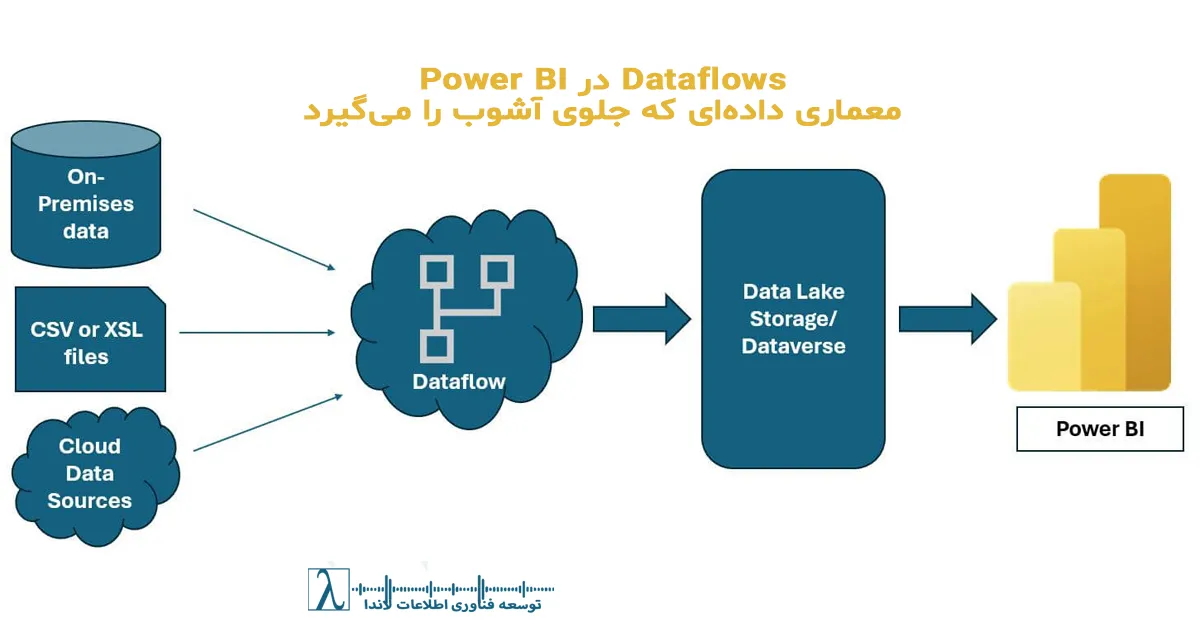
۴. ابزارهای ETL (Extract, Transform, Load)
مزایا
- یکپارچگی دادهها: ابزارهای ETL امکان استخراج، تبدیل و بارگذاری دادهها از منابع مختلف را بهصورت یکپارچه فراهم میکنند که موجب انسجام اطلاعات در سازمان میشود.
- استانداردسازی داده: کمک به تنظیم فرمتها و ساختارهای یکسان برای ورود دادهها به سیستمهای داخلی.
- بهبود کیفیت داده: فرآیندهای پیشرفته ETL میتوانند دادههای ناسازگار را شناسایی و اصلاح کنند.
معایب
- هزینههای نصب و نگهداری: راهاندازی اولیه و نگهداری ابزارهای ETL نیازمند سرمایهگذاریهای مالی و فنی بالاست.
- تنظیمات پیچیده: پیکربندی صحیح و تنظیم دقیق روند استخراج، تبدیل و بارگذاری دادهها از اهمیت ویژهای برخوردار است.
- وابستگی به نرمافزارهای خاص: در برخی موارد، انعطافپذیری ابزارهای ETL ممکن است محدود شده و نیاز به انطباق با نیازهای خاص سازمان داشته باشد.
۵. روشهای آماری (Statistical Data Cleaning)
مزایا
- تشخیص دادههای پرت: با استفاده از مدلهای آماری، میتوان دادههای غیرمنطقی یا مقادیر پرت را شناسایی و اصلاح کرد.
- اصلاح مقادیر گمشده: روشهایی مانند میانگینگیری یا رگرسیون میتوانند در تکمیل دادههای ناقص بهکار گرفته شوند.
- بهبود تحلیلهای بعدی: پس از پاکسازی دادهها با روشهای آماری، دقت تحلیلهای بعدی افزایش مییابد.
معایب
- نیاز به دانش تخصصی: اجرای صحیح روشهای آماری نیازمند آشنایی با مدلهای ریاضی و آماری پیشرفته است.
- ریسک حذف دادههای معتبر: در برخی موارد، دادههای پرت ممکن است اطلاعات ارزشمندی داشته باشند و حذف ناخواسته آنها میتواند تحلیلها را تحریف کند.
- محدودیت در کاربرد: روشهای آماری ممکن است در مواجهه با تغییرات سریع یا دادههای پیچیده عملکرد بهینهای نداشته باشند.
مقایسه جامع روشهای پاکسازی داده
برای انتخاب روش مناسب، یک مقایسه جامع از دیدگاههای مختلف به شرح زیر ارائه میشود:
| روش پاکسازی داده | دقت | سرعت | هزینه | پیچیدگی | وابستگی به منابع انسانی |
|---|---|---|---|---|---|
| روش دستی (Manual) | بسیار بالا | پایین | بالا | متوسط | بسیار زیاد |
| الگوریتمهای خودکار (Automated) | بالا | بسیار بالا | متوسط | بالا | کم |
| یادگیری ماشین (Machine Learning) | بالا | بسیار بالا | بالا | بسیار بالا | بسیار کم |
| ابزارهای ETL (ETL Tools) | بالا | بالا | بسیار بالا | متوسط | کم |
| روشهای آماری (Statistical) | بالا | متوسط | متوسط | بالا | کم |
این جدول به مدیران و تحلیلگران کمک میکند تا با ارزیابی مواردی نظیر دقت، سرعت مورد نیاز، هزینههای مرتبط و پیچیدگیهای فنی، بهترین روش پاکسازی داده را بر اساس نیازهای سازمان خود انتخاب نمایند.
نکات و چالشهای اجرایی در پاکسازی داده
با وجود مزایای فراوان، اجرای هر یک از روشهای پاکسازی داده به چالشهای خاص خود میانجامد:
- هماهنگی بین تیمها: همکاری میان تیمهای IT، تحلیل داده و مدیریت نیازمند هماهنگی دقیق است تا هرگونه تغییر در دادهها با در نظر گرفتن جنبههای مختلف اعمال شود.
- بهروز نگهداشتن الگوریتمها: با توجه به تغییرات سریع در دادهها، الگوریتمهای خودکار و مدلهای یادگیری ماشین باید به طور مداوم بهروزرسانی شوند.
- آموزش و توانمندی نیروی انسانی: رسیدگی دستی به دادهها نیازمند آموزش دقیق و تخصص قوی در زمینه مدیریت دادهها و آمار است.
- مقیاسپذیری: انتخاب روشهای پاکسازی باید بر اساس توانایی سیستم در پردازش حجمهای زیاد داده و امکان گسترش در آینده مد نظر قرار گیرد.
نکات پایانی
چنانچه به دنبال ابزارهای تخصصی و پیشرفته برای پاکسازی دادههای خود هستید، مطالعه جامع درباره روندهای نوین در ETL، یادگیری ماشین و مدیریت داده میتواند نقطه شروع مناسبی باشد. همچنین توجه به بهینهسازی فرآیندهای داخلی و ایجاد یک استراتژی جامع پاکسازی داده، به سازمان شما امکان میدهد تا از دادههای تمیز بهرهمند شده و به سادگی مسیر رشد و پیشرفت در دنیای هوش تجاری را طی کنید.
با به کارگیری روشهای مناسب و ترکیبی، سازمانها میتوانند از اثرات منفی دادههای کثیف جلوگیری کرده و بهبود عملکرد، کاهش هزینهها و افزایش رضایت مشتریان را تجربه کنند. این امر نه تنها در بهبود تصمیمگیریهای استراتژیک مؤثر است، بلکه در ایجاد فرهنگ سازمانی مبتنی بر دادههای دقیق و صحیح نقشی تعیینکننده دارد.
نتیجهگیری
پاکسازی داده از فرآیندهای اساسی در بهبود عملکرد سازمانها و تضمین موفقیت در هوش تجاری به شمار میآید. دادههای تمیز و استاندارد نکته اصلی در دستیابی به تصمیمگیریهای دقیق، بهبود تحلیلهای استراتژیک و افزایش رضایت مشتریان است. هر یک از روشهای پاکسازی از روشهای دستی گرفته تا استفاده از الگوریتمهای پیشرفته یادگیری ماشین دارای مزایا و معایب خاص خود میباشند و انتخاب بهینه از این میان، بستگی به نیازهای کسبوکار، حجم دادهها و منابع موجود دارد.
برای کسب نتایج مطلوب، بسیاری از سازمانها رویکرد ترکیبی را اتخاذ میکنند؛ به عنوان مثال، استفاده از الگوریتمهای خودکار برای پاکسازی اولیه و سپس بازبینی دستی و آماری جهت اطمینان از صحت اطلاعات. این رویکرد چند جانبه همزمان سرعت، دقت و کارایی را بهبود میبخشد و از هر گونه ناهماهنگی جلوگیری میکند.
در نهایت، سرمایهگذاری در فناوریهای نوین پاکسازی داده نظیر ابزارهای ETL و مدلهای یادگیری ماشین، به همراه آموزش مداوم نیروی انسانی، میتواند مزیت رقابتی قدرتمندی برای سازمان ایجاد کند. مدیران و تحلیلگران باید به دنبال راهحلهایی باشند که نه تنها نیازهای فعلی آنها را برآورده کند، بلکه قابلیت رشد و انطباق با تغییرات آینده در بازار را نیز داشته باشد.
تماس و مشاوره با لاندا
برای اطلاعات بیشتر و مشاوره میتوانید از طریق زیر با ما در ارتباط باشید:
مطالب اموزنده و عالی استاد
سپاس از شما