 و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید و سپس «افزودن به صفحه اصلی» ضربه بزنید
و سپس «افزودن به صفحه اصلی» ضربه بزنید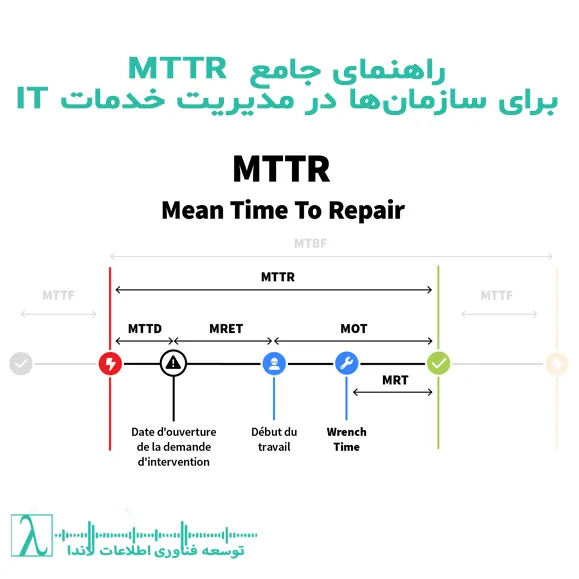
در دنیای فناوری اطلاعات، سازمانها بهطور روزافزون به شاخصهای کلیدی عملکرد (KPI) نیاز دارند تا بتوانند کیفیت خدمات خود را بسنجند، عملکرد تیمهای IT را ارزیابی کنند و رضایت مشتریان را افزایش دهند. یکی از مهمترین این شاخصها MTTR است.
نه تنها نشاندهنده سرعت تیم IT در واکنش به رخدادها و خرابیهاست، بلکه مستقیماً بر SLA، تجربه مشتری (CX) و حتی سودآوری سازمان تأثیر دارد.
در این مقاله از توسعه فناوری اطلاعات لاندا، بهطور کامل بررسی میکنیم که این شاخص چیست، چه انواعی دارد، چگونه محاسبه میشود، چرا اهمیت دارد و سازمانها چگونه میتوانند آن را بهبود دهند.
MTTR چیست؟
مخفف عبارتهای Mean Time to Repair / Recover / Resolve / Respond است که همگی به مدتزمان میانگین رفع رخداد یا بازگردانی سرویس اشاره دارند.
به زبان ساده:
این شاخص نشان میدهد از لحظهای که یک رخداد یا خرابی شناسایی میشود تا زمانی که سیستم دوباره به وضعیت پایدار برسد، بهطور میانگین چقدر طول میکشد.
انواع تفاوتهای آنها
بسته به سناریو، میتواند ۴ معنا داشته باشد:
Mean Time to Repair
- زمان میانگین لازم برای تعمیر یک جزء سختافزاری یا نرمافزاری.
- مثال: تعویض یک دیسک خراب در سرور.
Mean Time to Recover
- مدتزمان میانگین برای بازگرداندن سرویس به حالت عملیاتی پس از خرابی.
- مثال: ریاستارت کردن اپلیکیشن پس از Crash.
Mean Time to Resolve
- مدتزمان میانگین برای حل کامل مشکل و رفع علت ریشهای (RCA).
- مثال: رفع باگ نرمافزاری که منجر به Crash مکرر میشد.
Mean Time to Respond
- مدتزمان میانگین بین وقوع رخداد و آغاز واکنش تیم IT.
- مثال: فاصله بین آلارم مانیتورینگ و شروع تریاژ توسط تیم پشتیبانی.
فرمول محاسبه
فرمول عمومی:

مثال ساده:
- تعداد رخدادها: ۱۰
- کل زمان رفع رخدادها: ۲۰ ساعت
MTTR = (20 / 10) = 2 Hrs
یعنی بهطور میانگین تیم شما در هر رخداد، ۲ ساعت زمان صرف میکند.
چرا MTTR اهمیت دارد؟
شاخص کلیدی عملکرد در ITIL و ITSM
- ITIL Incident Management یکی از مهمترین فرآیندهایی است که با MTTR سنجیده میشود.
تضمین SLA (Service Level Agreement)
- SLAها معمولاً شامل حداکثر MTTR هستند.
افزایش رضایت مشتری (CSAT)
- هر چه MTTR پایینتر باشد، مشتری سریعتر سرویس خود را دریافت میکند.
کاهش هزینههای سازمان
- Downtime کمتر = بهرهوری بیشتر + درآمد بیشتر.
رقابتپذیری در بازار
- سازمانهایی با MTTR پایینتر تجربه کاربری بهتری ارائه میدهند.
عوامل تأثیرگذار بر MTTR
- کیفیت مانیتورینگ و Alerting
- ابزارهای هوشمند مثل Zabbix ،Prometheus ،Datadog.
- سطح مستندسازی و Knowledge Base
- وجود Runbookها و Wiki داخلی.
- فرهنگ سازمانی و همکاری تیمها
- تعامل DevOps و ITIL.
- مهارت و آموزش پرسنل IT
- آشنایی با ابزارها و سناریوهای بحران.
- اتوماسیون در رفع رخدادها
- استفاده از RPA و Self-Healing Systems.
تکنیکها و راهکارهای کاهش MTTR
- مانیتورینگ پیشرفته
- استفاده از سیستمهای Real-Time Monitoring و AIOps.
- اتوماسیون (Automation)
- اجرای Playbookها در Ansible یا Runbook Automation.
- Root Cause Analysis (RCA)
- تمرکز بر علت اصلی، نه رفع موقت.
- تست و شبیهسازی خرابی (Chaos Engineering)
- مشابه آنچه شرکت Netflix با Chaos Monkey انجام میدهد.
- تمرین تیمی (Incident Drill)
- شبیهسازی رخداد و تمرین واکنش سریع.
- بهبود فرآیندهای ITIL
- ارتباط Incident، Problem و Change Management.
ارتباط MTTR با سایر KPIها
- MTBF (Mean Time Between Failures): نشاندهنده پایداری سیستم.
- MTTA (Mean Time to Acknowledge): زمان پذیرش رخداد توسط تیم.
- MTTD (Mean Time to Detect): زمان تشخیص رخداد.
ترکیب این KPIها تصویر کاملی از سلامت IT به سازمان میدهد.
KPIهای پیشنهادی برای سازمانها
- MTTR هدفمند: کمتر از ۲ ساعت برای رخدادهای حیاتی.
- SLA Compliance: بالای ۹۵٪.
- Customer Satisfaction (CSAT): بالای ۸۵٪.
- First Call Resolution (FCR): بالای ۷۰٪ در Service Desk.
MTTR در ITIL و DevOps
- در ITIL شاخص اصلی در Incident و Problem Management.
- در DevOps شاخص کلیدی در DORA Metrics (چهار معیار اصلی DevOps).
MTTR پایین = تیم DevOps موفق.
چالشهای سازمانها در مدیریت
- عدم شفافیت فرآیندها.
- عدم وجود ابزار مانیتورینگ یکپارچه.
- تیمهای سیلویی (Siloed Teams).
- پیچیدگی محیطهای Multi-Cloud.
- مقاومت در برابر اتوماسیون.
نتیجهگیری
MTTR یکی از مهمترین شاخصهای عملکردی در ITIL ،ITSM و DevOps است. کاهش آن باعث افزایش رضایت مشتری، بهبود SLA و رشد کسبوکار میشود. سازمانهایی که میخواهند رقابتی بمانند باید روی مانیتورینگ، اتوماسیون، فرهنگ تیمی و RCA سرمایهگذاری کنند.
سوالات متداول (FAQ)
۱. MTTR چیست؟
شاخصی که میانگین زمان رفع رخداد یا بازگردانی سرویس را نشان میدهد.
۲. تفاوت MTTR با MTBF چیست؟
MTTR زمان رفع خرابی است، MTBF زمان بین دو خرابی متوالی.
۳. چطور MTTR را کاهش دهیم؟
با مانیتورینگ پیشرفته، اتوماسیون، RCA و بهبود فرآیندها.
۴. آیا MTTR فقط برای IT کاربرد دارد؟
خیر، در صنایع تولیدی، هوافضا و پزشکی هم استفاده میشود.
۵. مقدار ایدهآل آن چقدر است؟
وابسته به SLA، اما معمولاً کمتر از ۱ تا ۲ ساعت.
۶. آیا کاهش MTTR هزینه دارد؟
بله، اما ROI بالاست چون Downtime کمتر = درآمد بیشتر.
۷. نقش DevOps در کاهش MTTR چیست؟
DevOps با CI/CD و Automation باعث کاهش چشمگیر میشود.
۸. آیا MTTR در Cloud متفاوت است؟
بله، در Cloud معمولاً ابزارهای مانیتورینگ و Auto-Healing کمک میکنند مقدار کاهش یابد.
۹. MTTR در ITIL 4 چگونه تعریف شده؟
بهعنوان شاخص کلیدی در Value Streams و Incident Management.
۱۰. آیا میتوان MTTR را صفر کرد؟
خیر، اما میتوان آن را تا حد ممکن بهینه کرد.
مشاوره و تماس با لاندا
سازمان شما به دنبال کاهش Downtime و افزایش رضایت مشتریان است؟
تیم توسعه فناوری اطلاعات لاندا با تخصص در ITIL ،DevOps و مانیتورینگ پیشرفته آماده است تا با طراحی فرآیندها و ابزارهای مناسب، زمان پاسخگویی را در سازمان شما به حداقل برساند.
همین امروز با ما تماس ✆ بگیرید تا یک گام بزرگ در مسیر چابکی و پایداری IT بردارید.


نظری داده نشده