 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید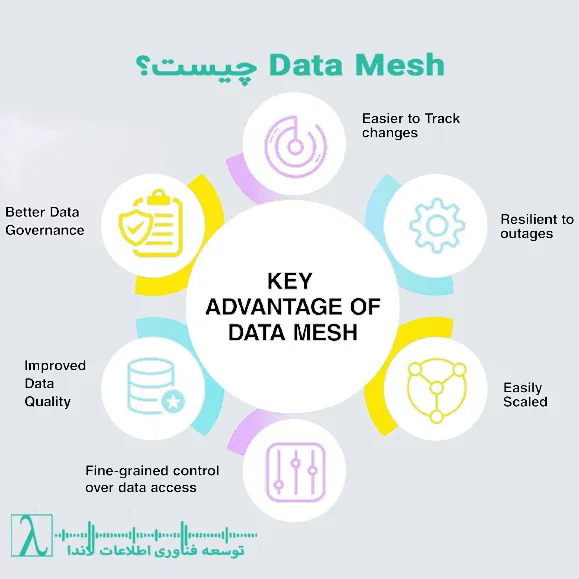
در دنیای امروز، داده به عنوان سرمایه اصلی هر سازمان شناخته میشود، اما روشهای سنتی مدیریت داده مثل Data Warehouse متمرکز یا Data Lake به تنهایی پاسخگوی نیازهای پیچیده سازمانهای مدرن نیستند. اینجاست که Data Mesh به عنوان یک معماری نوین داده مطرح میشود.
در سال ۲۰۲۵، معماری Data Mesh به یکی از مهمترین ترند BI و مهندسی داده تبدیل شده است، زیرا با رویکردی غیرمتمرکز، مالکیت داده را به تیمهای مختلف واگذار میکند و امکان مقیاسپذیری سریع را فراهم میآورد.
پیشرفت در فناوریهای ابری، هوش مصنوعی و تحلیل بلادرنگ (Real-time Analytics)، نیاز سازمانها به معماریهای داده مقیاسپذیر و قابل انعطاف را بیشتر از همیشه کرده است.
تعریف Data Mesh
یک رویکرد معماری داده است که برخلاف مدلهای متمرکز، مدیریت و مالکیت داده را به تیمهای مختلف در سازمان واگذار میکند. به جای یک تیم مرکزی که تمام دادهها را مدیریت کند، هر دامنه (Domain) یا واحد کسبوکار، مسئول دادههای خودش است.
چهار اصل کلیدی Data Mesh
- مالکیت داده بر اساس دامنه (Domain-oriented Ownership)
هر تیم کسبوکار مسئول دادههای خودش است. - داده به عنوان محصول (Data as a Product)
داده باید مثل یک محصول طراحی، نگهداری و عرضه شود. - زیرساخت سلفسرویس (Self-serve Data Infrastructure)
تیمها ابزار و پلتفرمهای لازم برای مدیریت داده را خودشان داشته باشند. - حاکمیت داده فدرال (Federated Data Governance)
قوانین و استانداردها به صورت مشترک تعریف و اجرا میشوند.
تفاوت Data Mesh با معماریهای قبلی
| ویژگی | Data Warehouse | Data Lake | Data Mesh |
|---|---|---|---|
| ساختار | متمرکز | متمرکز | غیرمتمرکز |
| مالکیت داده | تیم IT مرکزی | تیم IT مرکزی | هر دامنه |
| انعطافپذیری | کم | متوسط | زیاد |
| مقیاسپذیری | محدود | خوب | عالی |
| مناسب برای | سازمانهای کوچک تا متوسط | پروژههای داده حجیم | سازمانهای بزرگ و پیچیده |
مزایای Data Mesh
- مقیاسپذیری بالا: بدون گلوگاه تیم مرکزی.
- افزایش کیفیت داده: تیمهای دامنه دادههای خود را بهتر میشناسند.
- افزایش سرعت تحویل داده: تصمیمگیری سریعتر.
- انعطافپذیری: سازگار با ابزارها و فناوریهای مختلف.
چالشها و معایب
- نیاز به فرهنگسازی قوی در سازمان.
- هماهنگی بین تیمها ممکن است سخت باشد.
- نیاز به ابزارهای پیشرفته برای مدیریت و مانیتورینگ.
- احتمال ناسازگاری دادهها بین دامنهها.
ابزارها و فناوریهای پشتیبان
- Databricks برای Data Lakehouse
- Snowflake برای ذخیره و پردازش داده
- dbt برای مدلسازی داده
- Apache Kafka برای استریم داده
- Great Expectations برای تست کیفیت داده
سناریوی عملی پیادهسازی
فرض کنید یک شرکت خردهفروشی بینالمللی میخواهد Data Mesh را پیاده کند:
- تقسیم سازمان به دامنههای فروش، لجستیک، بازاریابی.
- تعریف مالکیت داده برای هر دامنه.
- انتخاب ابزارهای مناسب (Snowflake، Kafka، dbt).
- طراحی استانداردهای حاکمیت داده مشترک.
- اجرای پایلوت و سپس مقیاسگذاری در کل سازمان.
آینده Data Mesh به عنوان ترند BI
در سال ۲۰۲۵، Data Mesh با ترکیب شدن با هوش مصنوعی مولد (Generative AI)، تحلیل پیشبینانه و پلتفرمهای ابری هیبریدی به هسته اصلی استراتژی داده سازمانها تبدیل خواهد شد.
سوالات متداول (FAQ)
- آیا Data Mesh جایگزین Data Lake میشود؟
خیر، اغلب مکمل آن است. - برای پیادهسازی Data Mesh به چه مهارتهایی نیاز داریم؟
مهارتهای مهندسی داده، DevOps، و مدیریت محصول داده. - آیا برای سازمان کوچک مناسب است؟
بیشتر برای سازمانهای متوسط و بزرگ توصیه میشود.
اگر میخواهید معماری Data Mesh را در سازمان خود پیادهسازی کنید و از ترند BI 2025 عقب نمانید، همین حالا با تیم توسعه فناوری اطلاعات لاندا تماس بگیرید تا یک نقشه راه اختصاصی برای دادههای شما طراحی کنیم.
ارتباط و مشاوره
برای اطلاعات بیشتر و مشاوره میتوانید از طریق زیر با ما در ارتباط باشید:






نظری داده نشده