 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید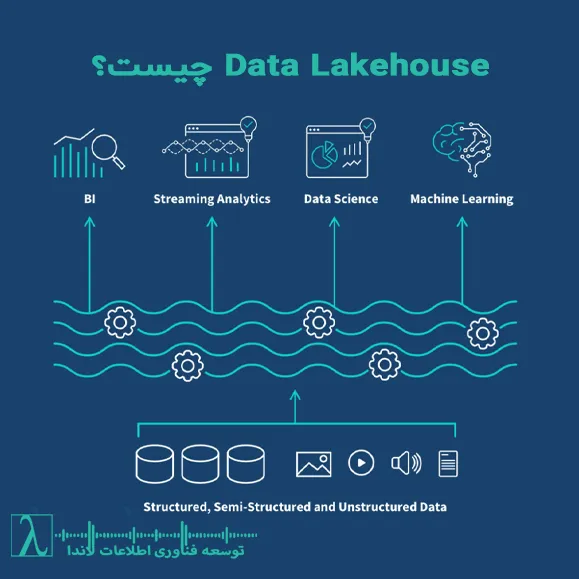
در دنیای امروز، دادهها قلب تپنده هر سازمان هستند. از استارتاپهای کوچک گرفته تا غولهای فناوری، همه میدانند که بدون استفاده بهینه از دادهها، رقابتپذیری امکانپذیر نیست.
سال ۲۰۲۵ شاهد جهشی بزرگ در ترند BI و معماری داده است. یکی از مهمترین این ترندها، Data Lakehouse است؛ معماریای که تلاش میکند بهترین ویژگیهای Data Lake و Data Warehouse را در یک ساختار واحد ترکیب کند.
پیشتر، سازمانها بین انتخاب Data Lake (انعطافپذیر، مقیاسپذیر و ارزان) و Data Warehouse (ساختاریافته و سریع برای کوئری) مردد بودند. اما Data Lakehouse با حذف این دوگانگی، راهحلی یکپارچه ارائه میدهد.
Data Lakehouse چیست؟
Data Lakehouse یک معماری داده ترکیبی است که ویژگیهای کلیدی Data Lake و Data Warehouse را با هم ادغام میکند. هدف آن، فراهم کردن محیطی است که بتواند دادههای ساختاریافته، نیمهساختاریافته و غیرساختاریافته را در یک بستر واحد ذخیره، مدیریت و تحلیل کند.
ویژگیهای اصلی
- ذخیرهسازی ارزان و مقیاسپذیر مثل Data Lake
- ساختار داده و مدیریت متادیتا مثل Data Warehouse
- پشتیبانی از انواع فرمت داده (Parquet، ORC، Avro، JSON و…)
- قابلیت پردازش بلادرنگ برای تحلیل سریع
- پشتیبانی از SQL و زبانهای برنامهنویسی برای کوئری و پردازش
مزایای Data Lakehouse
- یکپارچگی زیرساخت: حذف نیاز به دو سیستم جداگانه (Lake و Warehouse)
- کاهش هزینهها: استفاده از ذخیرهسازی ارزان ابری و کاهش تکرار دادهها
- تحلیل سریعتر: بهینهسازی کوئری و پردازش توزیعشده
- انعطافپذیری بالا: پشتیبانی از انواع داده برای BI، ML و AI
- امنیت و حاکمیت داده: کنترل دسترسی، لاگبرداری و رمزنگاری پیشرفته
معایب و چالشها
- پیچیدگی پیادهسازی: نیاز به تیم باتجربه در معماری داده
- هزینه اولیه بالا: برای مهاجرت و راهاندازی اولیه
- نیاز به ابزارهای مدرن: مثل Delta Lake، Apache Iceberg یا Apache Hudi
کاربردهای Data Lakehouse
- هوش تجاری (BI): ساخت داشبورد و گزارشهای تحلیلی
- علم داده (Data Science): آموزش مدلهای ML با دادههای غنی
- پردازش بلادرنگ: تحلیل آنی دادههای استریم
- مدیریت دادههای چند
- فرمت: تصاویر، ویدئو، متن و لاگ
مطالعه موردی Netflix و Data Lakehouse
Netflix یکی از پیشگامان استفاده از Data Lakehouse است. این شرکت روزانه ترابایتها داده از منابع مختلف جمعآوری میکند: دادههای بیننده، متادیتای محتوا، عملکرد سیستم، لاگ سرورها، و دادههای تعامل کاربر.
چالش Netflix قبل از Lakehouse
- دادهها در سیستمهای جداگانه Lake و Warehouse ذخیره میشدند.
- هماهنگسازی این دادهها زمانبر و پرهزینه بود.
- تیمهای BI و Data Science روی پلتفرمهای جداگانه کار میکردند.
راهحل
Netflix با پیادهسازی معماری Data Lakehouse مبتنی بر Delta Lake روی AWS S3 و موتور پردازش Apache Spark، توانست:
- یکپارچگی دادهها را ایجاد کند.
- هزینه ذخیرهسازی را کاهش دهد.
- سرعت تحلیل را افزایش دهد.
- پشتیبانی از بلادرنگ برای پیشنهاد فیلم و سریال ارائه دهد.
نتایج
- کاهش ۴۰٪ زمان آمادهسازی داده برای مدلهای پیشنهاددهنده
- کاهش ۳۰٪ هزینه ذخیرهسازی
- بهبود تجربه کاربر با پیشنهادهای دقیقتر
بهترین روشهای پیادهسازی
- انتخاب فرمت داده بهینه (مثل Parquet یا ORC)
- استفاده از لایه مدیریت داده (Delta Lake، Iceberg یا Hudi)
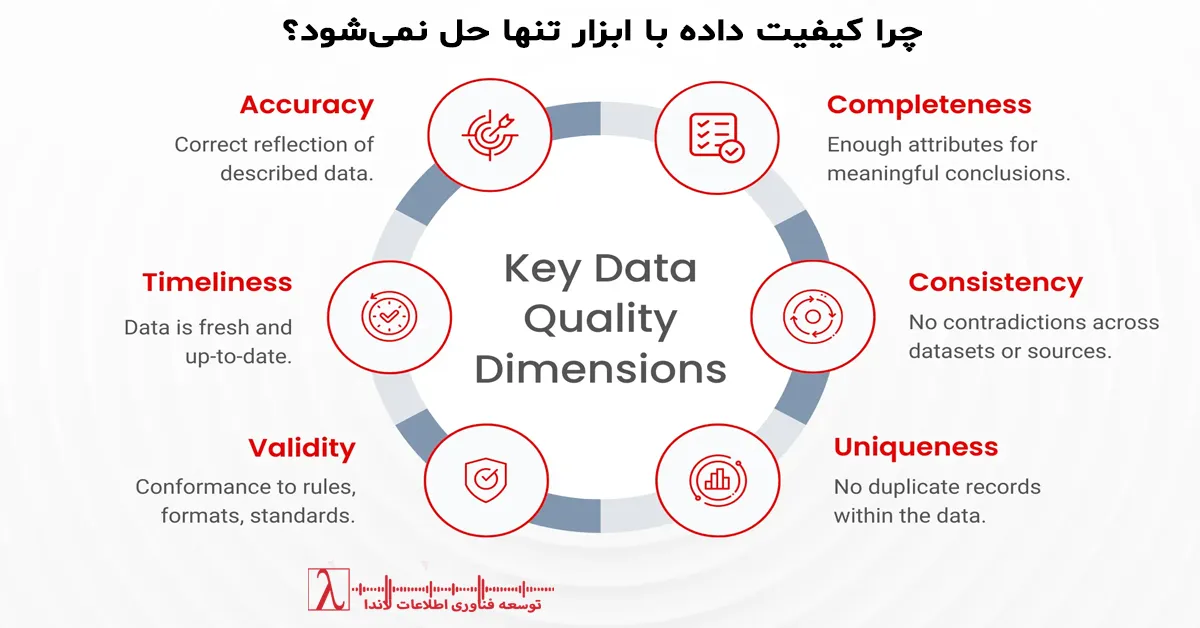
- تضمین کیفیت داده با تست و اعتبارسنجی
- ایجاد لایه متادیتا قوی برای جستجو و مدیریت بهتر
- یکپارچهسازی با ابزارهای BI مثل Power BI ،Tableau یا Looker
آینده Data Lakehouse و ترند BI
با توجه به رشد روزافزون دادههای چندفرمت و نیاز به پردازش سریع، Data Lakehouse نه تنها یک ترند BI در ۲۰۲۵ است، بلکه به استاندارد طلایی معماری داده برای سالهای آینده تبدیل خواهد شد. ترکیب آن با هوش مصنوعی، امکان ساخت سیستمهای تحلیلی پیشبینانه و بلادرنگ را بیش از پیش فراهم میکند.
سوالات متداول (FAQ)
۱. تفاوت Data Lakehouse با Data Lake چیست؟
Lakehouse علاوه بر ذخیره داده، قابلیتهای مدیریت متادیتا و بهینهسازی کوئری را هم دارد.
۲. آیا میتوان Lakehouse را روی ابر و محلی پیاده کرد؟
بله، هر دو امکانپذیر است.
۳. آیا Lakehouse جایگزین کامل Data Warehouse میشود؟
در بسیاری از سازمانها بله، اما ممکن است برای برخی سناریوهای خاص Data Warehouse حفظ شود.
تماس و مشاوره
سازمان خود را با معماری داده آینده مجهز کنید!
تیم توسعه فناوری اطلاعات لاندا آماده است تا از طراحی و پیادهسازی Data Lakehouse تا بهینهسازی کامل فرآیندهای BI، شما را همراهی کند.
همین حالا با ما تماس ✆ بگیرید و مشاوره رایگان دریافت کنید.
نظری داده نشده