 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید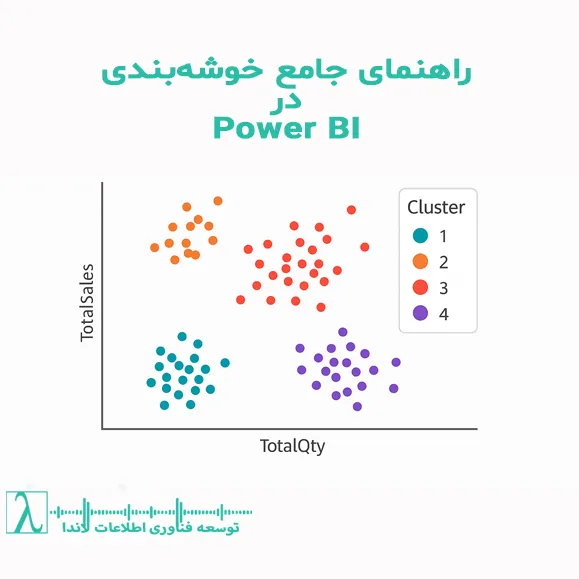
فناوری خوشهبندی (Clustering) در Power BI به شما کمک میکند تا الگوهای پنهان در دادهها را شناسایی، گروههای همگن از رکوردها بسازید و از آن برای تصمیمسازی هوشمند استفاده کنید.
خوشهبندی چیست؟
خوشهبندی یکی از روشهای بدون ناظر (Unsupervised Learning) در دادهکاوی است که رکوردهای مشابه را در یک گروه (کلاستر) قرار میدهد.
- هدف: کمینهسازی فاصلهٔ داخل هر خوشه و بیشینهسازی فاصلهٔ بین خوشهها
- کاربردها: تقسیمبندی مشتریان، تشخیص تقلب، تحلیل سبد خرید و …
مزایای خوشهبندی در Power BI
- بصریسازی آسان: با یک نمودار پراکندگی (Scatter)، خوشهها را میتوانید بهسرعت مشاهده کنید.
- بدون نیاز به مدلسازی پیچیده: ابزار داخلی Power BI امکان ساخت خوشه را با چند کلیک فراهم میکند.
- قابلیت بهروزرسانی لحظهای: هرگاه دادههای اولیه تغییر کند، خوشهها خودکار تازه میشوند.
- ترکیب با سایر بصریسازیها: میتوانید از خوشه بهعنوان فیلتر یا محور رنگ در داشبوردها استفاده کنید.
معایب خوشهبندی در Power BI
- انتخاب تعداد خوشه چالشی است: Power BI پیشنهاد عدد میدهد اما ممکن است همیشه بهینه نباشد.
- حساسیت به مقیاس متغیرها: قبل از خوشهبندی باید دادهها نرمالسازی یا استاندارد شوند.
- کدگذاری محدود قابل تنظیم: ابزار Built-in امکانات پیشرفته مثل وزندهی ویژگیها یا الگوریتمهای متنوع را ندارد.
- عدم توضیح علت خوشهبندی: خروجی صرفاً گروهبندی است و دلیل قرارگیری یک رکورد در خوشه باید جداگانه تحلیل شود.
مراحل پیادهسازی خوشهبندی در Power BI
- وارد کردن دادهها
- اتصال به دیتابیس AdventureWorksDW
- آمادهسازی دادهها
- انتخاب جدول
FactInternetSales - تعریف Measures:
- انتخاب جدول
TotalSales = SUM(FactInternetSales[SalesAmount])
TotalQty = SUM(FactInternetSales[OrderQuantity])
- ایجاد بصریسازی Scatter
- Axis X: [TotalQty]
- Axis Y: [TotalSales]
- Details: CustomerKey
- فعال کردن Clustering
- در منوی Visualizations، آیکون سهنقطه → “Analyze” → “Clustering”
- تعداد خوشه دلخواه یا اجازه دهید Power BI پیشنهاد دهد
- مرور نتایج
- رنگبندی شده بر اساس خوشه
- مشاهده مراکز خوشه (Cluster Centroids)
مثال عملی با دادههای AdventureWorksDW
ساخت Measures
TotalSales = SUM(FactInternetSales[SalesAmount])
TotalQty = SUM(FactInternetSales[OrderQuantity])
ایجاد نمودار Scatter
- در برگه گزارش (Report)، یک Scatter Chart اضافه کنید.
CustomerKeyرا در بخش Details قرار دهید.- Measureهای
TotalQtyوTotalSalesرا روی X و Y قرار دهید.
افزودن خوشهبندی
- روی Scatter کلیک راست → Analyze → Clustering
- تعداد خوشه را روی ۴ گذاشته و OK کنید
- در پنل Fields، ‘ClusterId’ اضافه میشود؛ رنگها بهصورت خودکار برای هر خوشه تخصیص مییابند.
تحلیل نتایج
- خوشه ۱: مشتریان با فروش بالا و تعداد سفارش بالا
- خوشه ۲: سفارشات کم ولی فروش متوسط
- …
چه زمانی از خوشهبندی استفاده کنیم؟
- تقسیمبندی مشتریان برای هدفمندسازی کمپینهای بازاریابی
- شناسایی الگوی خرید برای مدیریت موجودی
- تشخیص دادههای نابهنجار (Outliers) در ترکیب با الگوریتمهای دیگر
- تحلیل ریسک در بانکها و بیمه
چه زمانی از خوشهبندی استفاده نکنیم؟
- دادههای بسیار کم (زیر ۱۰۰ رکورد)
- وقتی هدف، پیشبینی برچسب (Label) مشخص است؛ در این حالت از رگرسیون یا دستهبندی استفاده کنید
- متغیرها عددی نیستند یا نیاز به پردازش متنی سنگین دارید
- اگر نیاز به الگوریتمهای پیچیده (DBSCAN ،OPTICS ،Gaussian Mixture) دارید.
چگونه میتوان خوشهبندی را در Power BI بهبود داد؟
برای بهبود عملکرد و دقت خوشهبندی در Power BI، میتوان چندین تکنیک کلیدی را به کار گرفت که هم تجربه تحلیلی بهتری فراهم میکند و هم تصمیمگیری مبتنی بر داده را تقویت میکند. در ادامه، روشهای موثر برای ارتقای خوشهبندی را مرور میکنیم:
پیشپردازش دادهها (Data Preprocessing)
- نرمالسازی متغیرها: الگوریتم خوشهبندی به مقیاس متغیرها حساس است. از Power Query برای Standardize یا Normalize کردن ستونهای عددی استفاده کنید.
- حذف دادههای پرت (Outliers): دادههای غیرعادی میتوانند مراکز خوشه را جابجا کنند.
- فیلتر کردن رکوردهای نویزی: رکوردهایی که اطلاعات ناقص یا غیرمعنادار دارند بهتر است حذف شوند.
انتخاب ویژگیهای بهینه (Feature Selection)
- فقط ویژگیهایی را وارد خوشهبندی کنید که معنای تحلیلی دارند.
- استفاده از KPIها یا مقادیر مشتقشده (مثل میانگین خرید، نرخ برگشت مشتری) بهجای داده خام میتواند خوشهبندی را دقیقتر کند.
تعیین تعداد مناسب خوشهها
- به جای اعتماد کامل به پیشنهاد Power BI، از روشهای مستقل استفاده کنید:
- Elbow Method: با نمودار واریانس در برابر تعداد خوشهها، عدد بهینه را بیابید.
- Silhouette Score: کیفیت جداسازی خوشهها را ارزیابی کنید (در Python/R قابل پیادهسازی است).
استفاده از اسکریپتهای Python یا R
اگر به الگوریتمهای پیشرفتهتر نیاز دارید، از Visualهای Python/R در Power BI استفاده کنید:
- الگوریتمهایی مانند K-Means++، DBSCAN یا Gaussian Mixture امکان شخصیسازی بالاتری دارند.
- میتوانید متغیرها را وزندهی کرده و تحلیلهای آماری دقیقتری داشته باشید.
تفسیر و اعتبارسنجی خوشهها
- از نمودارهای boxplot یا bar chart برای نمایش توزیع ویژگیها در هر خوشه استفاده کنید.
- برای هر خوشه «پروفایل» بسازید: ویژگیهای خاص آنها چیست و چه معنایی دارند؟
- بررسی کنید که آیا خوشهها منطبق با منطق کسبوکار هستند یا صرفاً آماری.
استفاده از Clustering بهعنوان فیلتر یا Segment
پس از ایجاد خوشهها:
- آنها را به عنوان Segment در Power BI تعریف کنید.
- در داشبورد اصلی، فیلترهای بر اساس خوشه قرار دهید تا تحلیلها شخصیسازی شوند.
الگوریتم K-Means چیست؟
K-Means یک الگوریتم بدون ناظر (Unsupervised) است که دادهها را به K خوشهبندی میکند، بهطوریکه اعضای هر خوشه بیشترین شباهت را به یکدیگر دارند و از اعضای خوشههای دیگر متمایز هستند.
مراحل اجرای الگوریتم K-Means
- انتخاب تعداد خوشهها (K)
- این عدد باید از قبل مشخص شود (مثلاً ۳ خوشه).
- انتخاب تصادفی مراکز اولیه خوشهها (Centroids)
- الگوریتم از K نقطه تصادفی بهعنوان مراکز اولیه شروع میکند.
- اختصاص هر داده به نزدیکترین مرکز خوشه
- با استفاده از فاصله اقلیدسی یا سایر معیارها.
- محاسبه مراکز جدید خوشهها
- میانگین نقاط هر خوشه محاسبه شده و مرکز جدید تعیین میشود.
- تکرار مراحل ۳ و ۴
- تا زمانی که مراکز خوشهها تغییر نکنند یا به حد آستانه برسند.
مثال ساده
فرض کنید دادههایی از مشتریان داریم با دو ویژگی:
- تعداد خرید
- مبلغ کل خرید
الگوریتم K-Means میتواند این مشتریان را به ۳ گروه خوشهبندی کند:
- مشتریان وفادار با خرید زیاد
- مشتریان کمخرید
- مشتریان با خریدهای گران ولی کمتعداد
مزایای K-Means
- ساده و سریع
- مقیاسپذیر برای دادههای بزرگ
- قابل پیادهسازی در ابزارهایی مثل Power BI ،Python ،R
معایب K-Means
- باید تعداد خوشهها را از قبل بدانید
- به مقیاس دادهها حساس است (نیاز به نرمالسازی)
- به نقاط اولیه حساس است (ممکن است در مینیمم محلی گیر کند)
- فقط برای دادههای عددی مناسب است
نکته حرفهای
برای بهبود عملکرد K-Means:
- از K-Means++ برای انتخاب مراکز اولیه بهتر استفاده کنید.
- از Elbow Method برای تعیین تعداد بهینه خوشهها بهره ببرید.
- دادهها را قبل از خوشهبندی نرمالسازی کنید.
نتیجهگیری
خوشهبندی در Power BI با ابزار داخلی، راهی سریع برای کشف گروههای پنهان در دادهها ارائه میدهد. هرچند امکانات سادهای دارد، میتواند نقطه شروعی عالی برای تحلیل عمیقتر باشد.
سوالات متداول (FAQ)
۱. هنگام خوشهبندی، چند خوشه باید انتخاب کنم؟
پیشنهاد میشود از Elbow Method یا Silhouette Score استفاده کنید، اما Power BI بصورت خودکار عددی بر اساس واریانس پیشنهاد میکند.
۲. آیا باید قبل از خوشهبندی نرمالسازی انجام دهم؟
بله، برای جلوگیری از تسلط متغیرهای با دامنه بزرگ بر الگوریتم، دادهها را استاندارد کنید.
۳. میتوانم خوشهبندی را خودکار در داشبورد اجرا کنم؟
هر بار که دادهها Refresh شوند، خوشهها نیز مجدداً محاسبه میشوند.
۴. تفاوت Clustering داخلی Power BI با Python/R چیست؟
ابزار داخلی ساده و بدون نیاز به کدنویسی است. اگر به الگوریتمهای تخصصی نیاز دارید، از Python/R Visual استفاده کنید.
پیشنهاد مطالعه
تماس و مشاوره با لاندا
برای اطلاعات بیشتر و مشاوره میتوانید از طریق زیر با توسعه فناوری اطلاعات لاندا در ارتباط باشید:




نظری داده نشده